---
base_model:
- meta-llama/Llama-3.1-8B
datasets:
- MegaScience/MegaScience
language:
- en
license: llama3.1
metrics:
- accuracy
pipeline_tag: text-generation
library_name: transformers
tags:
- science
---
# [MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning](https://arxiv.org/abs/2507.16812)
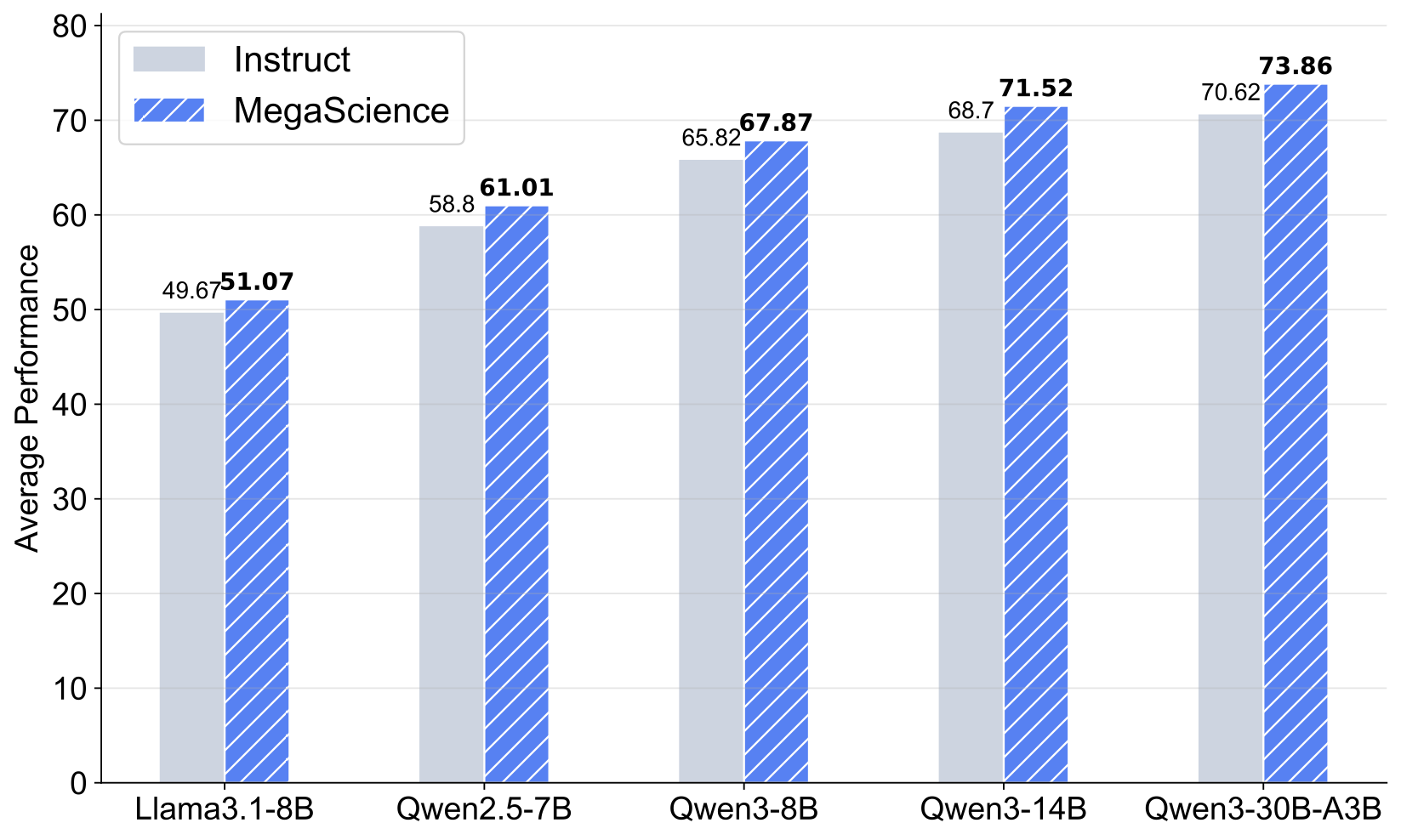
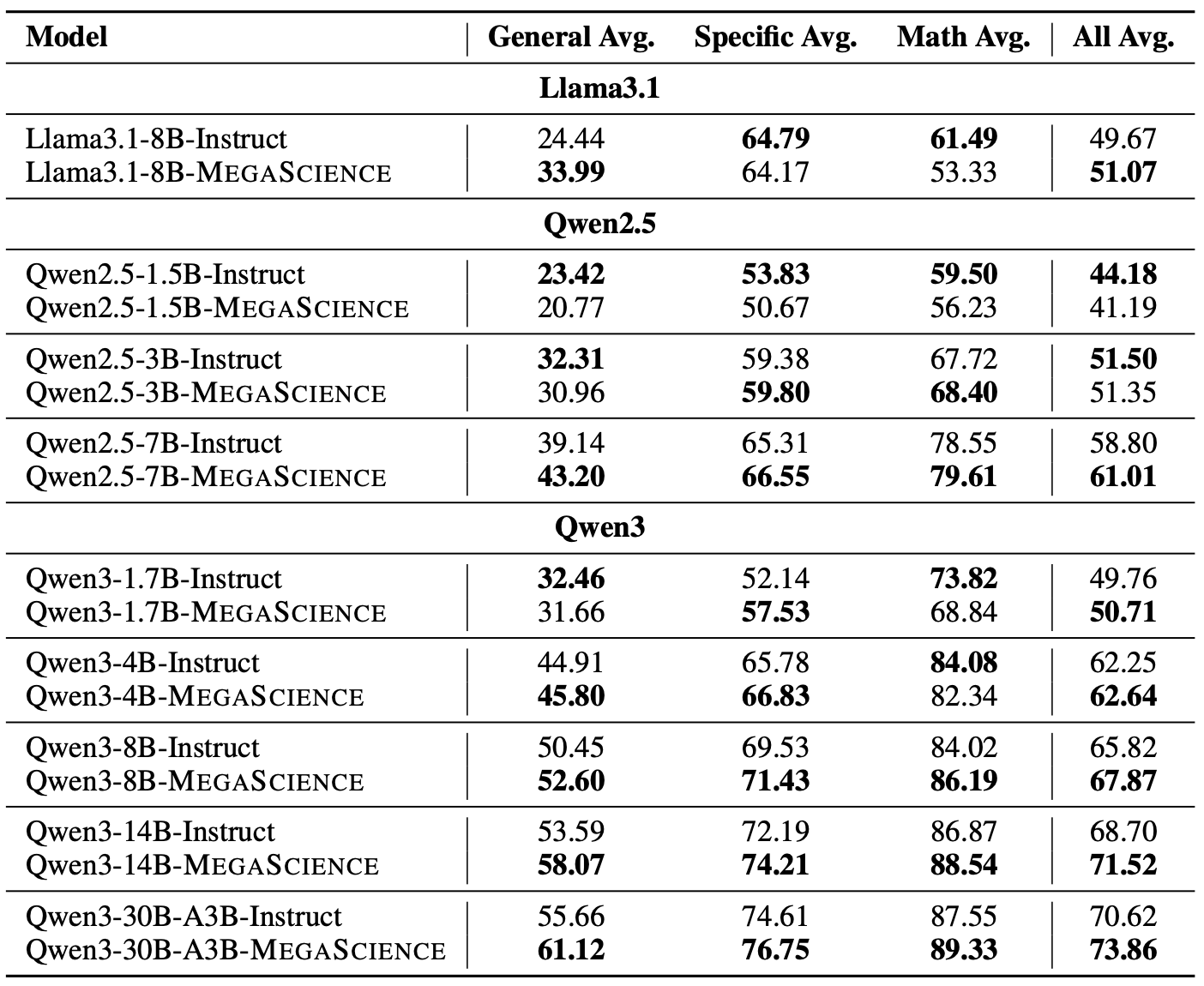
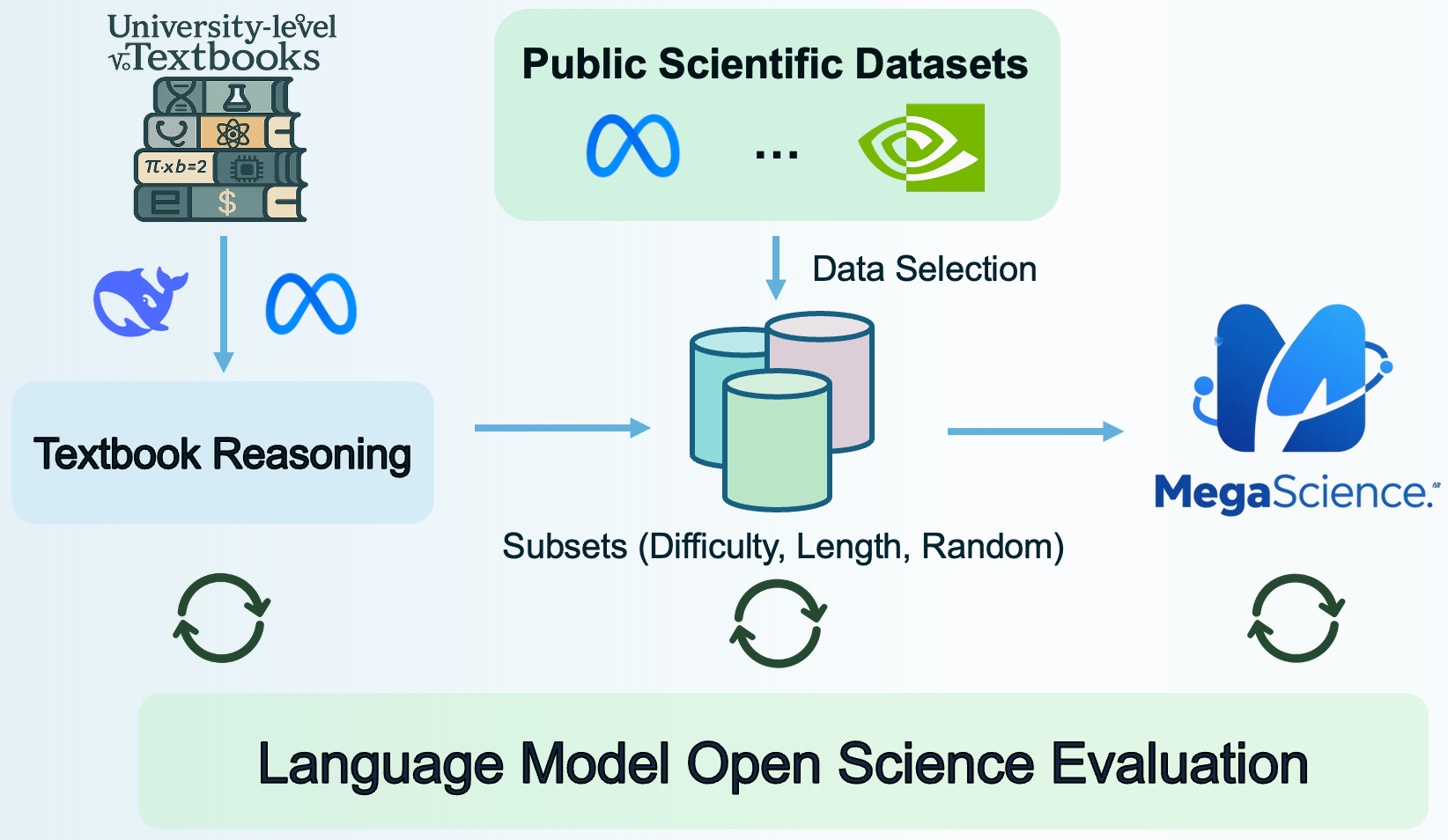
**Llama3.1-8B-MegaScience** is a model fine-tuned on **MegaScience**, a large-scale mixture of high-quality open-source scientific datasets totaling 1.25 million instances, as presented in the paper "MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning". The MegaScience dataset features truthful reference answers extracted from 12k university-level scientific textbooks, comprising 650k reasoning questions spanning 7 scientific disciplines. This model significantly outperforms corresponding official instruct models in average performance on scientific reasoning tasks and exhibits greater effectiveness for larger and stronger models, suggesting a scaling benefit for scientific tuning.
For more details on the project, including the data curation pipeline and evaluation system, visit the [official GitHub repository](https://github.com/GAIR-NLP/lm-open-science-evaluation).
## Llama3.1-8B-MegaScience
### Training Recipe
- **LR**: 5e-6
- **LR Schedule**: Cosine
- **Batch Size**: 512
- **Max Length**: 4,096
- **Warm Up Ratio**: 0.05
- **Epochs**: 3
### Evaluation Results
### More about MegaScience
### Usage
You can use the model with the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "MegaScience/Llama3.1-8B-MegaScience"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
messages = [
{"role": "user", "content": "Explain the concept of quantum entanglement."},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.7,
top_p=0.9
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
```
## Citation
Check out our [paper](https://arxiv.org/abs/2507.16812) for more details. If you use our dataset or find our work useful, please cite
```
@article{fan2025megascience,
title={MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning},
author={Fan, Run-Ze and Wang, Zengzhi and Liu, Pengfei},
year={2025},
journal={arXiv preprint arXiv:2507.16812},
url={https://arxiv.org/abs/2507.16812}
}
```