Agentic Reinforced Policy Optimization
 dongguanting
dongguanting






Abstract
Agentic Reinforced Policy Optimization (ARPO) is a novel RL algorithm that enhances multi-turn LLM-based agents by adaptive uncertainty management and advantage attribution, outperforming trajectory-level RL algorithms with reduced resource usage.
Large-scale reinforcement learning with verifiable rewards (RLVR) has demonstrated its effectiveness in harnessing the potential of large language models (LLMs) for single-turn reasoning tasks. In realistic reasoning scenarios, LLMs can often utilize external tools to assist in task-solving processes. However, current RL algorithms inadequately balance the models' intrinsic long-horizon reasoning capabilities and their proficiency in multi-turn tool interactions. To bridge this gap, we propose Agentic Reinforced Policy Optimization (ARPO), a novel agentic RL algorithm tailored for training multi-turn LLM-based agents. Through preliminary experiments, we observe that LLMs tend to exhibit highly uncertain behavior, characterized by an increase in the entropy distribution of generated tokens, immediately following interactions with external tools. Motivated by this observation, ARPO incorporates an entropy-based adaptive rollout mechanism, dynamically balancing global trajectory sampling and step-level sampling, thereby promoting exploration at steps with high uncertainty after tool usage. By integrating an advantage attribution estimation, ARPO enables LLMs to internalize advantage differences in stepwise tool-use interactions. Our experiments across 13 challenging benchmarks in computational reasoning, knowledge reasoning, and deep search domains demonstrate ARPO's superiority over trajectory-level RL algorithms. Remarkably, ARPO achieves improved performance using only half of the tool-use budget required by existing methods, offering a scalable solution for aligning LLM-based agents with real-time dynamic environments. Our code and datasets are released at https://github.com/dongguanting/ARPO
Community
💡 Overview
We propose Agentic Reinforced Policy Optimization (ARPO), an agentic RL algorithm tailored for training multi-turn LLM-based agent. The core principle of ARPO is to encourage the policy model to adaptively branch sampling during high-entropy tool-call rounds, thereby efficiently aligning step-level tool-use behaviors.
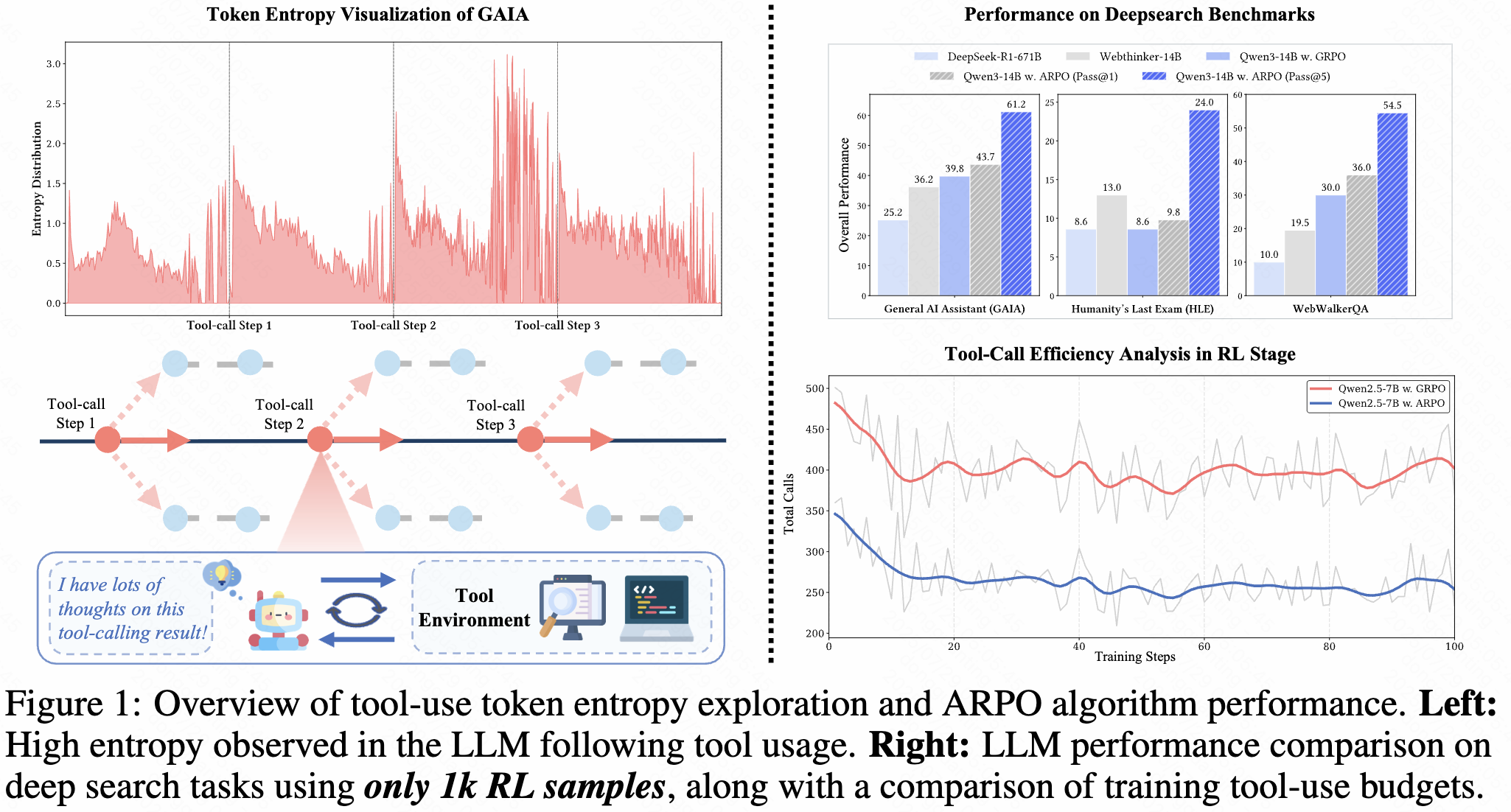
🔥 Key Insights
- We have discovered for the first time that high entropy fluctuations occur after LLMs interact with external tool environments, indicating that tool calls introduce significant uncertainty into the model's reasoning direction.
- Based on this entropy exploration, ARPO proposes an entropy-based adaptive rollout mechanism. The core idea is to adaptively perform additional branch sampling during high-entropy tool interaction rounds to supplement exploration for uncertain reasoning steps.
- To accommodate adaptive sampling, we propose advantage attribution estimation , which assigns the same advantage to shared reasoning steps in rollouts and different advantages to branching reasoning steps, allowing the model to focus on learning tool-calling behaviors for different branch samples.
- We validate ARPO's exceptional advantages over other RL algorithms in multi-turn tool interaction scenarios on 13 challenging benchmarks , such as mathematical reasoning (AIME24, 25, etc.), knowledge reasoning (HotpotQA, etc.), and deep search (GAIA, HLE, etc.). Notably, Qwen3-14B achieved a Pass@5 metric of GAIA: 61.2%, HLE: 24%, Xbench-DS: 59% with only 1k samples trained using RL.
- Thanks to adaptive sampling, the number of tool calls during ARPO training is only half that of sample-level algorithms like GRPO , with lower algorithm complexity, making it efficient and cost-effective.
- We further provide a detailed theoretical proof of ARPO's rationale in multi-round interactive agent training.
🔧✨ All the code, datasets and model checkpoints of ARPO are fully open-sourced:
Github: https://github.com/dongguanting/ARPO
Datasets & Models: https://huggingface.co/collections/dongguanting/arpo-688229ff8a6143fe5b4ad8ae





Models citing this paper 5
Browse 5 models citing this paperDatasets citing this paper 3
Spaces citing this paper 0
No Space linking this paper