

Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- es
|
| 6 |
+
- fr
|
| 7 |
+
- de
|
| 8 |
+
- it
|
| 9 |
+
- pt
|
| 10 |
+
- ru
|
| 11 |
+
- ar
|
| 12 |
+
- hi
|
| 13 |
+
- ko
|
| 14 |
+
- zh
|
| 15 |
+
library_name: transformers
|
| 16 |
+
extra_gated_prompt: Company name is optional, please put NA if you would prefer not to share it.
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
<div align="center">
|
| 20 |
+
<picture>
|
| 21 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/6435718aaaef013d1aec3b8b/Lj9YVLIKKdImV_jID0A1g.png" width="25%" alt="Arcee AFM 4.5B">
|
| 22 |
+
</picture>
|
| 23 |
+
</div>
|
| 24 |
+
|
| 25 |
+
# AFM-4.5B-Base-Pre-Anneal
|
| 26 |
+
|
| 27 |
+
**AFM-4.5B-Base-Pre-Anneal** is a 4.5 billion parameter instruction-tuned model developed by Arcee.ai, designed for enterprise-grade performance across diverse deployment environments from cloud to edge. The base model was trained on a dataset of 6.5 trillion tokens of general pretraining data. We use a modified version of [TorchTitan](https://arxiv.org/abs/2410.06511) for pretraining.
|
| 28 |
+
|
| 29 |
+
The development of AFM-4.5B prioritized data quality as a fundamental requirement for achieving robust model performance. We collaborated with DatologyAI, a company specializing in large-scale data curation. DatologyAI's curation pipeline integrates a suite of proprietary algorithms—model-based quality filtering, embedding-based curation, target distribution-matching, source mixing, and synthetic data. Their expertise enabled the creation of a curated dataset tailored to support strong real-world performance.
|
| 30 |
+
|
| 31 |
+
The model architecture follows a standard transformer decoder-only design based on Vaswani et al., incorporating several key modifications for enhanced performance and efficiency. Notable architectural features include grouped query attention for improved inference efficiency and ReLU^2 activation functions instead of SwiGLU to enable sparsification while maintaining or exceeding performance benchmarks.
|
| 32 |
+
|
| 33 |
+
The model available in this repo is the base model before it was annealed with math and code and before merging and context extension.
|
| 34 |
+
|
| 35 |
+
***
|
| 36 |
+
|
| 37 |
+
<div align="center">
|
| 38 |
+
<picture>
|
| 39 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/6435718aaaef013d1aec3b8b/sSVjGNHfrJKmQ6w8I18ek.png" style="background-color:ghostwhite;padding:5px;" width="17%" alt="Powered by Datology">
|
| 40 |
+
</picture>
|
| 41 |
+
</div>
|
| 42 |
+
|
| 43 |
+
## Model Details
|
| 44 |
+
|
| 45 |
+
* **Model Architecture:** ArceeForCausalLM
|
| 46 |
+
* **Parameters:** 4.5B
|
| 47 |
+
* **Training Tokens:** 6.5T - this model is pre-annealing with math and code and uses only the general dataset.
|
| 48 |
+
* **License:** [Apache-2.0](https://huggingface.co/arcee-ai/AFM-4.5B-Base#license)
|
| 49 |
+
|
| 50 |
+
***
|
| 51 |
+
|
| 52 |
+
## Benchmarks
|
| 53 |
+
|
| 54 |
+
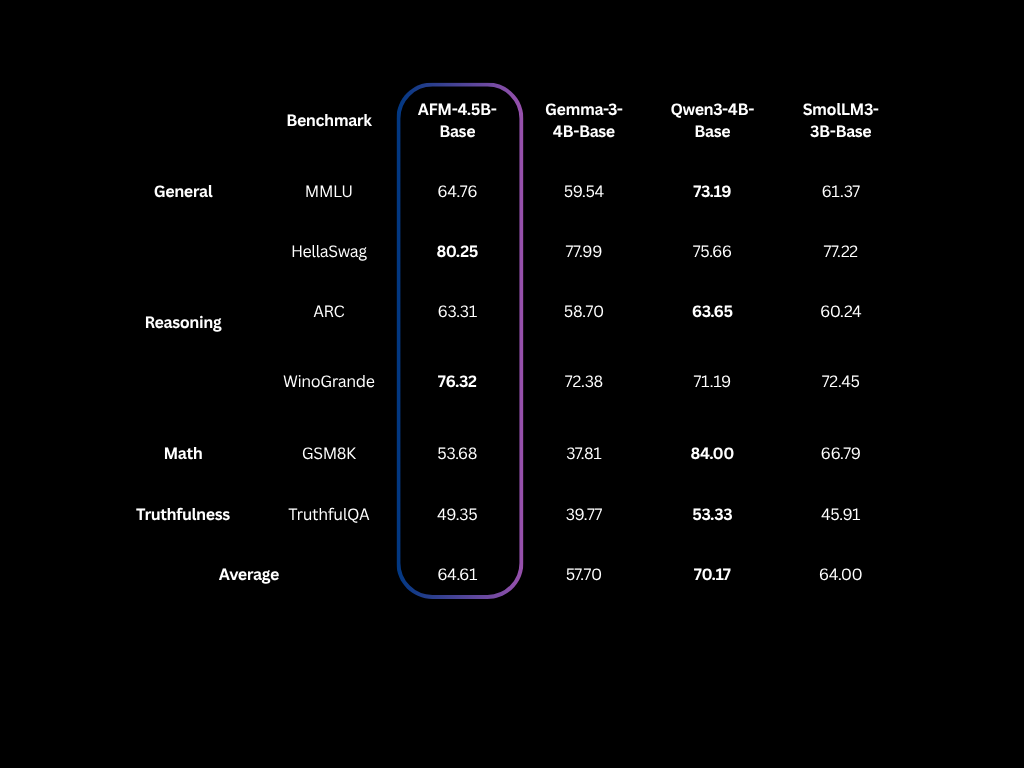
|
| 55 |
+
|
| 56 |
+
## How to use with `transformers`
|
| 57 |
+
|
| 58 |
+
You can use the model directly with the `transformers` library.
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 62 |
+
import torch
|
| 63 |
+
|
| 64 |
+
model_id = "arcee-ai/AFM-4.5B-Base-Pre-Anneal"
|
| 65 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 66 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 67 |
+
model_id,
|
| 68 |
+
torch_dtype=torch.bfloat16,
|
| 69 |
+
device_map="auto"
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
prompt = "Once upon a time "
|
| 73 |
+
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(model.device)
|
| 74 |
+
|
| 75 |
+
# Generate text
|
| 76 |
+
outputs = model.generate(
|
| 77 |
+
input_ids,
|
| 78 |
+
max_new_tokens=100,
|
| 79 |
+
do_sample=True,
|
| 80 |
+
temperature=0.7,
|
| 81 |
+
top_p=0.95
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
|
| 85 |
+
print(generated_text)
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
## License
|
| 89 |
+
|
| 90 |
+
AFM-4.5B is released under the Apache-2.0 license.
|