Image Diffusion On Fractal Text




There is traditionally a divide between models for vision and text — each with their own data formats, training tasks and architectures.
But what if text data could be represented visually, without losing its symbolic quality, to enable alternative approaches in text generation?
In this first article, we explore how text can be transformed into meaningful visual patterns to feed image diffusion models.
Intuition
From the point of view of computers, both texts and images are sequences of bytes.
Here's the start of the Huggingface logo, HEX encoded:
xxd -ps huggingface.png | head -n2
# 89504e470d0a1a0a0000000d4948445200000200000002000806000000f4
# 78d4fa000000097048597300001d8700001d87018fe5f165000000197445
And the start of this very web page, as it would appear on your hard drive:
xxd -ps blog.html | head -n2
# 3c21444f43545950452068746d6c3e0a3c212d2d2073617665642066726f
# 6d2075726c3d28303035382968747470733a2f2f68756767696e67666163
Unless you're trained in cybersecurity / forensics, good luck telling them apart!
Indeed, the "visual" versus "textual" distinction is human-centric. Images and text are constructs that wrap computer data for our convenience.
Of course, these formats capture a lot of underlying patterns and speed up the training of models. Much like tokenizers are frozen but effective shortcuts to semantic understanding.
But we have created two isolated and artificial islands.
So, let's see if we can go over the fence.
"Disclaimer"
Hijacking image models to produce text is a small experiment fueled by curiosity. I am aware that it is sub-optimal and ill-advised for serious projects.
Yet, generating text with diffusion architectures is gaining traction: Apple's Planner and Google's Gemini show promising results and challenge the status quo or autoregressive language models.
Table Of Contents
Encoding Text As RGB Data
To apply vision models to textual data, we first need to represent characters visually.
Rasterized Fonts
Usually, text is rasterized according to your screen's resolution.
But this approach breaks each character into many pixels, reducing discrete symbols to noisy textures:

It would force a model to recover symbolic meaning from visual fragments (pixels) — essentially learning to read.
Custom RGB Encoding
Instead, let's try and represent each character as a single pixel, preserving its identity while enabling spatial processing.
Typically, text is represented in the Unicode format, which is 32 bits long or 4 bytes.
Only a small portion of this space is allocated and the most significant byte is always zero:
np.array(list('Hilbert'.encode('utf-32-be'))).reshape((-1, 4))
# array([[ 0, 0, 0, 72],
# [ 0, 0, 0, 105],
# [ 0, 0, 0, 108],
# [ 0, 0, 0, 98],
# [ 0, 0, 0, 101],
# [ 0, 0, 0, 114],
# [ 0, 0, 0, 116]])
It means that any character can be represented by 3 bytes, much like the RGB compoenents of a color:

In the image above, each character is represented by a pixel with the color of its UTF encoding. The result is mostly blue because the red and green channels are null for all the ASCII characters.
Characters further along in the Unicode table, such as those from East Asian scripts (CJK characters), cover a wider range of colors:
np.array(list('ヒルベルト曲線'.encode('utf-32-be'))).reshape((-1, 4))
# array([[ 0, 0, 48, 210],
# [ 0, 0, 48, 235],
# [ 0, 0, 48, 217],
# [ 0, 0, 48, 235],
# [ 0, 0, 48, 200],
# [ 0, 0, 102, 242],
# [ 0, 0, 125, 218]])

Looking closely, the colors have a clear meaning:
- the punctuation is almost black because the associated codepoints are close to 0
- alphabets have distinct colors with more subtle variations from letter to letter
- uppercase letters are a deeper shade because they come before the lowercase in the UTF table
Mixing The Channels
Still, the colors are biased toward the blue, which may be unusual for a vision model.
To get a more balanced color distribution, the channels can be combined differently:
__utf = np.array(list('Hilbert'.encode('utf-32-be'))).reshape((-1, 4))
np.stack([
__utf[..., 1] + __utf[..., -1],
__utf[..., 2] + __utf[..., -1],
__utf[..., -1]
], axis=-1) % 256
# array([[ 72, 72, 72],
# [105, 105, 105],
# [108, 108, 108],
# [ 98, 98, 98],
# [101, 101, 101],
# [114, 114, 114],
# [116, 116, 116]])
This scheme maps western characters to a grayscale gradient of colors:

And it increases the contrast, at the cost of some discontinuity when rounding up to 256:

While alternative exist, this method offers a straightforward yet effective visual encoding.
For the rest of this article, text will be displayed both as characters and RGB pixels.
Shaping Text In 2D
To perform regular image diffusion, text data has to be reshaped in 2D while keeping the semantics.
The Ideal Case: ASCII Art
ASCII art is the closest text can get to rendering graphics:

Having a single pixel per character loses the shape of the glyphs, but the overall scene is still visible.
Much like regular text, a model can learn the underlying "meaning" and the relevant associations of characters.
The Regular Page Layout
Regular text is more tricky because LLMs view it as a 1D array.
Even though we read in a linear pattern, text is still written on 2D supports like this Wikipedia page:

The labels are shown in overlay for clarity, but keep in mind that a model will only see the pixel data.
This layout is very wasteful, with close to half the area covered by padding.
Also the attention on the height axis (in red) jumps from one sentence to the next, hardly capturing relevant patterns.
Ideally, all the data processed by a convolution kernel (in yellow) should be relevant to its main focus.
Fixed Size Chunking
Splitting text in fixed size chunks removes the empty area:

But the attention patterns are still broken and the height axis is irregular.
Folding Along The Hilbert Curve
A common solution to represent flat data in space is to fold the sequence on itself like a thread:

In the image above, the gradient of color represents the sequential index to highlight how the data is laid out in space.
The Hilbert curve shown above covers the whole 64 x 64 square with a line of length 4096.
This layout is especially interesting because it preserves locality on both axes. You can see that squares of different scales capture n-grams, sentences and sections:
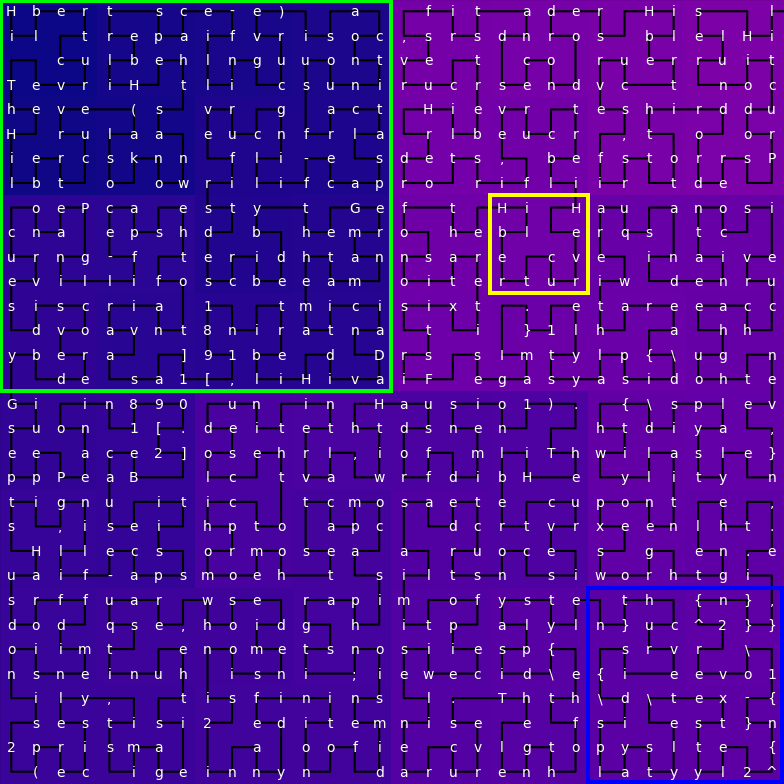
Instead of the blunt 1D attention, it is now possible to run convolution layers on this visual representation of text.
Similarly to the sliding window attention, the perceptive field grows with the depth of the layers. Convolutions start by processing words, then sentences, then sections, etc.
Alternative Space-Filling Curves
Instead of having a single character at each position along the curve, it is possible to place whole sequential blocks.
This hybrid layout is less convoluted and may strike a balance between locality and interpretability:
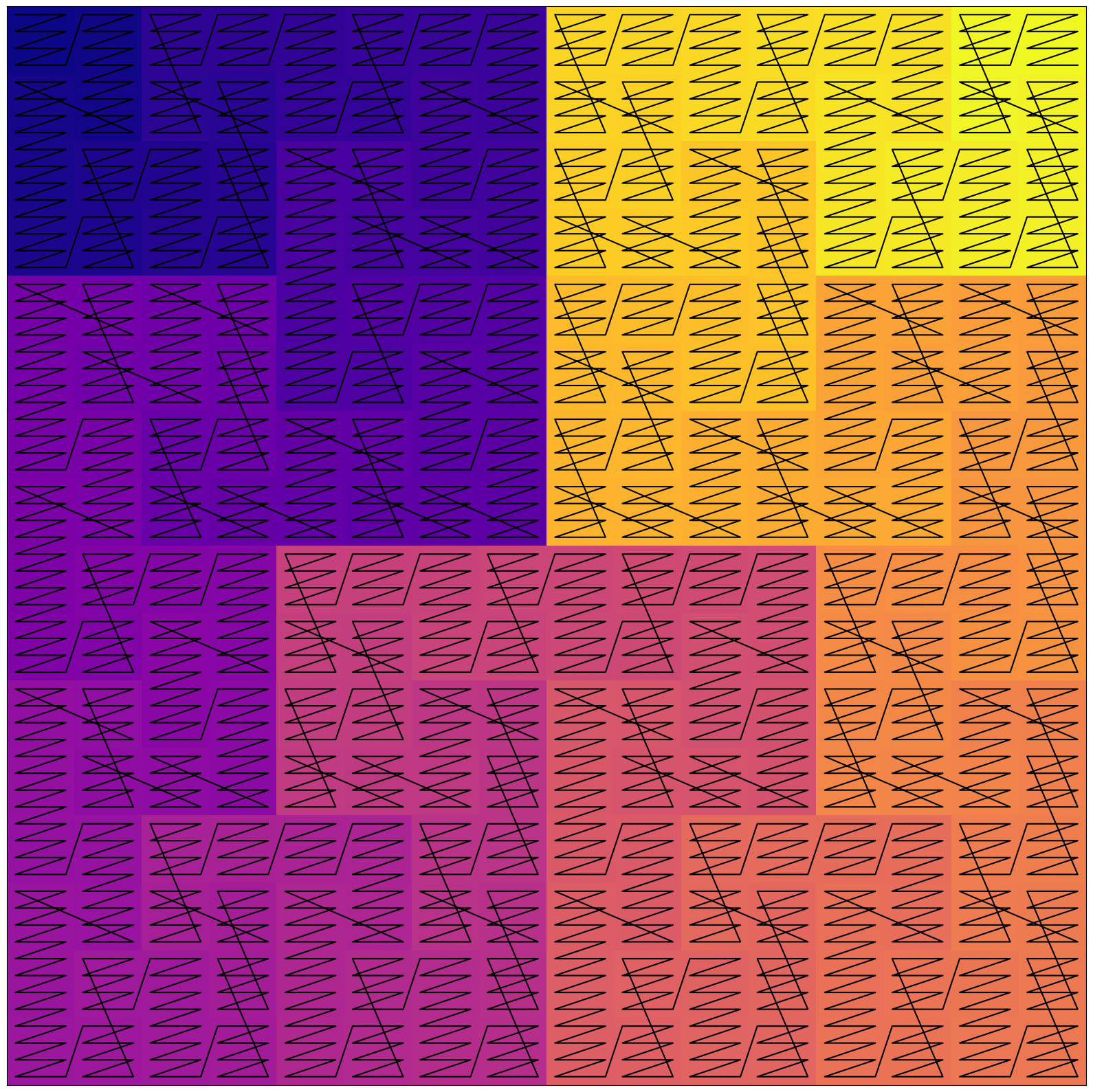
Actually, the Hilbert curve is one example of space-filling curve. These curves are used in many domains to map between 1D and 2D spaces:
- visualizing genomic data
- ordering database with indexes
- tracing objects to render textures
- mapping the space of IP addresses
- etc
Although the Hilbert curve does a better job of preserving locality, other curves might be easier to learn for a neural network. The simpler Z-order curve looks like a good candidate:

Still, you can see from the oblique lines that the curve has discontinuous jumps: at every scale, the end of one Z is not connected to the start of the next Z.
So, two points that were close in 1D are sometimes pulled apart in 2D.
Extending To Higher Dimensions
The 2D layout is practical to illustrate the concepts, but the Hilbert curve can be generalized to any rank:
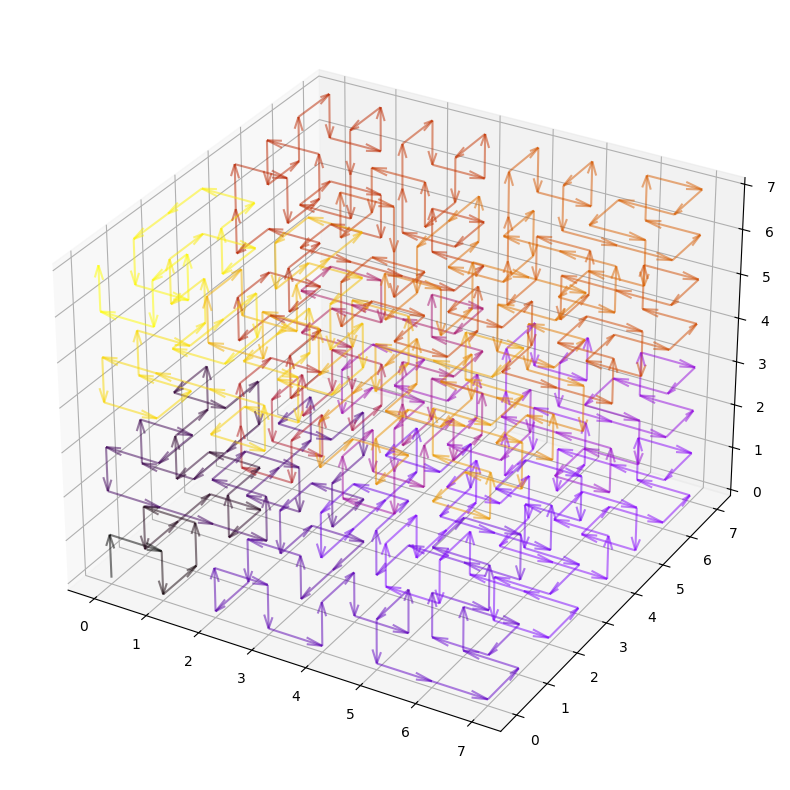
Which allows to encode a whole Wikipedia article as a cube of shape $16^{3}$:

Otherwise known as a sculk block in Minecraft!
While this is not relevant for using pretrained image diffusion models out of the box, it might be interesting for a custom text diffusion model.
Also, this scheme can be used with an additional axis to handle token level data rather than mere characters. Grouping the characters 4 by 4 at each position along the curve of rank 2 gives a token-level encoding:

And this encoding may very well be compressed by an auto-encoder since very few codepoints are actually used.
Considering a quantized auto-encoder, the 4 * 3 channels might be reduced to just 3.
Three (RGB) channels of depth 256 would allow to encode 16,777,216 different tokens, which by the standards of 2025 is more than enough.
Pushing The Analogy Further
Now that text data has been prepared exactly like image data, it can be fed directly to a diffusion model.
What will it mean to use the diffusion capabilities on text?
Upscaling Text
Just like an image, it is also possible to zoom on ASCII art:
| Zoomed Out | Zoomed In |
|---|---|
 |
 |
And the concept can be transposed to regular text too, even on flat sequences.
Upscaling can be leveraged to generate this very article in different ways:
- inpainting: filling a missing section of the article
- outpainting: creating the rest of the article from a specific section
- super-resolution: detailing a skeleton draft into a full-fledged article
Each of these operations can systematized into training tasks for text too.
Downscaling Text
It is less common for images, but the reverse operation could be interesting for text processing.
Downscaling would yield a summary or a segmentation of the article, like the table of contents.
Fractal Patterns
Interestingly, zooming can be done endlessly and it generates fractal patterns.
Below, a zoom on the notion of dimension in a 2D representation of a Wikipedia article:
| Text | RGB |
|---|---|
 |
 |
It is not exact, but the overall shape repeats itself infinitely. And this is not due to the Hilbert layout, it would be the same in 1D.
Indeed, text is fundamentally self-similar and recursive:
- words are defined by a collection of other words
- links can be expanded into whole web pages infinitely
- references in papers can be expanded into whole papers
- in Linux file systems, everything is a file:
- the file tree can be expanded and collapsed recursively
- in code, there is a very structured hierarchy:
- the syntax tree can be expanded and collapsed recursively
A given prompt could be summarized or expanded step by step, much like a multi-step CoT.
Instead of just training on the next token, the underlying structure could be parsed into several tasks.
For example, web pages, web sites and networks of sites have a logical partition of information. Training at different scales would be a path to refine the current training tasks without necessarily requiring to collect more data.
Other Applications
Many other capabilities of image models have direct text equivalents:
- denoising: correcting grammar, syntax, spelling, improving the style
- segmentation: structuring and summarizing long documents
- style transfer: rephrasing, changing the tone
Also, the litterature on image generation hints at potential benefits, for example:
- the receptive field of convolutional layers grows faster:
- the context grows with the square of the depth in convolutions
- versus a linear increase in the case of the sliding window
- the outputs of diffusion models are more coherent:
- the "first" tokens don't limit the paths available for later tokens
- the outputs are more fluent, with more diversity
- the gap between the sampling and the training processes is closing:
- Min-SNR differentiates the denoising stages and refines the sampling steps
- DREAM aligns the denoising algorithms of training with sampling
Next Up
These experiments show that multimodality is already rooted in the input data itself.
And it is very likely that text generation can benefit from the techniques of image generation.
We will see what actually happens when trying to apply and fine-tune image models on RGB text in a following article.
Resources
- ASCII art dataset
- ASCII image dataset
- Wikipedia article on the Hilbert curve
