Datasets:


Update README.md
Browse files- README.md +992 -3
- chart.png +3 -0
- scheme.png +3 -0
README.md
CHANGED
|
@@ -1,3 +1,992 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
dataset_info:
|
| 3 |
+
- config_name: Bulgarian
|
| 4 |
+
features:
|
| 5 |
+
- dtype: string
|
| 6 |
+
name: utt_id
|
| 7 |
+
- dtype:
|
| 8 |
+
audio:
|
| 9 |
+
sampling_rate: 16000
|
| 10 |
+
name: audio
|
| 11 |
+
- dtype: float64
|
| 12 |
+
name: duration
|
| 13 |
+
- dtype: string
|
| 14 |
+
name: lang
|
| 15 |
+
- dtype: string
|
| 16 |
+
name: task
|
| 17 |
+
- dtype: string
|
| 18 |
+
name: text
|
| 19 |
+
- dtype: string
|
| 20 |
+
name: translation_en
|
| 21 |
+
- dtype: string
|
| 22 |
+
name: original_audio_id
|
| 23 |
+
- dtype: float64
|
| 24 |
+
name: original_audio_offset
|
| 25 |
+
splits:
|
| 26 |
+
- name: asr_only
|
| 27 |
+
- name: ast
|
| 28 |
+
- config_name: Czech
|
| 29 |
+
features:
|
| 30 |
+
- dtype: string
|
| 31 |
+
name: utt_id
|
| 32 |
+
- dtype:
|
| 33 |
+
audio:
|
| 34 |
+
sampling_rate: 16000
|
| 35 |
+
name: audio
|
| 36 |
+
- dtype: float64
|
| 37 |
+
name: duration
|
| 38 |
+
- dtype: string
|
| 39 |
+
name: lang
|
| 40 |
+
- dtype: string
|
| 41 |
+
name: task
|
| 42 |
+
- dtype: string
|
| 43 |
+
name: text
|
| 44 |
+
- dtype: string
|
| 45 |
+
name: translation_en
|
| 46 |
+
- dtype: string
|
| 47 |
+
name: original_audio_id
|
| 48 |
+
- dtype: float64
|
| 49 |
+
name: original_audio_offset
|
| 50 |
+
splits:
|
| 51 |
+
- name: asr_only
|
| 52 |
+
- name: ast
|
| 53 |
+
- config_name: Danish
|
| 54 |
+
features:
|
| 55 |
+
- dtype: string
|
| 56 |
+
name: utt_id
|
| 57 |
+
- dtype:
|
| 58 |
+
audio:
|
| 59 |
+
sampling_rate: 16000
|
| 60 |
+
name: audio
|
| 61 |
+
- dtype: float64
|
| 62 |
+
name: duration
|
| 63 |
+
- dtype: string
|
| 64 |
+
name: lang
|
| 65 |
+
- dtype: string
|
| 66 |
+
name: task
|
| 67 |
+
- dtype: string
|
| 68 |
+
name: text
|
| 69 |
+
- dtype: string
|
| 70 |
+
name: translation_en
|
| 71 |
+
- dtype: string
|
| 72 |
+
name: original_audio_id
|
| 73 |
+
- dtype: float64
|
| 74 |
+
name: original_audio_offset
|
| 75 |
+
splits:
|
| 76 |
+
- name: asr_only
|
| 77 |
+
- name: ast
|
| 78 |
+
- config_name: German
|
| 79 |
+
features:
|
| 80 |
+
- dtype: string
|
| 81 |
+
name: utt_id
|
| 82 |
+
- dtype:
|
| 83 |
+
audio:
|
| 84 |
+
sampling_rate: 16000
|
| 85 |
+
name: audio
|
| 86 |
+
- dtype: float64
|
| 87 |
+
name: duration
|
| 88 |
+
- dtype: string
|
| 89 |
+
name: lang
|
| 90 |
+
- dtype: string
|
| 91 |
+
name: task
|
| 92 |
+
- dtype: string
|
| 93 |
+
name: text
|
| 94 |
+
- dtype: string
|
| 95 |
+
name: translation_en
|
| 96 |
+
- dtype: string
|
| 97 |
+
name: original_audio_id
|
| 98 |
+
- dtype: float64
|
| 99 |
+
name: original_audio_offset
|
| 100 |
+
splits:
|
| 101 |
+
- name: asr_only
|
| 102 |
+
- name: ast
|
| 103 |
+
- config_name: Greek
|
| 104 |
+
features:
|
| 105 |
+
- dtype: string
|
| 106 |
+
name: utt_id
|
| 107 |
+
- dtype:
|
| 108 |
+
audio:
|
| 109 |
+
sampling_rate: 16000
|
| 110 |
+
name: audio
|
| 111 |
+
- dtype: float64
|
| 112 |
+
name: duration
|
| 113 |
+
- dtype: string
|
| 114 |
+
name: lang
|
| 115 |
+
- dtype: string
|
| 116 |
+
name: task
|
| 117 |
+
- dtype: string
|
| 118 |
+
name: text
|
| 119 |
+
- dtype: string
|
| 120 |
+
name: translation_en
|
| 121 |
+
- dtype: string
|
| 122 |
+
name: original_audio_id
|
| 123 |
+
- dtype: float64
|
| 124 |
+
name: original_audio_offset
|
| 125 |
+
splits:
|
| 126 |
+
- name: asr_only
|
| 127 |
+
- name: ast
|
| 128 |
+
- config_name: English
|
| 129 |
+
features:
|
| 130 |
+
- dtype: string
|
| 131 |
+
name: utt_id
|
| 132 |
+
- dtype:
|
| 133 |
+
audio:
|
| 134 |
+
sampling_rate: 16000
|
| 135 |
+
name: audio
|
| 136 |
+
- dtype: float64
|
| 137 |
+
name: duration
|
| 138 |
+
- dtype: string
|
| 139 |
+
name: lang
|
| 140 |
+
- dtype: string
|
| 141 |
+
name: task
|
| 142 |
+
- dtype: string
|
| 143 |
+
name: text
|
| 144 |
+
- dtype: string
|
| 145 |
+
name: translation_en
|
| 146 |
+
- dtype: string
|
| 147 |
+
name: original_audio_id
|
| 148 |
+
- dtype: float64
|
| 149 |
+
name: original_audio_offset
|
| 150 |
+
splits:
|
| 151 |
+
- name: asr_only
|
| 152 |
+
- config_name: Spanish
|
| 153 |
+
features:
|
| 154 |
+
- dtype: string
|
| 155 |
+
name: utt_id
|
| 156 |
+
- dtype:
|
| 157 |
+
audio:
|
| 158 |
+
sampling_rate: 16000
|
| 159 |
+
name: audio
|
| 160 |
+
- dtype: float64
|
| 161 |
+
name: duration
|
| 162 |
+
- dtype: string
|
| 163 |
+
name: lang
|
| 164 |
+
- dtype: string
|
| 165 |
+
name: task
|
| 166 |
+
- dtype: string
|
| 167 |
+
name: text
|
| 168 |
+
- dtype: string
|
| 169 |
+
name: translation_en
|
| 170 |
+
- dtype: string
|
| 171 |
+
name: original_audio_id
|
| 172 |
+
- dtype: float64
|
| 173 |
+
name: original_audio_offset
|
| 174 |
+
splits:
|
| 175 |
+
- name: asr_only
|
| 176 |
+
- name: ast
|
| 177 |
+
- config_name: Estonian
|
| 178 |
+
features:
|
| 179 |
+
- dtype: string
|
| 180 |
+
name: utt_id
|
| 181 |
+
- dtype:
|
| 182 |
+
audio:
|
| 183 |
+
sampling_rate: 16000
|
| 184 |
+
name: audio
|
| 185 |
+
- dtype: float64
|
| 186 |
+
name: duration
|
| 187 |
+
- dtype: string
|
| 188 |
+
name: lang
|
| 189 |
+
- dtype: string
|
| 190 |
+
name: task
|
| 191 |
+
- dtype: string
|
| 192 |
+
name: text
|
| 193 |
+
- dtype: string
|
| 194 |
+
name: translation_en
|
| 195 |
+
- dtype: string
|
| 196 |
+
name: original_audio_id
|
| 197 |
+
- dtype: float64
|
| 198 |
+
name: original_audio_offset
|
| 199 |
+
splits:
|
| 200 |
+
- name: asr_only
|
| 201 |
+
- name: ast
|
| 202 |
+
- config_name: Finnish
|
| 203 |
+
features:
|
| 204 |
+
- dtype: string
|
| 205 |
+
name: utt_id
|
| 206 |
+
- dtype:
|
| 207 |
+
audio:
|
| 208 |
+
sampling_rate: 16000
|
| 209 |
+
name: audio
|
| 210 |
+
- dtype: float64
|
| 211 |
+
name: duration
|
| 212 |
+
- dtype: string
|
| 213 |
+
name: lang
|
| 214 |
+
- dtype: string
|
| 215 |
+
name: task
|
| 216 |
+
- dtype: string
|
| 217 |
+
name: text
|
| 218 |
+
- dtype: string
|
| 219 |
+
name: translation_en
|
| 220 |
+
- dtype: string
|
| 221 |
+
name: original_audio_id
|
| 222 |
+
- dtype: float64
|
| 223 |
+
name: original_audio_offset
|
| 224 |
+
splits:
|
| 225 |
+
- name: asr_only
|
| 226 |
+
- name: ast
|
| 227 |
+
- config_name: French
|
| 228 |
+
features:
|
| 229 |
+
- dtype: string
|
| 230 |
+
name: utt_id
|
| 231 |
+
- dtype:
|
| 232 |
+
audio:
|
| 233 |
+
sampling_rate: 16000
|
| 234 |
+
name: audio
|
| 235 |
+
- dtype: float64
|
| 236 |
+
name: duration
|
| 237 |
+
- dtype: string
|
| 238 |
+
name: lang
|
| 239 |
+
- dtype: string
|
| 240 |
+
name: task
|
| 241 |
+
- dtype: string
|
| 242 |
+
name: text
|
| 243 |
+
- dtype: string
|
| 244 |
+
name: translation_en
|
| 245 |
+
- dtype: string
|
| 246 |
+
name: original_audio_id
|
| 247 |
+
- dtype: float64
|
| 248 |
+
name: original_audio_offset
|
| 249 |
+
splits:
|
| 250 |
+
- name: asr_only
|
| 251 |
+
- name: ast
|
| 252 |
+
- config_name: Croatian
|
| 253 |
+
features:
|
| 254 |
+
- dtype: string
|
| 255 |
+
name: utt_id
|
| 256 |
+
- dtype:
|
| 257 |
+
audio:
|
| 258 |
+
sampling_rate: 16000
|
| 259 |
+
name: audio
|
| 260 |
+
- dtype: float64
|
| 261 |
+
name: duration
|
| 262 |
+
- dtype: string
|
| 263 |
+
name: lang
|
| 264 |
+
- dtype: string
|
| 265 |
+
name: task
|
| 266 |
+
- dtype: string
|
| 267 |
+
name: text
|
| 268 |
+
- dtype: string
|
| 269 |
+
name: translation_en
|
| 270 |
+
- dtype: string
|
| 271 |
+
name: original_audio_id
|
| 272 |
+
- dtype: float64
|
| 273 |
+
name: original_audio_offset
|
| 274 |
+
splits:
|
| 275 |
+
- name: asr_only
|
| 276 |
+
- name: ast
|
| 277 |
+
- config_name: Hungarian
|
| 278 |
+
features:
|
| 279 |
+
- dtype: string
|
| 280 |
+
name: utt_id
|
| 281 |
+
- dtype:
|
| 282 |
+
audio:
|
| 283 |
+
sampling_rate: 16000
|
| 284 |
+
name: audio
|
| 285 |
+
- dtype: float64
|
| 286 |
+
name: duration
|
| 287 |
+
- dtype: string
|
| 288 |
+
name: lang
|
| 289 |
+
- dtype: string
|
| 290 |
+
name: task
|
| 291 |
+
- dtype: string
|
| 292 |
+
name: text
|
| 293 |
+
- dtype: string
|
| 294 |
+
name: translation_en
|
| 295 |
+
- dtype: string
|
| 296 |
+
name: original_audio_id
|
| 297 |
+
- dtype: float64
|
| 298 |
+
name: original_audio_offset
|
| 299 |
+
splits:
|
| 300 |
+
- name: asr_only
|
| 301 |
+
- name: ast
|
| 302 |
+
- config_name: Italian
|
| 303 |
+
features:
|
| 304 |
+
- dtype: string
|
| 305 |
+
name: utt_id
|
| 306 |
+
- dtype:
|
| 307 |
+
audio:
|
| 308 |
+
sampling_rate: 16000
|
| 309 |
+
name: audio
|
| 310 |
+
- dtype: float64
|
| 311 |
+
name: duration
|
| 312 |
+
- dtype: string
|
| 313 |
+
name: lang
|
| 314 |
+
- dtype: string
|
| 315 |
+
name: task
|
| 316 |
+
- dtype: string
|
| 317 |
+
name: text
|
| 318 |
+
- dtype: string
|
| 319 |
+
name: translation_en
|
| 320 |
+
- dtype: string
|
| 321 |
+
name: original_audio_id
|
| 322 |
+
- dtype: float64
|
| 323 |
+
name: original_audio_offset
|
| 324 |
+
splits:
|
| 325 |
+
- name: asr_only
|
| 326 |
+
- name: ast
|
| 327 |
+
- config_name: Lithuanian
|
| 328 |
+
features:
|
| 329 |
+
- dtype: string
|
| 330 |
+
name: utt_id
|
| 331 |
+
- dtype:
|
| 332 |
+
audio:
|
| 333 |
+
sampling_rate: 16000
|
| 334 |
+
name: audio
|
| 335 |
+
- dtype: float64
|
| 336 |
+
name: duration
|
| 337 |
+
- dtype: string
|
| 338 |
+
name: lang
|
| 339 |
+
- dtype: string
|
| 340 |
+
name: task
|
| 341 |
+
- dtype: string
|
| 342 |
+
name: text
|
| 343 |
+
- dtype: string
|
| 344 |
+
name: translation_en
|
| 345 |
+
- dtype: string
|
| 346 |
+
name: original_audio_id
|
| 347 |
+
- dtype: float64
|
| 348 |
+
name: original_audio_offset
|
| 349 |
+
splits:
|
| 350 |
+
- name: asr_only
|
| 351 |
+
- name: ast
|
| 352 |
+
- config_name: Latvian
|
| 353 |
+
features:
|
| 354 |
+
- dtype: string
|
| 355 |
+
name: utt_id
|
| 356 |
+
- dtype:
|
| 357 |
+
audio:
|
| 358 |
+
sampling_rate: 16000
|
| 359 |
+
name: audio
|
| 360 |
+
- dtype: float64
|
| 361 |
+
name: duration
|
| 362 |
+
- dtype: string
|
| 363 |
+
name: lang
|
| 364 |
+
- dtype: string
|
| 365 |
+
name: task
|
| 366 |
+
- dtype: string
|
| 367 |
+
name: text
|
| 368 |
+
- dtype: string
|
| 369 |
+
name: translation_en
|
| 370 |
+
- dtype: string
|
| 371 |
+
name: original_audio_id
|
| 372 |
+
- dtype: float64
|
| 373 |
+
name: original_audio_offset
|
| 374 |
+
splits:
|
| 375 |
+
- name: asr_only
|
| 376 |
+
- name: ast
|
| 377 |
+
- config_name: Dutch
|
| 378 |
+
features:
|
| 379 |
+
- dtype: string
|
| 380 |
+
name: utt_id
|
| 381 |
+
- dtype:
|
| 382 |
+
audio:
|
| 383 |
+
sampling_rate: 16000
|
| 384 |
+
name: audio
|
| 385 |
+
- dtype: float64
|
| 386 |
+
name: duration
|
| 387 |
+
- dtype: string
|
| 388 |
+
name: lang
|
| 389 |
+
- dtype: string
|
| 390 |
+
name: task
|
| 391 |
+
- dtype: string
|
| 392 |
+
name: text
|
| 393 |
+
- dtype: string
|
| 394 |
+
name: translation_en
|
| 395 |
+
- dtype: string
|
| 396 |
+
name: original_audio_id
|
| 397 |
+
- dtype: float64
|
| 398 |
+
name: original_audio_offset
|
| 399 |
+
splits:
|
| 400 |
+
- name: asr_only
|
| 401 |
+
- name: ast
|
| 402 |
+
- config_name: Polish
|
| 403 |
+
features:
|
| 404 |
+
- dtype: string
|
| 405 |
+
name: utt_id
|
| 406 |
+
- dtype:
|
| 407 |
+
audio:
|
| 408 |
+
sampling_rate: 16000
|
| 409 |
+
name: audio
|
| 410 |
+
- dtype: float64
|
| 411 |
+
name: duration
|
| 412 |
+
- dtype: string
|
| 413 |
+
name: lang
|
| 414 |
+
- dtype: string
|
| 415 |
+
name: task
|
| 416 |
+
- dtype: string
|
| 417 |
+
name: text
|
| 418 |
+
- dtype: string
|
| 419 |
+
name: translation_en
|
| 420 |
+
- dtype: string
|
| 421 |
+
name: original_audio_id
|
| 422 |
+
- dtype: float64
|
| 423 |
+
name: original_audio_offset
|
| 424 |
+
splits:
|
| 425 |
+
- name: asr_only
|
| 426 |
+
- name: ast
|
| 427 |
+
- config_name: Portuguese
|
| 428 |
+
features:
|
| 429 |
+
- dtype: string
|
| 430 |
+
name: utt_id
|
| 431 |
+
- dtype:
|
| 432 |
+
audio:
|
| 433 |
+
sampling_rate: 16000
|
| 434 |
+
name: audio
|
| 435 |
+
- dtype: float64
|
| 436 |
+
name: duration
|
| 437 |
+
- dtype: string
|
| 438 |
+
name: lang
|
| 439 |
+
- dtype: string
|
| 440 |
+
name: task
|
| 441 |
+
- dtype: string
|
| 442 |
+
name: text
|
| 443 |
+
- dtype: string
|
| 444 |
+
name: translation_en
|
| 445 |
+
- dtype: string
|
| 446 |
+
name: original_audio_id
|
| 447 |
+
- dtype: float64
|
| 448 |
+
name: original_audio_offset
|
| 449 |
+
splits:
|
| 450 |
+
- name: asr_only
|
| 451 |
+
- name: ast
|
| 452 |
+
- config_name: Romanian
|
| 453 |
+
features:
|
| 454 |
+
- dtype: string
|
| 455 |
+
name: utt_id
|
| 456 |
+
- dtype:
|
| 457 |
+
audio:
|
| 458 |
+
sampling_rate: 16000
|
| 459 |
+
name: audio
|
| 460 |
+
- dtype: float64
|
| 461 |
+
name: duration
|
| 462 |
+
- dtype: string
|
| 463 |
+
name: lang
|
| 464 |
+
- dtype: string
|
| 465 |
+
name: task
|
| 466 |
+
- dtype: string
|
| 467 |
+
name: text
|
| 468 |
+
- dtype: string
|
| 469 |
+
name: translation_en
|
| 470 |
+
- dtype: string
|
| 471 |
+
name: original_audio_id
|
| 472 |
+
- dtype: float64
|
| 473 |
+
name: original_audio_offset
|
| 474 |
+
splits:
|
| 475 |
+
- name: asr_only
|
| 476 |
+
- name: ast
|
| 477 |
+
- config_name: Russian
|
| 478 |
+
features:
|
| 479 |
+
- dtype: string
|
| 480 |
+
name: utt_id
|
| 481 |
+
- dtype:
|
| 482 |
+
audio:
|
| 483 |
+
sampling_rate: 16000
|
| 484 |
+
name: audio
|
| 485 |
+
- dtype: float64
|
| 486 |
+
name: duration
|
| 487 |
+
- dtype: string
|
| 488 |
+
name: lang
|
| 489 |
+
- dtype: string
|
| 490 |
+
name: task
|
| 491 |
+
- dtype: string
|
| 492 |
+
name: text
|
| 493 |
+
- dtype: string
|
| 494 |
+
name: translation_en
|
| 495 |
+
- dtype: string
|
| 496 |
+
name: original_audio_id
|
| 497 |
+
- dtype: float64
|
| 498 |
+
name: original_audio_offset
|
| 499 |
+
splits:
|
| 500 |
+
- name: asr_only
|
| 501 |
+
- name: ast
|
| 502 |
+
- config_name: Slovak
|
| 503 |
+
features:
|
| 504 |
+
- dtype: string
|
| 505 |
+
name: utt_id
|
| 506 |
+
- dtype:
|
| 507 |
+
audio:
|
| 508 |
+
sampling_rate: 16000
|
| 509 |
+
name: audio
|
| 510 |
+
- dtype: float64
|
| 511 |
+
name: duration
|
| 512 |
+
- dtype: string
|
| 513 |
+
name: lang
|
| 514 |
+
- dtype: string
|
| 515 |
+
name: task
|
| 516 |
+
- dtype: string
|
| 517 |
+
name: text
|
| 518 |
+
- dtype: string
|
| 519 |
+
name: translation_en
|
| 520 |
+
- dtype: string
|
| 521 |
+
name: original_audio_id
|
| 522 |
+
- dtype: float64
|
| 523 |
+
name: original_audio_offset
|
| 524 |
+
splits:
|
| 525 |
+
- name: asr_only
|
| 526 |
+
- name: ast
|
| 527 |
+
- config_name: Swedish
|
| 528 |
+
features:
|
| 529 |
+
- dtype: string
|
| 530 |
+
name: utt_id
|
| 531 |
+
- dtype:
|
| 532 |
+
audio:
|
| 533 |
+
sampling_rate: 16000
|
| 534 |
+
name: audio
|
| 535 |
+
- dtype: float64
|
| 536 |
+
name: duration
|
| 537 |
+
- dtype: string
|
| 538 |
+
name: lang
|
| 539 |
+
- dtype: string
|
| 540 |
+
name: task
|
| 541 |
+
- dtype: string
|
| 542 |
+
name: text
|
| 543 |
+
- dtype: string
|
| 544 |
+
name: translation_en
|
| 545 |
+
- dtype: string
|
| 546 |
+
name: original_audio_id
|
| 547 |
+
- dtype: float64
|
| 548 |
+
name: original_audio_offset
|
| 549 |
+
splits:
|
| 550 |
+
- name: asr_only
|
| 551 |
+
- name: ast
|
| 552 |
+
- config_name: Ukrainian
|
| 553 |
+
features:
|
| 554 |
+
- dtype: string
|
| 555 |
+
name: utt_id
|
| 556 |
+
- dtype:
|
| 557 |
+
audio:
|
| 558 |
+
sampling_rate: 16000
|
| 559 |
+
name: audio
|
| 560 |
+
- dtype: float64
|
| 561 |
+
name: duration
|
| 562 |
+
- dtype: string
|
| 563 |
+
name: lang
|
| 564 |
+
- dtype: string
|
| 565 |
+
name: task
|
| 566 |
+
- dtype: string
|
| 567 |
+
name: text
|
| 568 |
+
- dtype: string
|
| 569 |
+
name: translation_en
|
| 570 |
+
- dtype: string
|
| 571 |
+
name: original_audio_id
|
| 572 |
+
- dtype: float64
|
| 573 |
+
name: original_audio_offset
|
| 574 |
+
splits:
|
| 575 |
+
- name: asr_only
|
| 576 |
+
- name: ast
|
| 577 |
+
- config_name: All
|
| 578 |
+
features:
|
| 579 |
+
- dtype: string
|
| 580 |
+
name: utt_id
|
| 581 |
+
- dtype:
|
| 582 |
+
audio:
|
| 583 |
+
sampling_rate: 16000
|
| 584 |
+
name: audio
|
| 585 |
+
- dtype: float64
|
| 586 |
+
name: duration
|
| 587 |
+
- dtype: string
|
| 588 |
+
name: lang
|
| 589 |
+
- dtype: string
|
| 590 |
+
name: task
|
| 591 |
+
- dtype: string
|
| 592 |
+
name: text
|
| 593 |
+
- dtype: string
|
| 594 |
+
name: translation_en
|
| 595 |
+
- dtype: string
|
| 596 |
+
name: original_audio_id
|
| 597 |
+
- dtype: float64
|
| 598 |
+
name: original_audio_offset
|
| 599 |
+
splits:
|
| 600 |
+
- name: asr_only
|
| 601 |
+
- name: ast
|
| 602 |
+
configs:
|
| 603 |
+
- config_name: Bulgarian
|
| 604 |
+
data_files:
|
| 605 |
+
- path: data/bg*/asr_only/*.parquet
|
| 606 |
+
split: asr_only
|
| 607 |
+
- path: data/bg*/ast/*.parquet
|
| 608 |
+
split: ast
|
| 609 |
+
- config_name: Czech
|
| 610 |
+
data_files:
|
| 611 |
+
- path: data/cs*/asr_only/*.parquet
|
| 612 |
+
split: asr_only
|
| 613 |
+
- path: data/cs*/ast/*.parquet
|
| 614 |
+
split: ast
|
| 615 |
+
- config_name: Danish
|
| 616 |
+
data_files:
|
| 617 |
+
- path: data/da*/asr_only/*.parquet
|
| 618 |
+
split: asr_only
|
| 619 |
+
- path: data/da*/ast/*.parquet
|
| 620 |
+
split: ast
|
| 621 |
+
- config_name: German
|
| 622 |
+
data_files:
|
| 623 |
+
- path: data/de*/asr_only/*.parquet
|
| 624 |
+
split: asr_only
|
| 625 |
+
- path: data/de*/ast/*.parquet
|
| 626 |
+
split: ast
|
| 627 |
+
- config_name: Greek
|
| 628 |
+
data_files:
|
| 629 |
+
- path: data/el*/asr_only/*.parquet
|
| 630 |
+
split: asr_only
|
| 631 |
+
- path: data/el*/ast/*.parquet
|
| 632 |
+
split: ast
|
| 633 |
+
- config_name: English
|
| 634 |
+
data_files:
|
| 635 |
+
- path: data/en*/asr_only/*.parquet
|
| 636 |
+
split: asr_only
|
| 637 |
+
- config_name: Spanish
|
| 638 |
+
data_files:
|
| 639 |
+
- path: data/es*/asr_only/*.parquet
|
| 640 |
+
split: asr_only
|
| 641 |
+
- path: data/es*/ast/*.parquet
|
| 642 |
+
split: ast
|
| 643 |
+
- config_name: Estonian
|
| 644 |
+
data_files:
|
| 645 |
+
- path: data/et*/asr_only/*.parquet
|
| 646 |
+
split: asr_only
|
| 647 |
+
- path: data/et*/ast/*.parquet
|
| 648 |
+
split: ast
|
| 649 |
+
- config_name: Finnish
|
| 650 |
+
data_files:
|
| 651 |
+
- path: data/fi*/asr_only/*.parquet
|
| 652 |
+
split: asr_only
|
| 653 |
+
- path: data/fi*/ast/*.parquet
|
| 654 |
+
split: ast
|
| 655 |
+
- config_name: French
|
| 656 |
+
data_files:
|
| 657 |
+
- path: data/fr*/asr_only/*.parquet
|
| 658 |
+
split: asr_only
|
| 659 |
+
- path: data/fr*/ast/*.parquet
|
| 660 |
+
split: ast
|
| 661 |
+
- config_name: Croatian
|
| 662 |
+
data_files:
|
| 663 |
+
- path: data/hr*/asr_only/*.parquet
|
| 664 |
+
split: asr_only
|
| 665 |
+
- path: data/hr*/ast/*.parquet
|
| 666 |
+
split: ast
|
| 667 |
+
- config_name: Hungarian
|
| 668 |
+
data_files:
|
| 669 |
+
- path: data/hu*/asr_only/*.parquet
|
| 670 |
+
split: asr_only
|
| 671 |
+
- path: data/hu*/ast/*.parquet
|
| 672 |
+
split: ast
|
| 673 |
+
- config_name: Italian
|
| 674 |
+
data_files:
|
| 675 |
+
- path: data/it*/asr_only/*.parquet
|
| 676 |
+
split: asr_only
|
| 677 |
+
- path: data/it*/ast/*.parquet
|
| 678 |
+
split: ast
|
| 679 |
+
- config_name: Lithuanian
|
| 680 |
+
data_files:
|
| 681 |
+
- path: data/lt*/asr_only/*.parquet
|
| 682 |
+
split: asr_only
|
| 683 |
+
- path: data/lt*/ast/*.parquet
|
| 684 |
+
split: ast
|
| 685 |
+
- config_name: Latvian
|
| 686 |
+
data_files:
|
| 687 |
+
- path: data/lv*/asr_only/*.parquet
|
| 688 |
+
split: asr_only
|
| 689 |
+
- path: data/lv*/ast/*.parquet
|
| 690 |
+
split: ast
|
| 691 |
+
- config_name: Dutch
|
| 692 |
+
data_files:
|
| 693 |
+
- path: data/nl*/asr_only/*.parquet
|
| 694 |
+
split: asr_only
|
| 695 |
+
- path: data/nl*/ast/*.parquet
|
| 696 |
+
split: ast
|
| 697 |
+
- config_name: Polish
|
| 698 |
+
data_files:
|
| 699 |
+
- path: data/pl*/asr_only/*.parquet
|
| 700 |
+
split: asr_only
|
| 701 |
+
- path: data/pl*/ast/*.parquet
|
| 702 |
+
split: ast
|
| 703 |
+
- config_name: Portuguese
|
| 704 |
+
data_files:
|
| 705 |
+
- path: data/pt*/asr_only/*.parquet
|
| 706 |
+
split: asr_only
|
| 707 |
+
- path: data/pt*/ast/*.parquet
|
| 708 |
+
split: ast
|
| 709 |
+
- config_name: Romanian
|
| 710 |
+
data_files:
|
| 711 |
+
- path: data/ro*/asr_only/*.parquet
|
| 712 |
+
split: asr_only
|
| 713 |
+
- path: data/ro*/ast/*.parquet
|
| 714 |
+
split: ast
|
| 715 |
+
- config_name: Russian
|
| 716 |
+
data_files:
|
| 717 |
+
- path: data/ru*/asr_only/*.parquet
|
| 718 |
+
split: asr_only
|
| 719 |
+
- path: data/ru*/ast/*.parquet
|
| 720 |
+
split: ast
|
| 721 |
+
- config_name: Slovak
|
| 722 |
+
data_files:
|
| 723 |
+
- path: data/sk*/asr_only/*.parquet
|
| 724 |
+
split: asr_only
|
| 725 |
+
- path: data/sk*/ast/*.parquet
|
| 726 |
+
split: ast
|
| 727 |
+
- config_name: Swedish
|
| 728 |
+
data_files:
|
| 729 |
+
- path: data/sv*/asr_only/*.parquet
|
| 730 |
+
split: asr_only
|
| 731 |
+
- path: data/sv*/ast/*.parquet
|
| 732 |
+
split: ast
|
| 733 |
+
- config_name: Ukrainian
|
| 734 |
+
data_files:
|
| 735 |
+
- path: data/uk*/asr_only/*.parquet
|
| 736 |
+
split: asr_only
|
| 737 |
+
- path: data/uk*/ast/*.parquet
|
| 738 |
+
split: ast
|
| 739 |
+
- config_name: All
|
| 740 |
+
default: true
|
| 741 |
+
data_files:
|
| 742 |
+
- path: data/*/asr_only/*.parquet
|
| 743 |
+
split: asr_only
|
| 744 |
+
- path: data/*/ast/*.parquet
|
| 745 |
+
split: ast
|
| 746 |
+
license: cc-by-3.0
|
| 747 |
+
task_categories:
|
| 748 |
+
- automatic-speech-recognition
|
| 749 |
+
- translation
|
| 750 |
+
language:
|
| 751 |
+
- bg
|
| 752 |
+
- cs
|
| 753 |
+
- da
|
| 754 |
+
- de
|
| 755 |
+
- el
|
| 756 |
+
- en
|
| 757 |
+
- es
|
| 758 |
+
- et
|
| 759 |
+
- fi
|
| 760 |
+
- fr
|
| 761 |
+
- hr
|
| 762 |
+
- hu
|
| 763 |
+
- it
|
| 764 |
+
- lt
|
| 765 |
+
- lv
|
| 766 |
+
- nl
|
| 767 |
+
- pl
|
| 768 |
+
- pt
|
| 769 |
+
- ro
|
| 770 |
+
- ru
|
| 771 |
+
- sk
|
| 772 |
+
- sv
|
| 773 |
+
- uk
|
| 774 |
+
pretty_name: YODAS-Granary
|
| 775 |
+
size_categories:
|
| 776 |
+
- 10M<n<100M
|
| 777 |
+
---
|
| 778 |
+
|
| 779 |
+
## Table of Contents
|
| 780 |
+
- [Dataset Description](#dataset-description)
|
| 781 |
+
- [Overview](#overview)
|
| 782 |
+
- [Data Distribution](#data-distribution)
|
| 783 |
+
- [How to Use](#how-to-use)
|
| 784 |
+
- [Standard Loading](#standard-loading)
|
| 785 |
+
- [Streaming](#streaming)
|
| 786 |
+
- [Using NeMo-speech-data-processor](#using-nemo-speech-data-processor)
|
| 787 |
+
- [Dataset Structure](#dataset-structure)
|
| 788 |
+
- [Data Instance](#data-instance)
|
| 789 |
+
- [Data Fields](#data-fields)
|
| 790 |
+
- [Data Splits](#data-splits)
|
| 791 |
+
- [Reference](#reference)
|
| 792 |
+
|
| 793 |
+
# Dataset Card for YODAS-Granary
|
| 794 |
+
- **Repository:** [NeMo-speech-data-processor: Granary](https://github.com/NVIDIA/NeMo-speech-data-processor/tree/main/dataset_configs/multilingual/granary)
|
| 795 |
+
- **Paper:** [Granary: Speech Recognition and Translation Dataset in 25 European Languages](https://arxiv.org/abs/2505.13404)
|
| 796 |
+
- **Shared by:** [ESPnet](https://huggingface.co/espnet)
|
| 797 |
+
|
| 798 |
+
## Dataset Description
|
| 799 |
+
YODAS-Granary is a curated subset of the larger [`nvidia/Granary`](https://huggingface.co/datasets/nvidia/Granary) dataset, focusing on high-quality pseudo-labeled speech data for Automatic Speech Recognition (ASR) and Automatic Speech Translation (AST) across 23 European languages.
|
| 800 |
+
|
| 801 |
+
### Overview
|
| 802 |
+
<table style="width:100%; table-layout:auto;">
|
| 803 |
+
<tr>
|
| 804 |
+
<td style="vertical-align:middle; text-align:center;">
|
| 805 |
+
<img src="./scheme.png" style="max-width:100%;">
|
| 806 |
+
</td>
|
| 807 |
+
<td style="vertical-align:middle; padding-left:20px;">
|
| 808 |
+
<p>
|
| 809 |
+
Derived from the <a href=https://huggingface.co/datasets/espnet/yodas2) target="_blank"><code>espnet/yodas2</code></a> corpus, YODAS-Granary provides high-quality pseudo-labeled speech data, focusing on two core tasks:
|
| 810 |
+
</p>
|
| 811 |
+
<ul>
|
| 812 |
+
<li><strong>Automatic Speech Recognition (ASR)</strong>: covers 23 European languages, with pseudo-labeled transcriptions generated using the <a href="https://huggingface.co/Systran/faster-whisper-large-v3" target="_blank"><code>Systran/faster-whisper-large-v3</code></a> model, post-processed to restore punctuation and capitalization using <a href="https://huggingface.co/Qwen/Qwen2.5-7B-Instruct" target="_blank"><code>Qwen/Qwen2.5-7B-Instruct</code></a>, and filtered for quality.</li>
|
| 813 |
+
<li><strong>Automatic Speech Translation (AST)</strong>: covers 22 non-English languages and consists of high-quality translations into English, generated from <code>ASR</code> subset using the <a href="https://huggingface.co/utter-project/EuroLLM-9B-Instruct" target="_blank"><code>utter-project/EuroLLM-9B-Instruct</code></a> model and filtered for quality.</li>
|
| 814 |
+
</ul>
|
| 815 |
+
</td>
|
| 816 |
+
</tr>
|
| 817 |
+
</table>
|
| 818 |
+
|
| 819 |
+
### Data Distribution
|
| 820 |
+
The following chart illustrates the distribution of data in the YODAS-Granary dataset across 23 European languages, measured in number of words (left) and total hours of audio (right), for both ASR and AST tasks.
|
| 821 |
+
|
| 822 |
+
<p align="center">
|
| 823 |
+
<img src="./chart.png" width="100%"/><br>
|
| 824 |
+
<em>🔍 AST data is always a filtered subset of ASR, which is why AST bars are never taller than their ASR counterparts.<br>🗣️ The English subset contains ASR data only.</em>
|
| 825 |
+
</p>
|
| 826 |
+
|
| 827 |
+
The table below summarizes the storage footprint and sample counts per language in the YODAS-Granary dataset, broken down into corresponding [splits](#data-splits):
|
| 828 |
+
- `ast` — the size and number of translated samples (X → English),
|
| 829 |
+
- `asr_only` — samples that exist only in the ASR subset and have no corresponding translation,
|
| 830 |
+
|
| 831 |
+
and combined size and number of all samples per language (`total`).
|
| 832 |
+
|
| 833 |
+
| Language | Subsets | Samples [`ast`] | Size [`ast`] | Samples [`asr_only`] | Size [`asr_only`] | Total samples | Total size |
|
| 834 |
+
|:----------:|:----------------------------:|:---------------:|:------------:|:--------------------:|:-----------------:|:---------------:|:------------:|
|
| 835 |
+
| Bulgarian | `bg000` | 8844 | 1.9 GB | 1533 | 208.8 MB | 10377 | 2.1 GB |
|
| 836 |
+
| Czech | `cs000` | 34360 | 7.5 GB | 4185 | 442.1 MB | 38545 | 8.0 GB |
|
| 837 |
+
| Danish | `da000` | 9582 | 1.9 GB | 656 | 65.3 MB | 10238 | 2.0 GB |
|
| 838 |
+
| German | `de000`, `de{100..102}` | 3335156 | 845.6 GB | 415260 | 56.3 GB | 3750416 | 901.9 GB |
|
| 839 |
+
| Greek | `el000` | 4242 | 1.6 GB | 514 | 113.5 MB | 4756 | 1.7 GB |
|
| 840 |
+
| English | `en00{0..7}`, `en{100..129}` | ❌ | ❌ | 40810517 | 11.3 TB | 40810517 | 11.3 TB |
|
| 841 |
+
| Spanish | `es000`, `es{100..108}` | 7923646 | 2.9 TB | 951450 | 88.8 GB | 8875096 | 3.0 TB |
|
| 842 |
+
| Estonian | `et000` | 4437 | 901.8 MB | 513 | 57.8 MB | 4950 | 959.6 MB |
|
| 843 |
+
| Finnish | `fi000` | 60729 | 17.4 GB | 4637 | 419.3 MB | 65366 | 17.8 GB |
|
| 844 |
+
| French | `fr000`, `fr{100..103}` | 4766239 | 1.3 TB | 558848 | 81.1 GB | 5325087 | 1.4 TB |
|
| 845 |
+
| Croatian | `hr000` | 5369 | 1.1 GB | 261 | 27.9 MB | 5630 | 1.1 GB |
|
| 846 |
+
| Hungarian | `hu000` | 48263 | 16.4 GB | 6530 | 962.7 MB | 54793 | 17.4 GB |
|
| 847 |
+
| Italian | `it000`, `it{100..101}` | 1226663 | 683.7 GB | 86587 | 13.6 GB | 1313250 | 697.3 GB |
|
| 848 |
+
| Lithuanian | `lt000` | 2177 | 564.5 MB | 390 | 71.1 MB | 2567 | 635.6 MB |
|
| 849 |
+
| Latvian | `lv000` | 272 | 66.5 MB | 75 | 12.0 MB | 347 | 78.5 MB |
|
| 850 |
+
| Dutch | `nl000`, `nl100` | 865754 | 151.1 GB | 71490 | 4.3 GB | 937244 | 155.4 GB |
|
| 851 |
+
| Polish | `pl000` | 264257 | 75.5 GB | 28678 | 2.4 GB | 292935 | 77.9 GB |
|
| 852 |
+
| Portuguese | `pt000`, `pt{100..103}` | 5898764 | 1.5 TB | 729138 | 30.1 GB | 6627902 | 1.5 TB |
|
| 853 |
+
| Romanian | `ro000` | 12276 | 3.7 GB | 2303 | 663.4 MB | 14579 | 4.4 GB |
|
| 854 |
+
| Russian | `ru00{0..1}`, `ru{100..106}` | 7991038 | 2.1 TB | 1876876 | 197.0 GB | 9867914 | 2.3 TB |
|
| 855 |
+
| Slovak | `sk000` | 3405 | 992.0 MB | 287 | 51.9 MB | 3692 | 1.0 GB |
|
| 856 |
+
| Swedish | `sv000` | 54085 | 10.2 GB | 3192 | 215.7 MB | 57277 | 10.4 GB |
|
| 857 |
+
| Ukrainian | `uk000`, `uk100` | 246373 | 68.3 GB | 9479 | 1.2 GB | 255852 | 69.4 GB |
|
| 858 |
+
***
|
| 859 |
+
|
| 860 |
+
## How to use
|
| 861 |
+
### Standard Loading
|
| 862 |
+
You can load the dataset using the `datasets` library from Hugging Face:
|
| 863 |
+
|
| 864 |
+
```python
|
| 865 |
+
from datasets import load_dataset
|
| 866 |
+
```
|
| 867 |
+
|
| 868 |
+
**🔹 Load the entire dataset:**
|
| 869 |
+
```python
|
| 870 |
+
ds = load_dataset("espnet/yodas-granary")
|
| 871 |
+
```
|
| 872 |
+
|
| 873 |
+
**🔹 Load a single language (e.g., Italian):**
|
| 874 |
+
```python
|
| 875 |
+
ds = load_dataset("espnet/yodas-granary", "Italian")
|
| 876 |
+
```
|
| 877 |
+
|
| 878 |
+
### Streaming
|
| 879 |
+
Some language subsets are quite large and may not fit comfortably in memory. For efficient access and analysis without downloading the entire dataset, we recommend using streaming mode:
|
| 880 |
+
|
| 881 |
+
``` python
|
| 882 |
+
ds = load_dataset("espnet/yodas-granary", "English", streaming=True)
|
| 883 |
+
```
|
| 884 |
+
|
| 885 |
+
### Using NeMo-speech-data-processor
|
| 886 |
+
You can use the [NeMo-speech-data-processor](https://github.com/NVIDIA/NeMo-speech-data-processor) to convert YODAS-Granary into a tarred WebDataset format suitable for training or fine-tuning [NeMo ASR models](https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/asr/models.html).
|
| 887 |
+
|
| 888 |
+
Clone and install the processor:
|
| 889 |
+
``` shell
|
| 890 |
+
git clone https://github.com/NVIDIA/NeMo-speech-data-processor.git
|
| 891 |
+
cd NeMo-speech-data-processor && pip install -e .
|
| 892 |
+
```
|
| 893 |
+
|
| 894 |
+
By specifying the desired `source_lang`, `en_translation`, `num_shards`, and `buckets_num`, the script will automatically download the required language subsets from Hugging Face and convert them into WebDataset format:
|
| 895 |
+
``` shell
|
| 896 |
+
python main.py \
|
| 897 |
+
--config-path=dataset_configs/multilingual/granary/ \
|
| 898 |
+
--config-name=yodas2.yaml \
|
| 899 |
+
params.source_lang="it" \ # target language
|
| 900 |
+
params.en_translation=True \ # use AST or ASR subset
|
| 901 |
+
params.convert_to_audio_tarred_dataset.num_shards=1024 \ # number of shards per bucket
|
| 902 |
+
params.convert_to_audio_tarred_dataset.buckets_num=1 # number of output buckets
|
| 903 |
+
```
|
| 904 |
+
|
| 905 |
+
📘 For detailed setup instructions, see the [NeMo-speech-data-processor: Granary](https://github.com/NVIDIA/NeMo-speech-data-processor/tree/main/dataset_configs/multilingual/granary).
|
| 906 |
+
***
|
| 907 |
+
|
| 908 |
+
|
| 909 |
+
## Dataset Structure
|
| 910 |
+
### Data Instance
|
| 911 |
+
Each utterance in the dataset includes the following fields: `utt_id`, `audio`, `duration`, `lang`, `task`, `text`, `translation_en` (`null` in `asr_only`), `original_audio_id`, and `original_audio_offset`.
|
| 912 |
+
|
| 913 |
+
**Typical entry**
|
| 914 |
+
|
| 915 |
+
from `data/de101/translation/00000000.parquet`
|
| 916 |
+
|
| 917 |
+
```python
|
| 918 |
+
{
|
| 919 |
+
"utt_id": "de101_00000000_Z0_gcPJVTqg_1004_62_1_74",
|
| 920 |
+
"audio": {
|
| 921 |
+
'path': 'de101_00000000_Z0_gcPJVTqg_1004_62_1_74.wav',
|
| 922 |
+
'bytes': ...
|
| 923 |
+
}
|
| 924 |
+
"duration": 1.74,
|
| 925 |
+
"lang": "<de>",
|
| 926 |
+
"task": "<ast>",
|
| 927 |
+
"text": "Ich muss mir das Zeug mal aus der Nähe ansehen.",
|
| 928 |
+
"translation_en": "I have to take a closer look at this stuff.",
|
| 929 |
+
"original_audio_id": "Z0_gcPJVTqg",
|
| 930 |
+
"original_audio_offset": 1004.62
|
| 931 |
+
}
|
| 932 |
+
```
|
| 933 |
+
|
| 934 |
+
### Data Fields
|
| 935 |
+
|
| 936 |
+
| **Field** | **Type** | **Description** |
|
| 937 |
+
|---|---|---|
|
| 938 |
+
| `utt_id¹` | `string` | Unique identifier of the utterance, referencing the original segment. |
|
| 939 |
+
| `audio` | `Audio (16 kHz)` | Audio data of the utterance, stored as PCM waveform. |
|
| 940 |
+
| `duration` | `float64` | Duration of the utterance in seconds. |
|
| 941 |
+
| `lang` | `string` | Language of the utterance, in ISO 639-1 code (e.g., `<de>` for German). |
|
| 942 |
+
| `task` | `string` | Task type: either `<asr>` for transcription or `<ast>` for translation to English. |
|
| 943 |
+
| `text` | `string` | Transcription of the utterance in its original language. |
|
| 944 |
+
| `translation_en` | `string` | English translation of the utterance. `null` if split is `asr_only`. |
|
| 945 |
+
| `original_audio_id` | `string` | ID of the original audio file. This value corresponds to the `audio_id` field from the [`espnet/yodas2`](https://huggingface.co/datasets/espnet/yodas2) dataset. |
|
| 946 |
+
| `original_audio_offset` | `float64` | Start time (in seconds) of the utterance within the original audio file. |
|
| 947 |
+
|
| 948 |
+
¹ - `utt_id` is encoded as `<subset>_<shard>_<wav_id>_<start_time_s>_<start_time_decimals>_<duration_s>_<duration_decimals>`, where `subset`, `shard²`, and `wav_id` match the utterance's location in the original [`espnet/yodas2`](https://huggingface.co/datasets/espnet/yodas2) archive.
|
| 949 |
+
|
| 950 |
+
² - `shard` indices reflect those in [`espnet/yodas2`](https://huggingface.co/datasets/espnet/yodas2), but some shards are missing due to filtering during data processing. In particular, `bg000` is missing shard `00000011`, `en000` is missing shard `00000308`, `en003` is missing shard `00000221`, `en118` is missing shard `00000240`.
|
| 951 |
+
|
| 952 |
+
### Data Splits
|
| 953 |
+
The dataset is organized into language-specific subsets, each containing one or two splits, depending on the language:
|
| 954 |
+
|
| 955 |
+
- **For non-English languages:**
|
| 956 |
+
- `<ast>` – samples with **both high-quality transcriptions and translations** into English.
|
| 957 |
+
- `<asr_only>` – samples that passed transcription quality checks but do not include translations.
|
| 958 |
+
- **For `English`**:
|
| 959 |
+
- `<asr_only>` split is available only, since English-to-English translation is not applicable.
|
| 960 |
+
|
| 961 |
+
**Directory example**
|
| 962 |
+
``` python
|
| 963 |
+
yodas_granary
|
| 964 |
+
└── data
|
| 965 |
+
├── da000 # subset
|
| 966 |
+
│ ├── asr_only # corresponds to `asr_only` split
|
| 967 |
+
│ │ ├── 00000000.parquet # shard
|
| 968 |
+
│ │ ├── 00000001.parquet
|
| 969 |
+
│ │ ├── 00000002.parquet
|
| 970 |
+
│ │ └── ...
|
| 971 |
+
│ └── ast # corresponds to `ast` split
|
| 972 |
+
│ ├── 00000000.parquet # shard
|
| 973 |
+
│ ├── 00000001.parquet
|
| 974 |
+
│ ├── 00000002.parquet
|
| 975 |
+
│ └── ...
|
| 976 |
+
├── cs000
|
| 977 |
+
├── bg000
|
| 978 |
+
└── ...
|
| 979 |
+
```
|
| 980 |
+
***
|
| 981 |
+
|
| 982 |
+
## Reference
|
| 983 |
+
|
| 984 |
+
```bibtex
|
| 985 |
+
@inproceedings{koluguri2024granary,
|
| 986 |
+
title = {Granary: Speech Recognition and Translation Dataset in 25 European Languages},
|
| 987 |
+
author = {Nithin Rao Koluguri and Monica Sekoyan and George Zelenfroynd and Sasha Meister and Shuoyang Ding and Sofia Kostandian and He Huang and Nikolay Karpov and Jagadeesh Balam and Vitaly Lavrukhin and Boris Ginsburg},
|
| 988 |
+
booktitle = {arXiv preprint arXiv:2505.13404},
|
| 989 |
+
year = {2024},
|
| 990 |
+
url = {https://arxiv.org/abs/2505.13404}
|
| 991 |
+
}
|
| 992 |
+
```
|
chart.png
ADDED

|
Git LFS Details
|
scheme.png
ADDED
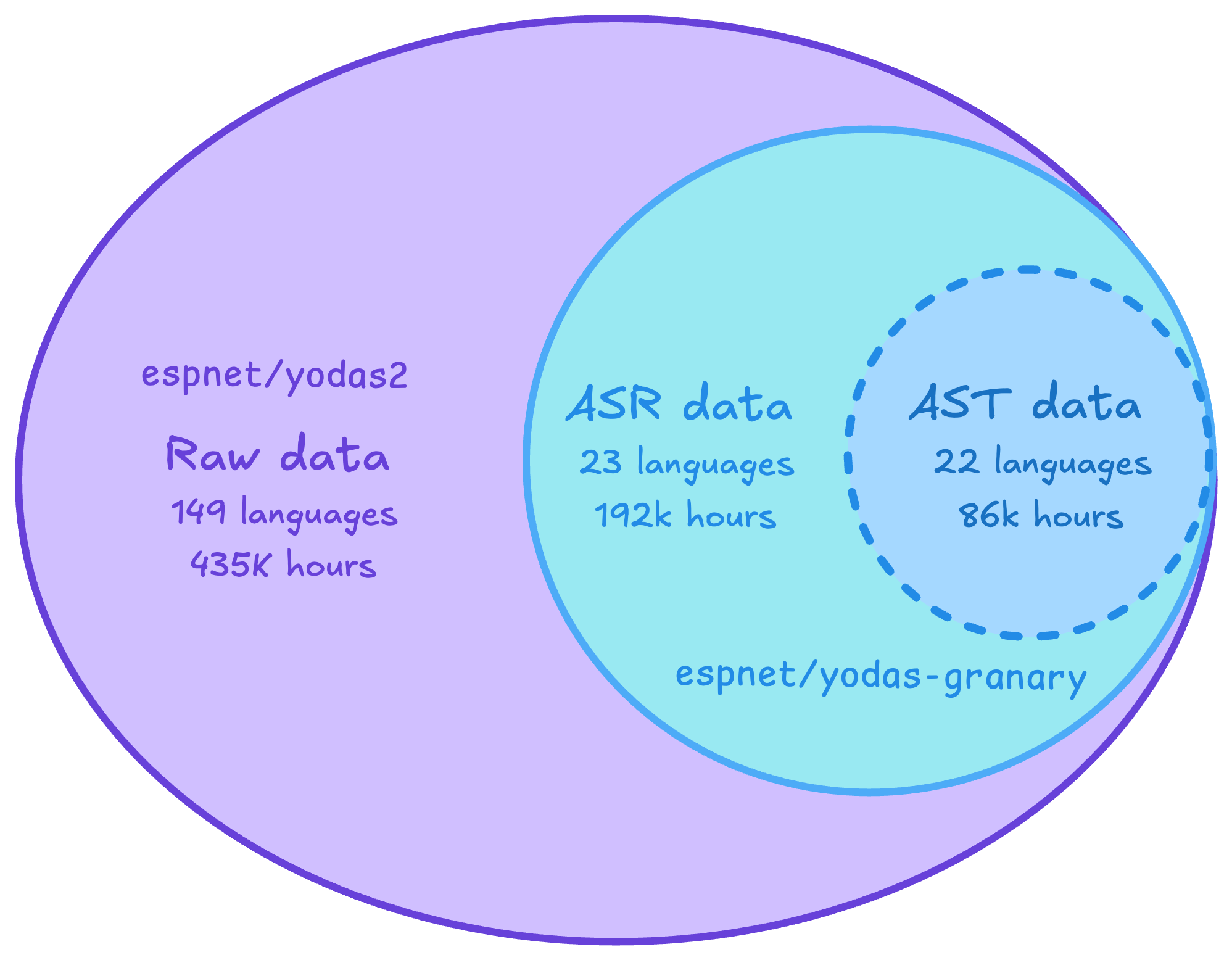
|
Git LFS Details
|