 rmvenkat
rmvenkat





Abstract
A visual world model called SpelkeNet outperforms existing methods in identifying Spelke objects in images, improving performance in tasks like physical object manipulation.
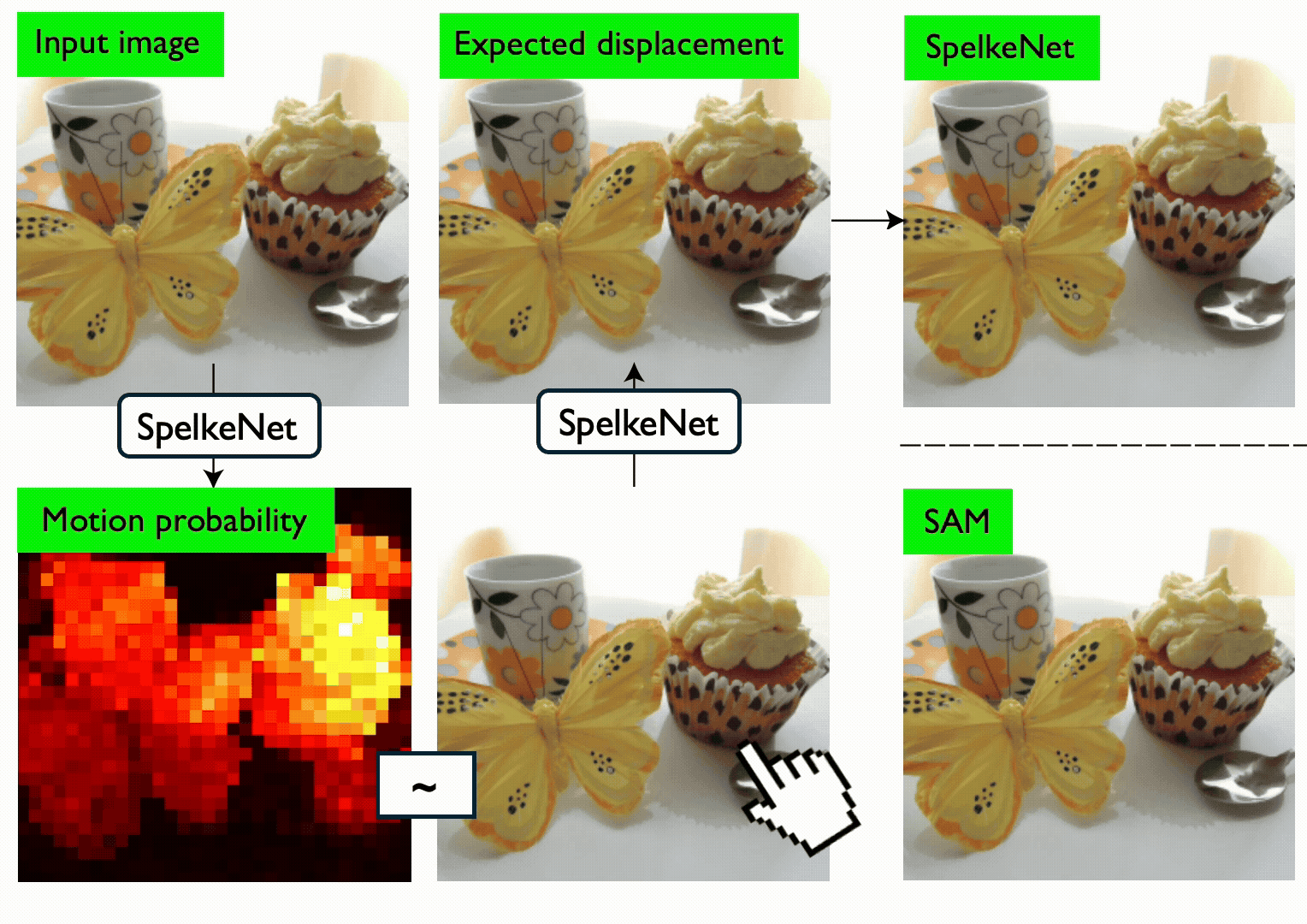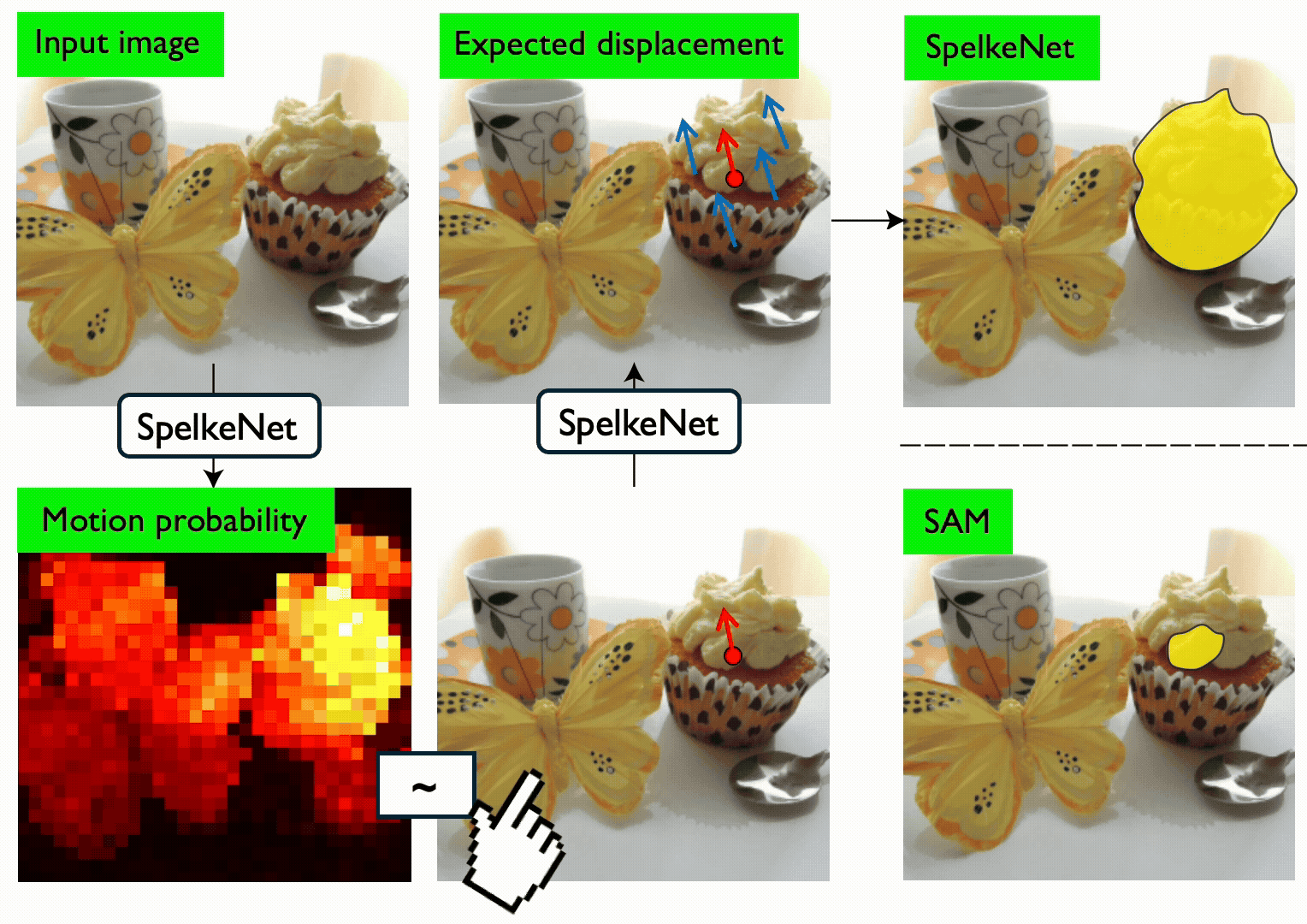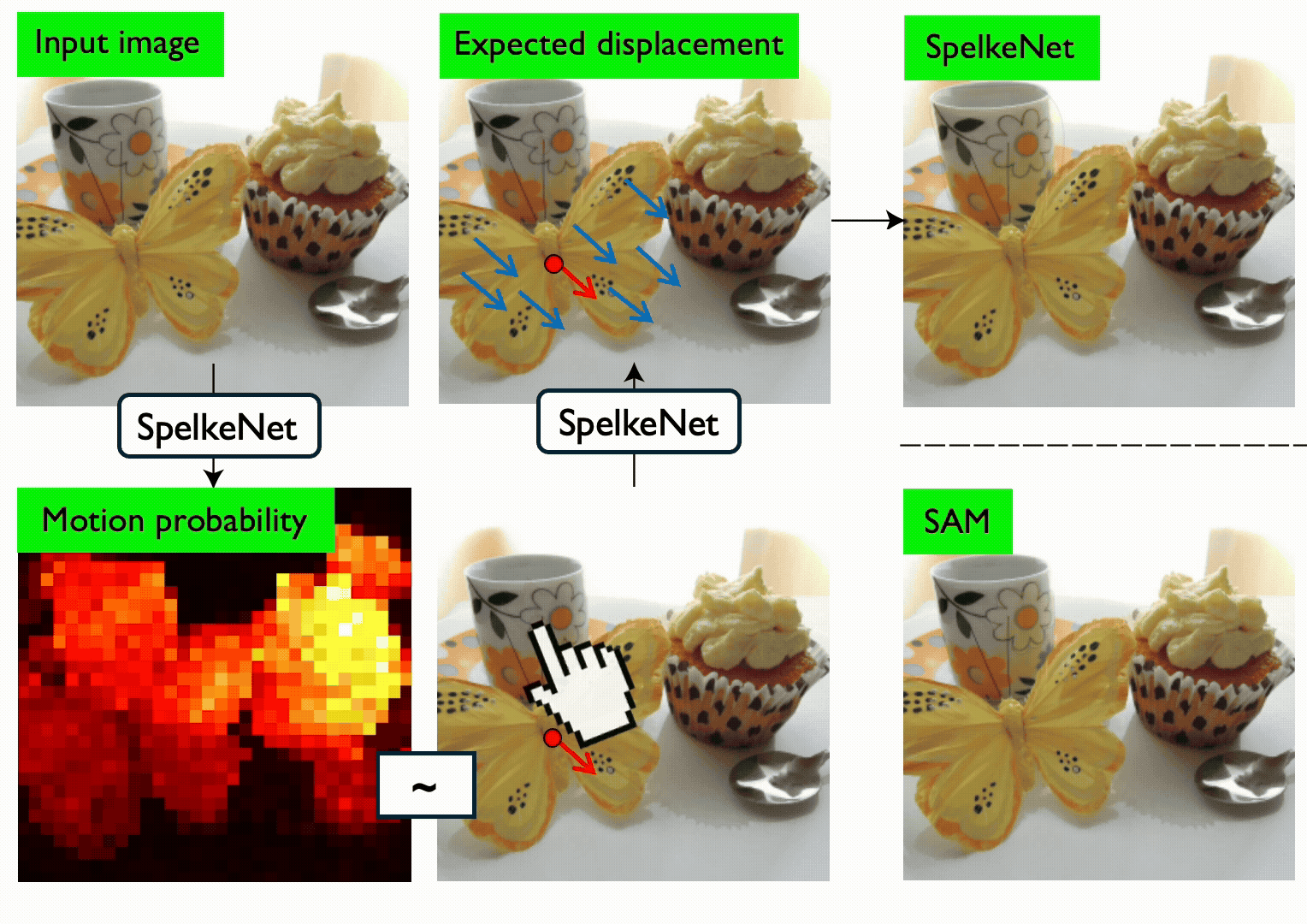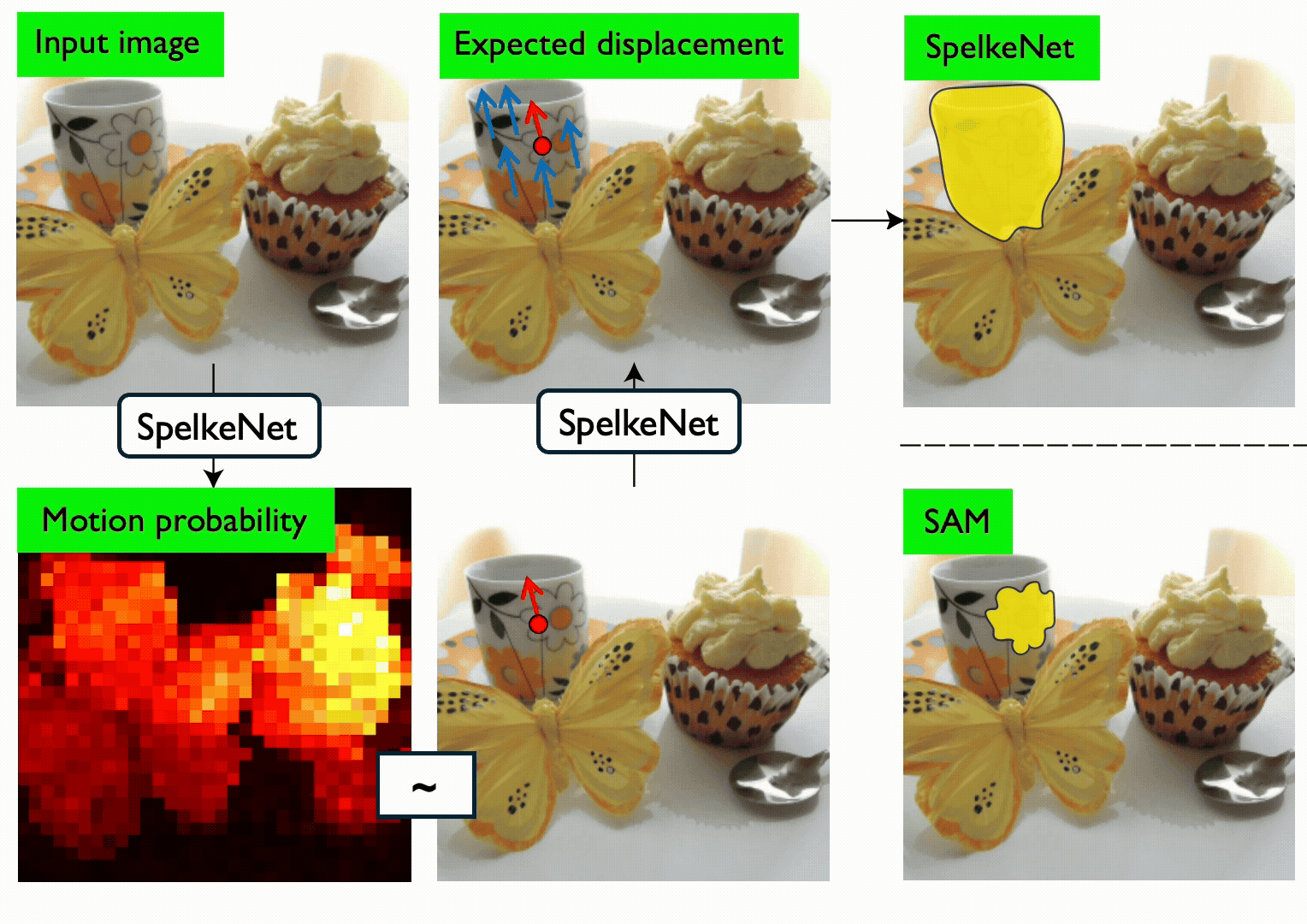
Segments in computer vision are often defined by semantic considerations and are highly dependent on category-specific conventions. In contrast, developmental psychology suggests that humans perceive the world in terms of Spelke objects--groupings of physical things that reliably move together when acted on by physical forces. Spelke objects thus operate on category-agnostic causal motion relationships which potentially better support tasks like manipulation and planning. In this paper, we first benchmark the Spelke object concept, introducing the SpelkeBench dataset that contains a wide variety of well-defined Spelke segments in natural images. Next, to extract Spelke segments from images algorithmically, we build SpelkeNet, a class of visual world models trained to predict distributions over future motions. SpelkeNet supports estimation of two key concepts for Spelke object discovery: (1) the motion affordance map, identifying regions likely to move under a poke, and (2) the expected-displacement map, capturing how the rest of the scene will move. These concepts are used for "statistical counterfactual probing", where diverse "virtual pokes" are applied on regions of high motion-affordance, and the resultant expected displacement maps are used define Spelke segments as statistical aggregates of correlated motion statistics. We find that SpelkeNet outperforms supervised baselines like SegmentAnything (SAM) on SpelkeBench. Finally, we show that the Spelke concept is practically useful for downstream applications, yielding superior performance on the 3DEditBench benchmark for physical object manipulation when used in a variety of off-the-shelf object manipulation models.
Community
AI models segment scenes based on how things appear, but babies segment based on what moves together. We utilize a visual world model to capture this concept — and we find that it beats state-of-the-art models on zero-shot segmentation and physical manipulation tasks.

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- HOI-PAGE: Zero-Shot Human-Object Interaction Generation with Part Affordance Guidance (2025)
- Affordance Benchmark for MLLMs (2025)
- SeC: Advancing Complex Video Object Segmentation via Progressive Concept Construction (2025)
- CRAFT: A Neuro-Symbolic Framework for Visual Functional Affordance Grounding (2025)
- HalluSegBench: Counterfactual Visual Reasoning for Segmentation Hallucination Evaluation (2025)
- Open World Scene Graph Generation using Vision Language Models (2025)
- How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks (2025)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend
Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper
Collections including this paper 0
No Collection including this paper