Region-based Cluster Discrimination for Visual Representation Learning
 xiangan
xiangan







Abstract
RICE enhances region-level visual and OCR capabilities through a novel Region Transformer and cluster discrimination loss, achieving superior performance across dense prediction and perception tasks.
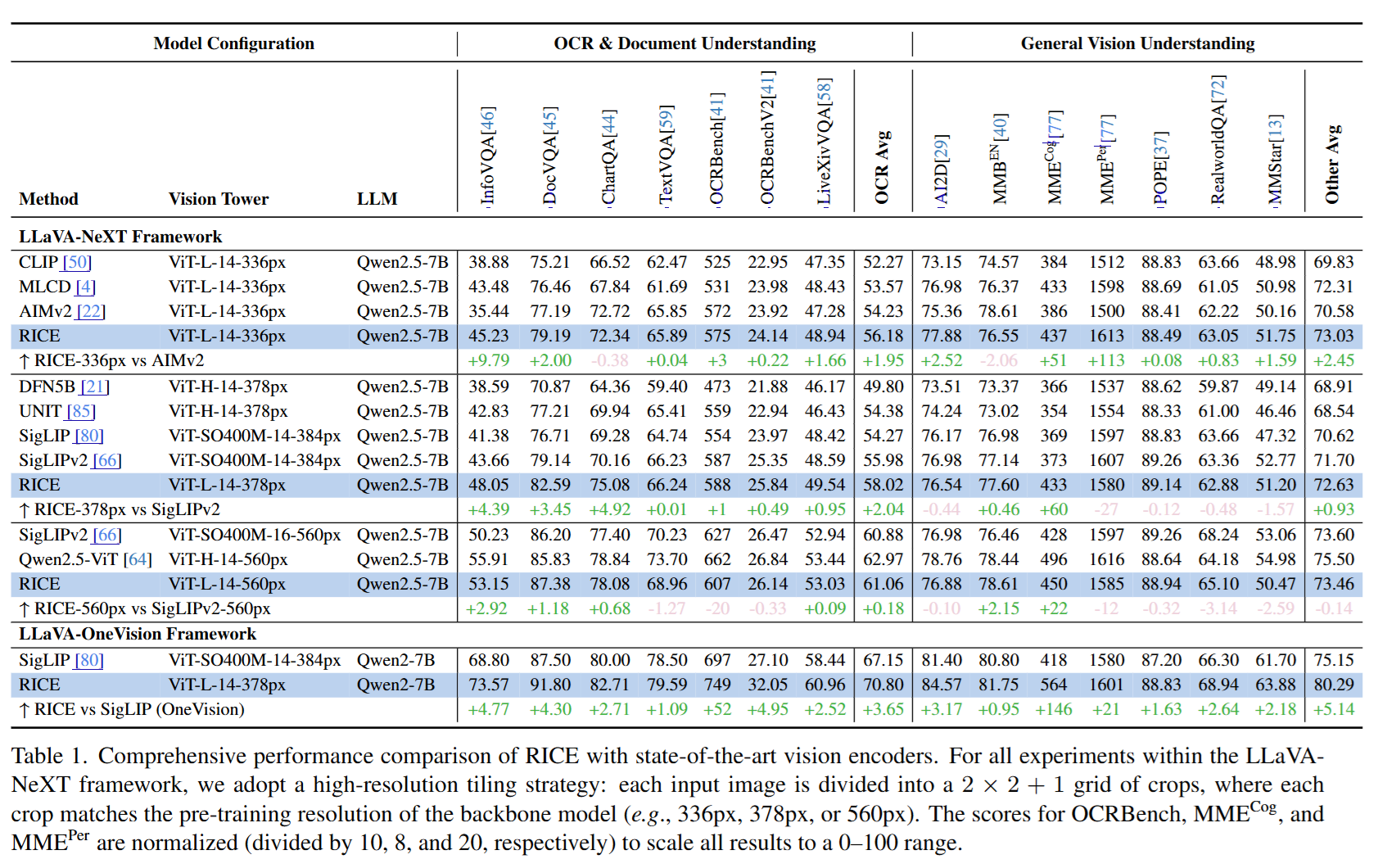
Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.
Community



Models citing this paper 1
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper