What is the Hugging Face Community Building?







A Deep Dive into the Open Source AI Ecosystem
The narrative around AI development often centers on a handful of major players and their flagship large language models. But this view misses the rich, diverse ecosystem of innovation happening across thousands of organizations, researchers, and developers worldwide. The Hugging Face Hub offers a unique window into this broader trend — serving as the largest repository of AI models, datasets, and applications, capturing contributions from organizations with varying levels of openness and different approaches to AI development.
With over 1.8 million models, 450,000 datasets, and 560,000 applications hosted on the Hub, we have unprecedented visibility into who's building what in AI. Unlike other platforms that focus on specific domains or require particular licenses, the Hub captures the full spectrum of AI development: from completely open research to artifacts from major tech companies, from cutting-edge LLMs to specialized time-series models for specific industries.
Let's explore what this data reveals about the true state of AI development, the surprising diversity of contributions, and the research opportunities hiding in plain sight.
Exploring the Hub: What the Data Reveals
The Hub captures rich metadata on every model, dataset, and application: download counts, likes, user versus organization contributions, creation dates, and derivative relationships. While individual metrics like all-time downloads or recent likes tell part of the story, no single measure captures the full complexity of AI development patterns: a model with modest downloads might spawn hundreds of derivatives, or a dataset with few likes might be fundamental to entire research domains. To make sense of this complexity, we've built several analytical tools: the ModelVerse Explorer maps organizational contributions to model development, the DataVerse Explorer does the same for datasets, and the Organization HeatMap visualizes activity patterns across contributors over time.
The ModelVerse: A More Distributed Ecosystem Than You Think
The ModelVerse Explorer reveals fascinating patterns in model contributions across organizations. While the headlines focus on OpenAI, Google, and Anthropic, the data shows a much more distributed landscape:
Small models dominate downloads: Even when organizations release both large and small variants of the same model family, the smaller versions consistently see higher download numbers. This suggests practical deployment considerations often outweigh the pursuit of maximum capability.
Legacy models persist: GPT-2 and BERT remain among the most downloaded models despite being years old, showing that modern chat interfaces represent just one slice of AI application.
Rapid community response: Models like DeepSeek's recent releases can accumulate thousands of likes and forks within days of release, demonstrating the community's quick adoption of promising new approaches.

Very soon after its release, DeepSeek-R1 became the most liked model on Hugging Face.
The DataVerse: The Foundation Layer
The DataVerse Explorer tells an even more interesting story about the distributed nature of AI development:
Evaluation datasets rule: The most downloaded datasets of all time are evaluation benchmarks, reflecting the community's priority for rigorous testing and comparison.
Open actors dominate foundational data: While closed companies may train on proprietary data, the datasets that serve as the foundation for most AI development come from universities, research institutions, and open organizations.
Domain-specific specialization: Beyond the general-purpose datasets that make headlines, there's a thriving ecosystem of specialized datasets for finance, healthcare, robotics, and other domains.
Organization Activity: The Leading Contributors
The organization heatmap reveals which entities are contributing the most frequently on the Hub:
AI2 leads the pack: The Allen Institute for AI emerges as one of the most active contributors, demonstrating the continued importance of research institutions.
Big Tech's varied approaches: Companies like IBM, NVIDIA, and Apple show significant activity that might not be visible in mainstream AI discussions. Microsoft's presence through various research divisions adds another layer of complexity.
International diversity: Organizations from China, Europe, and other regions contribute significantly, highlighting AI's global nature.
What People Are Researching: Hidden Insights
The Hub is much more than just a repository — it is a living laboratory for AI research. Here are some research directions that become visible when you look beyond LLMs.
Domain-Specific Innovation
Time Series Models: Amazon and Salesforce lead in time series forecasting, with significant contributions from Monash University, HF's LeRobot team, and the AutoGluon project. This represents billions in economic value that rarely makes AI headlines.
Biology and Life Sciences: Cambridge, Microsoft Research, and numerous biotechnology startups are quietly building the models that may revolutionize drug discovery and biological research.
Robotics: Open-source robotics projects alongside NVIDIA's contributions are creating the foundation for the next generation of autonomous systems.
Audio and Speech: While OpenAI's Whisper gets attention, download patterns show strong preference for open alternatives in many applications.
Model Evolution and Derivatives
The model tree statistics space enables us to investigate how AI models evolve through community contributions via self-reported parent model tags:
- Organizations benefit differently from derivative works.
- Some models become platforms for innovation while others remain isolated.
- The most successful models, such as the Qwen, Llama, and Gemma models have spawned entire ecosystems of specialized variants.
For a more comprehensive analysis of multiple generations of models derived from a single model, check out the base model explorer space.
Research Opportunities
The data suggests several underexplored research directions:
Cross-domain transfer learning: With models spanning dozens of domains, there are opportunities to study how capabilities transfer between fields.
Collaborative development patterns: The derivative model networks reveal how distributed teams actually collaborate on AI development.
Long-term model viability: By tracking downloads and usage over time, we can understand which model architectures have staying power.
Resources for Deeper Exploration
Interactive Spaces
- Cumulative Hub Stats: Track growth trends over time!
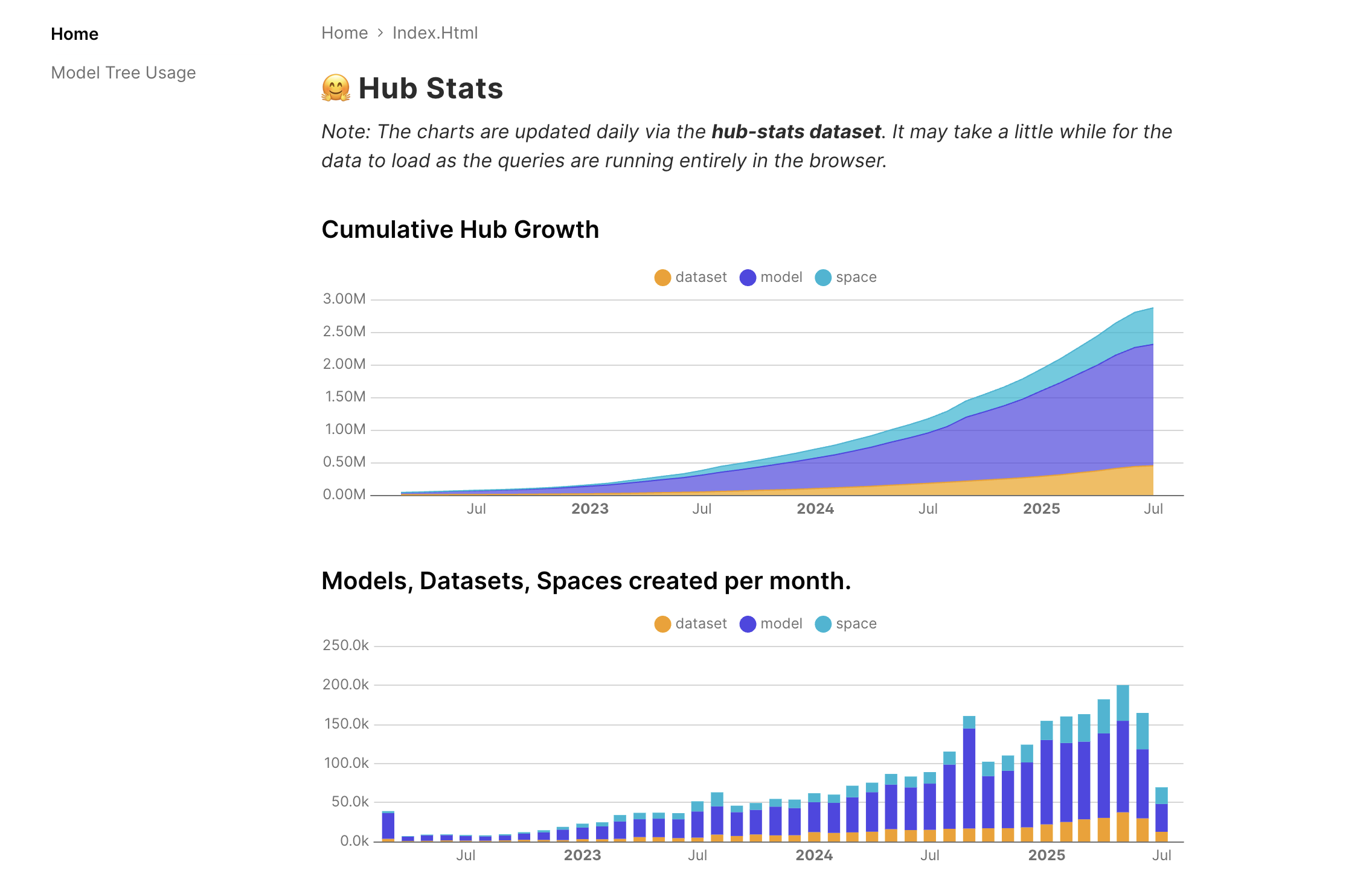
Cumulative Hub Stats space as of Jul 14, 2025
- Semantic Search: Explore models and datasets by capability using free text search!
- Model Atlas: Explore models and their relationships via an interactive graph visualization.
Research Datasets
For researchers wanting to dig deeper:
- Hub Statistics: Comprehensive stats dataset at https://huggingface.co/datasets/cfahlgren1/hub-stats
- Weekly Snapshots: Longitudinal data for trend analysis at https://huggingface.co/datasets/hfmlsoc/hub_weekly_snapshots
- Model Cards with Metadata: Structured model documentation at https://huggingface.co/datasets/librarian-bots/model_cards_with_metadata
- Dataset Cards with Metadata: Comprehensive dataset documentation at https://huggingface.co/datasets/librarian-bots/dataset_cards_with_metadata
Academic Research
Several academic papers have already begun using Hub data to understand AI development:
- "The Brief and Wondrous Life of Open Models"
- "The AI Community Building the Future? A Quantitative Analysis of Development Activity on Hugging Face Hub"
- "Systematic analysis of 32,111 AI model cards characterizes documentation practice in AI"
- "Navigating Dataset Documentations in AI: A Large-Scale Analysis of Dataset Cards on Hugging Face"
- "How do Machine Learning Models Change?"
- "Responsible AI in Open Ecosystems: Reconciling Innovation with Risk Assessment and Disclosure"
- "We Should Chart an Atlas of All the World’s Models"
Looking Forward: What This Means for AI
The data reveals that AI development is far more distributed, diverse, and collaborative than popular narratives suggest. While attention focuses on frontier models and billion-dollar companies, the real innovation often happens in specialized domains, through community collaboration, and via iterative improvement of existing models.
For researchers, this represents an opportunity to study AI development as it actually happens—not just as it's portrayed in press releases. For developers, it highlights the importance of looking beyond the latest model releases to find tools that actually solve real problems. For policymakers, it suggests that understanding AI's impact requires looking at the full ecosystem, not just the most visible players.
The Hub continues to evolve as a research platform, with new tools and datasets regularly added. Whether you're studying innovation patterns, analyzing model capabilities, or exploring the social dynamics of AI development, the data is here waiting to be explored.
What will you discover? We'd love to hear about exciting projects using Hub data! Explore the spaces and datasets mentioned above to start your own analysis and publish a paper or blog, or tag us on social media with what you find!



