A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency
 leejaymin
leejaymin









Abstract
A comprehensive evaluation of 25 open-source and commercial LLM inference engines across various criteria and optimization techniques is provided, with an outline of future research directions.
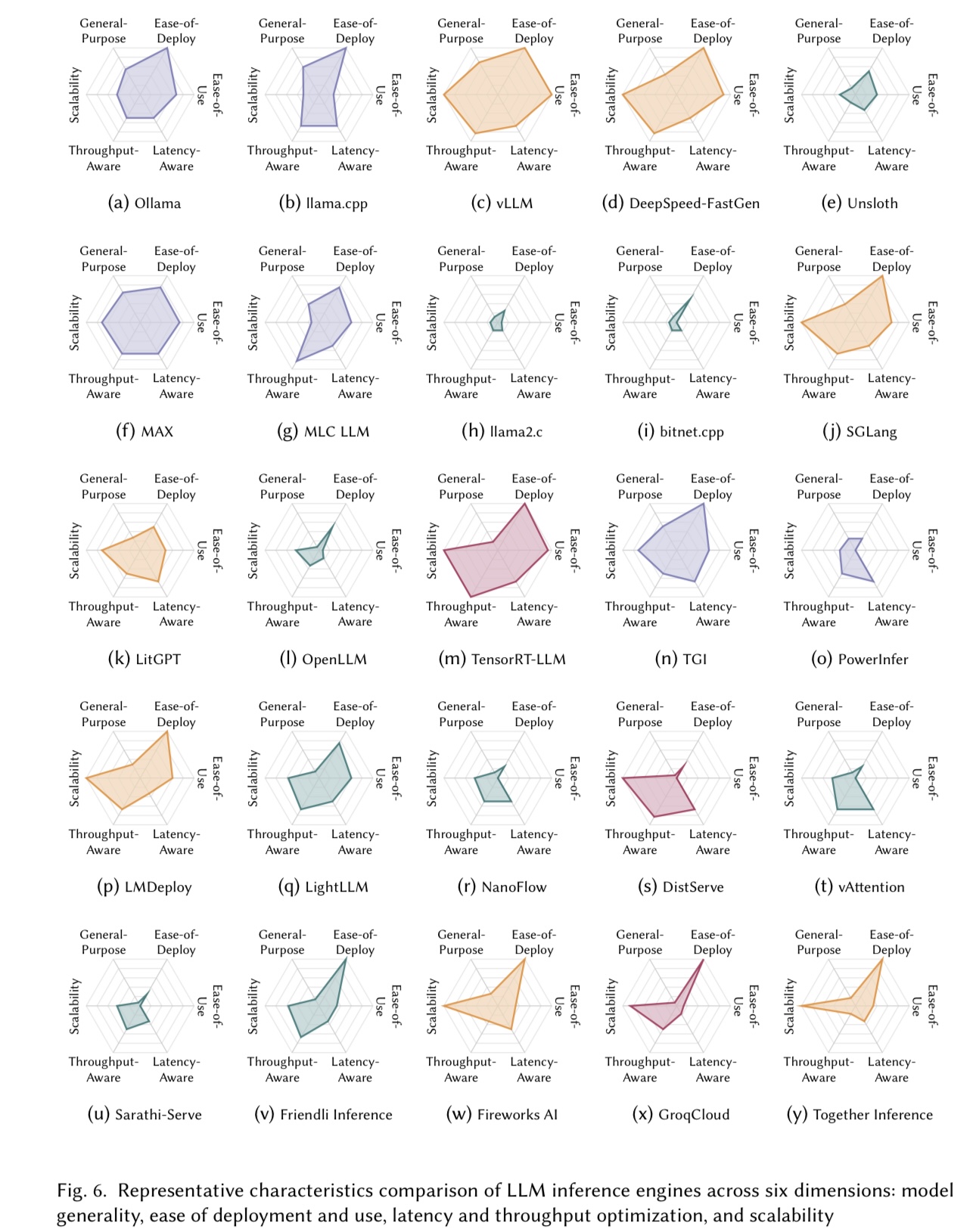
Large language models (LLMs) are widely applied in chatbots, code generators, and search engines. Workloads such as chain-of-thought, complex reasoning, and agent services significantly increase the inference cost by invoking the model repeatedly. Optimization methods such as parallelism, compression, and caching have been adopted to reduce costs, but the diverse service requirements make it hard to select the right method. Recently, specialized LLM inference engines have emerged as a key component for integrating the optimization methods into service-oriented infrastructures. However, a systematic study on inference engines is still lacking. This paper provides a comprehensive evaluation of 25 open-source and commercial inference engines. We examine each inference engine in terms of ease-of-use, ease-of-deployment, general-purpose support, scalability, and suitability for throughput- and latency-aware computation. Furthermore, we explore the design goals of each inference engine by investigating the optimization techniques it supports. In addition, we assess the ecosystem maturity of open source inference engines and handle the performance and cost policy of commercial solutions. We outline future research directions that include support for complex LLM-based services, support of various hardware, and enhanced security, offering practical guidance to researchers and developers in selecting and designing optimized LLM inference engines. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/sihyeong/Awesome-LLM-Inference-Engine
Community
In this comprehensive survey, we:
• Analyze 25 open-source and commercial LLM inference engines
• Compare them across ease of use, scalability, deployment, and optimization support
• Explore supported techniques such as quantization, batching, caching, speculative decoding, and more
• Provide practical guidance for selecting the right engine depending on latency vs. throughput needs
• Discuss future challenges like multi-modal support, hardware diversity, and security
• Maintain a public GitHub repository tracking updates in this fast-evolving field:
🔗 https://github.com/sihyeong/Awesome-LLM-Inference-Engine




amazing work, thank you to all the researchers involved!

Thank you very much for this impressive work. May I ask whether it has already been peer-reviewed?
Yes, the paper is currently under review. However, we are actively making revisions during the review process, both on arXiv and GitHub. If you have any suggestions, we’re happy to review them and incorporate changes as appropriate.




Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper