---
license: apache-2.0
datasets:
- Senqiao/VisionThink-Smart-Train
- Senqiao/VisionThink-Smart-Val
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
---
# VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
[](https://arxiv.org/abs/2507.13348)
[](https://huggingface.co/papers/2507.13348)
[](https://github.com/dvlab-research/VisionThink/blob/main/LICENSE)
 ## Senqiao/VisionThink-Efficient
This model is trained via reinforcement learning using [`Senqiao/VisionThink-Smart-Train`](https://huggingface.co/datasets/Senqiao/VisionThink-Smart-Train), demonstrating enhanced performance and efficiency on general VQA tasks.
**VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning [[Paper](https://arxiv.org/abs/2507.13348)]**
## Senqiao/VisionThink-Efficient
This model is trained via reinforcement learning using [`Senqiao/VisionThink-Smart-Train`](https://huggingface.co/datasets/Senqiao/VisionThink-Smart-Train), demonstrating enhanced performance and efficiency on general VQA tasks.
**VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning [[Paper](https://arxiv.org/abs/2507.13348)]**
[Senqiao Yang](https://scholar.google.com/citations?user=NcJc-RwAAAAJ),
[Junyi Li](https://scholar.google.com/citations?hl=zh-CN&user=zQ0P3JAAAAAJ),
[Xin Lai](https://scholar.google.com/citations?user=tqNDPA4AAAAJ),
[Bei Yu](https://scholar.google.com/citations?user=tGneTm4AAAAJ),
[Hengshuang Zhao](https://scholar.google.com/citations?user=4uE10I0AAAAJ),
[Jiaya Jia](https://scholar.google.com/citations?user=XPAkzTEAAAAJ)
## Highlights
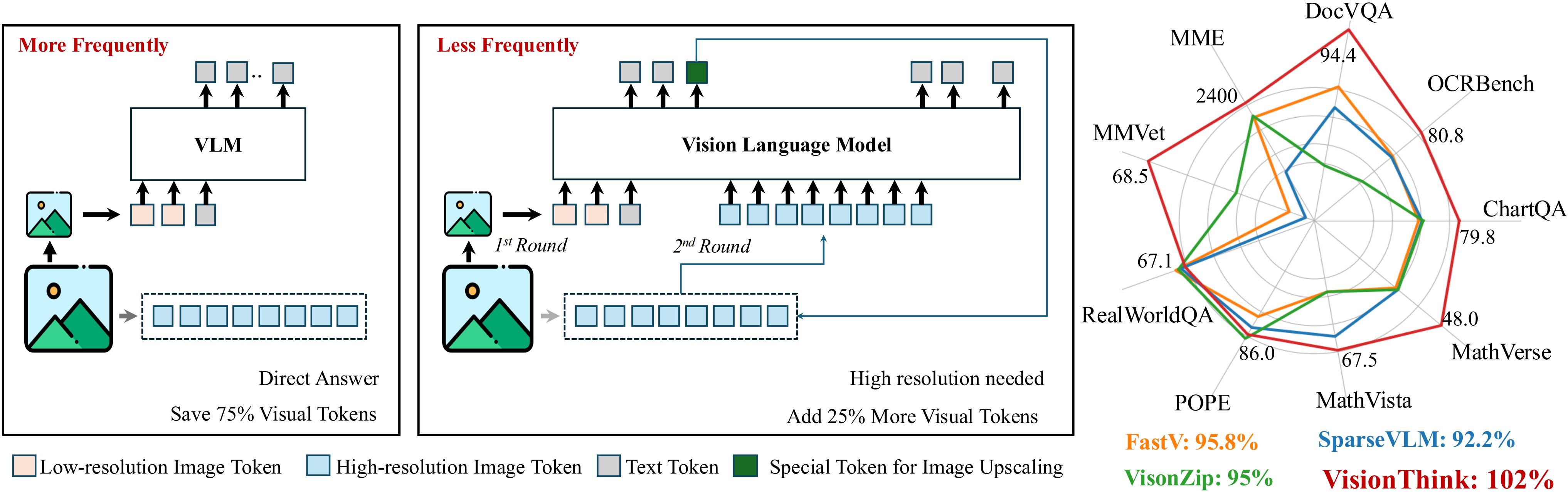
1. Our VisionThink leverages reinforcement learning to **autonomously** learn whether to reduce visual tokens. Compared to traditional efficient VLM approaches, our method achieves significant improvements on **fine-grained** benchmarks, such as those involving OCR-related tasks.
2. VisionThink improves performance on **General VQA** tasks while reducing visual tokens by **50%**, achieving **102%** of the original model’s performance across nine benchmarks.
3. VisionThink achieves strong performance and efficiency by simply resizing input images to reduce visual tokens. We hope this inspires further research into **Efficient Reasoning Vision Language Models**.
## Video

## Citation
If you find this project useful in your research, please consider citing:
> This work is highly motivated by our previous effort on efficient VLMs, [**VisionZip**](https://github.com/dvlab-research/VisionZip), which explores token compression for faster inference.
```
@article{yang2025visionthink,
title={VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning},
author={Yang, Senqiao and Li, Junyi and Lai, Xin and Yu, Bei and Zhao, Hengshuang and Jia, Jiaya},
journal={arXiv preprint arXiv:2507.13348},
year={2025}
}
@article{yang2024visionzip,
title={VisionZip: Longer is Better but Not Necessary in Vision Language Models},
author={Yang, Senqiao and Chen, Yukang and Tian, Zhuotao and Wang, Chengyao and Li, Jingyao and Yu, Bei and Jia, Jiaya},
journal={arXiv preprint arXiv:2412.04467},
year={2024}
}
```