
Reasoning Guided Embeddings (RGE)
Reasoning Guided Embeddings: Leveraging MLLM Reasoning for Improved Multimodal Retrieval.
Chunxu Liu, Jiyuan Yang, Ruopeng Gao, Yuhan Zhu, Feng Zhu, Rui Zhao, Limin Wang
The proposed model is trained based on Qwen2.5-VL-3B-Instruct.
TL; DR. We introduce Reasoning Guide Embedding (RGE) model, which takes advantage of MLLMs’ structured reasoning during embedding extraction, using generated rationales with contrastive training to produce more context-aware representations, improving embedding quality.
Eval data:
We use MMEB-eval for multimodal retrieval evaluation.
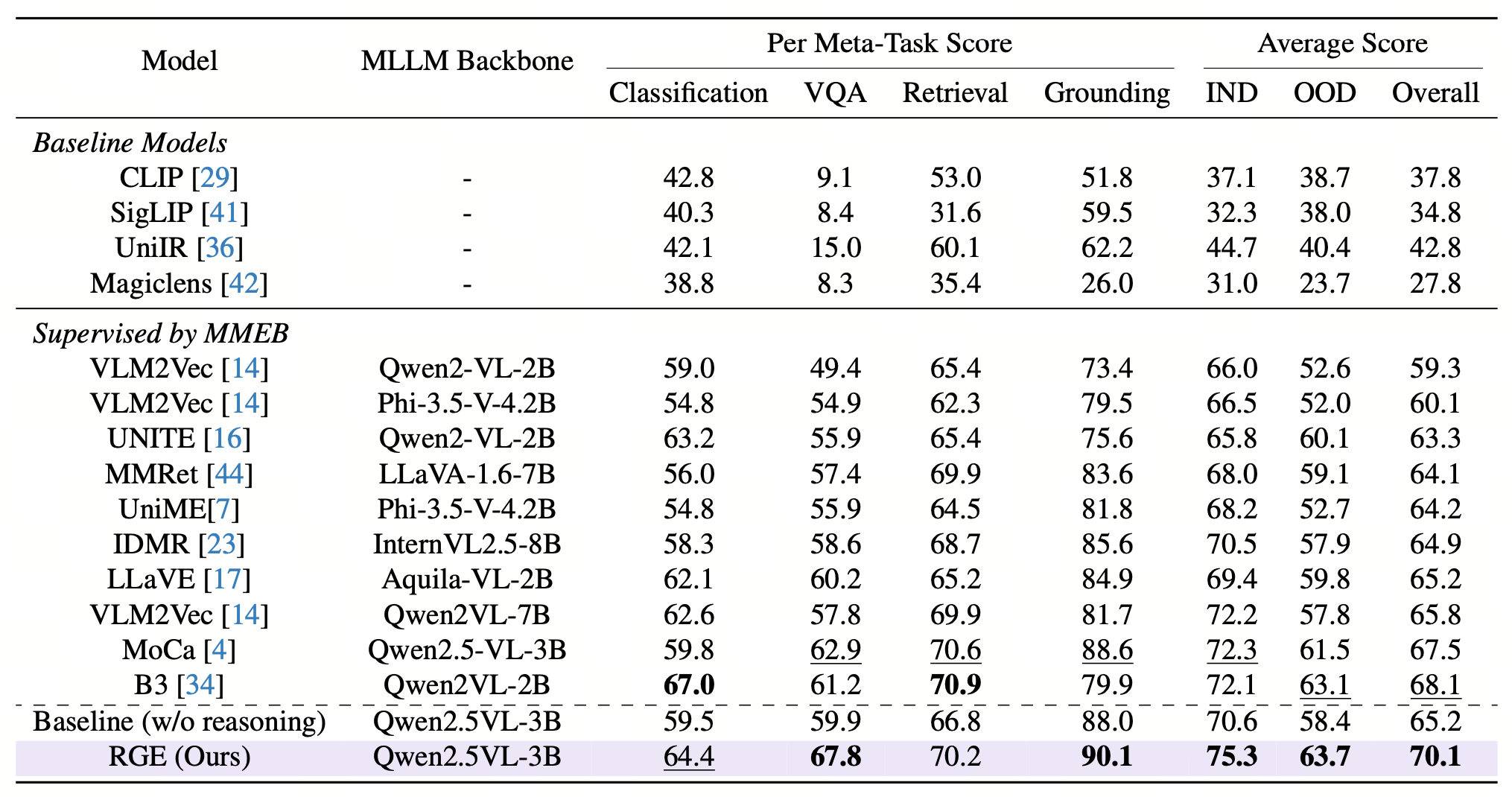
Experimental Results
Usage
Transformers
Below is an example we adapted from VLM2Vec and MoCa.
git clone https://github.com/MCG-NJU/RGE.git
cd RGE
pip install -r requirements.txt
from transformers import AutoProcessor, AutoConfig, Qwen2_5_VLForConditionalGeneration
import torch
from PIL import Image
import torch.nn.functional as F
def compute_similarity(q_reps, p_reps):
return torch.matmul(q_reps, p_reps.transpose(0, 1))
def construct_prompt(text):
return [
{
"role": "user",
"content": [
{"type": "text", "text": text}
]
}
]
@torch.no_grad()
def encode_and_generate(model, processor, inputs: dict):
# baseline -> caption
generation_output = model.generate(
**inputs,
return_dict_in_generate=True,
output_hidden_states=True,
max_new_tokens=128,
eos_token_id=processor.tokenizer.convert_tokens_to_ids("<emb>"),
use_cache=True,
)
prompt_len = inputs['input_ids'].shape[1]
generated_ids = generation_output.sequences[0][prompt_len:]
generated_text = processor.tokenizer.decode(generated_ids, skip_special_tokens=False)
print(f"generated_text: {generated_text}")
past_seen = generation_output.past_key_values.get_seq_length()
new_inputs = {
'input_ids': generation_output.sequences[:, -1:],
'past_key_values': generation_output.past_key_values,
'cache_position': torch.arange(past_seen, past_seen + 1, device=generation_output.sequences.device),
}
outputs = model(**new_inputs, output_hidden_states=True, use_cache=True)
pooled_output = outputs.hidden_states[-1][:, -1, :]
return pooled_output, generated_text
@torch.no_grad()
def ar_encode(model, processor, inputs: dict):
def _ar_pooling(input_ids, hidden_states):
emb_id = processor.tokenizer.convert_tokens_to_ids("<emb>")
embed_indices = torch.argmax((input_ids == emb_id).int(), dim=1)
embed_features = hidden_states[torch.arange(len(embed_indices)), embed_indices]
return embed_features
outputs = model(**inputs, output_hidden_states=True)
pooled_output = _ar_pooling(inputs['input_ids'], outputs.hidden_states[-1])
return pooled_output
model_name = "lcxrocks/RGE"
processor_name = "lcxrocks/RGE"
# Load Processor and Model
processor = AutoProcessor.from_pretrained(processor_name)
config = AutoConfig.from_pretrained(model_name)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_name, config=config,
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2',
).to("cuda")
model.eval()
string = "<|vision_start|><|image_pad|><|vision_end|> Answer the question based on the given image: What is in the image?\n"
instruction = processor.apply_chat_template(construct_prompt(string), tokenize=False, add_generation_prompt=True)
inputs = processor(text=instruction, images=[Image.open('assets/example.jpg')], return_tensors="pt").to("cuda")
qry_output, generated_text = encode_and_generate(model, processor, inputs)
qry_output = F.normalize(qry_output, p=2, dim=-1)
string = 'Summarize the following answer in one word: A cat and a dog.'
instruction = processor.apply_chat_template(construct_prompt(string), tokenize=False, add_generation_prompt=True) + "<emb>"
inputs = processor(text=instruction, images=None, return_tensors="pt").to("cuda")
tgt_output = ar_encode(model, processor, inputs)
tgt_output = F.normalize(tgt_output, p=2, dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
# tensor([[0.7031]], device='cuda:0', dtype=torch.bfloat16)
string = 'Summarize the following answer in one word: A cat and a tiger.'
instruction = processor.apply_chat_template(construct_prompt(string), tokenize=False, add_generation_prompt=True) + "<emb>"
inputs = processor(text=instruction, images=None, return_tensors="pt").to("cuda")
tgt_output = ar_encode(model, processor, inputs)
tgt_output = F.normalize(tgt_output, p=2, dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
# tensor([[0.6250]], device='cuda:0', dtype=torch.bfloat16)
Citation
If you use this model in your research, please cite the associated paper.
@misc{liu2025reasoningguidedembeddingsleveraging,
title={Reasoning Guided Embeddings: Leveraging MLLM Reasoning for Improved Multimodal Retrieval},
author={Chunxu Liu and Jiyuan Yang and Ruopeng Gao and Yuhan Zhu and Feng Zhu and Rui Zhao and Limin Wang},
year={2025},
eprint={2511.16150},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.16150},
}
- Downloads last month
- 24
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
Model tree for MCG-NJU/RGE
Base model
Qwen/Qwen2.5-VL-3B-Instruct