

Submitted by
 Juanxi
Juanxi
JuanxiGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
Juanxi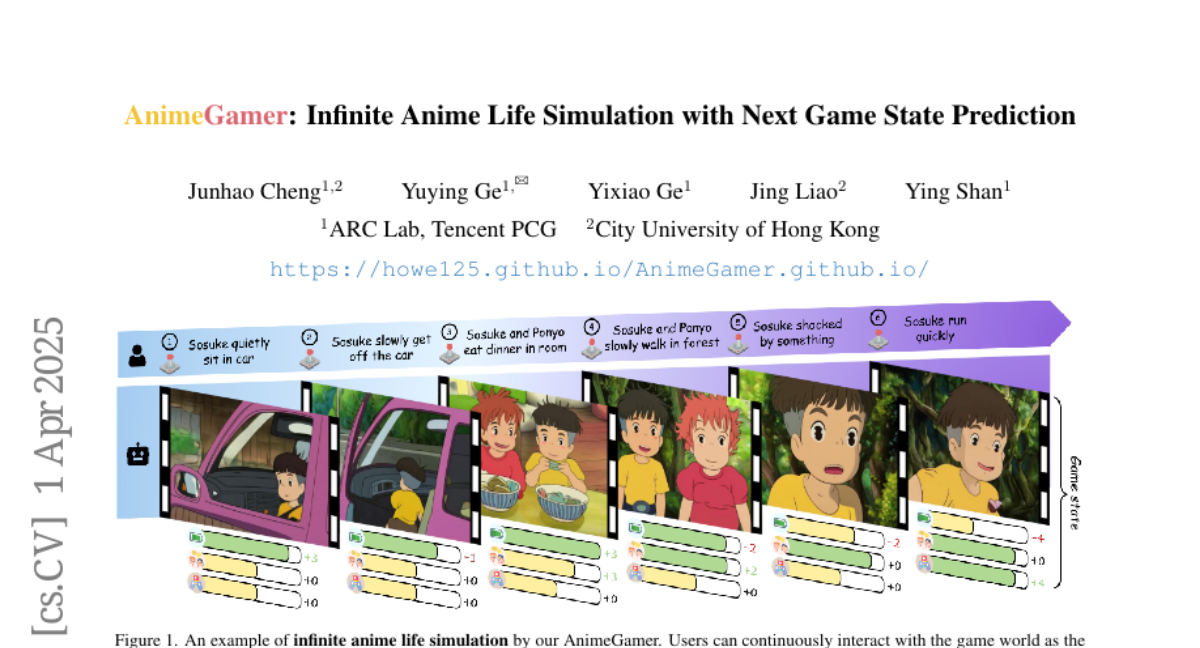
 Howe666
Howe666
 akhaliq
akhaliq
 zhijie3
zhijie3
 lkevinzc
lkevinzc
 wenhu
wenhu
 8ruceLi
8ruceLi hanyang-21
hanyang-21 akhaliq
akhaliq akhaliq
akhaliq
 huangrh9
huangrh9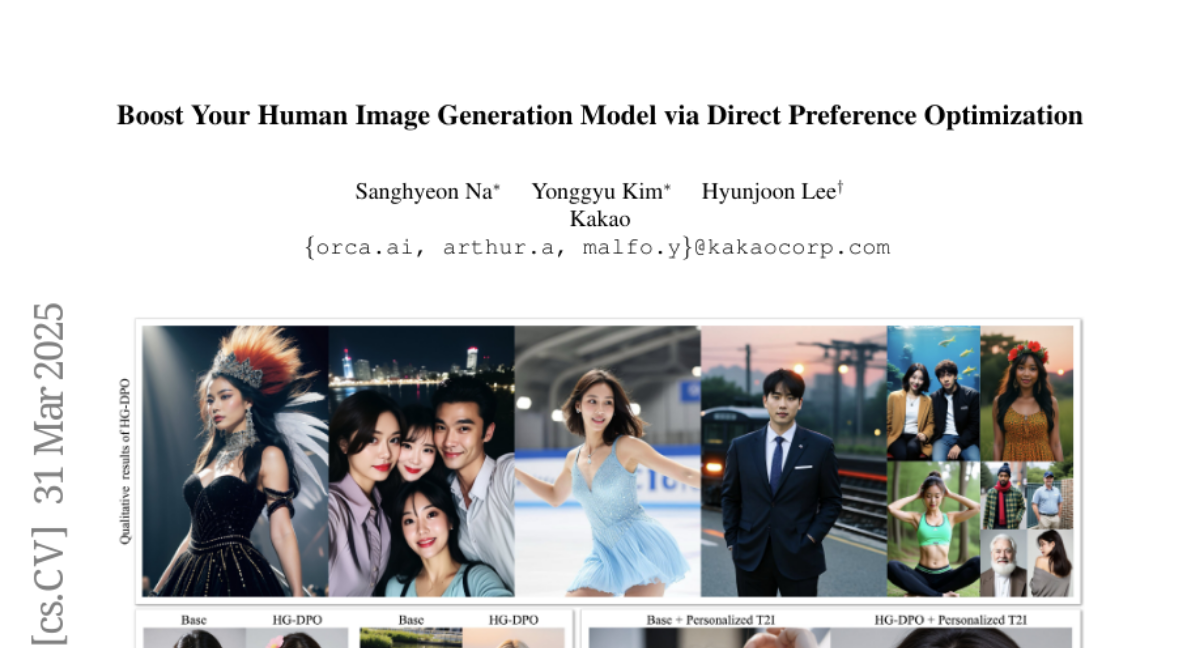
 AdinaY
AdinaY
 Jarvis1111
Jarvis1111
 nielsr
nielsr
 YanNeu
YanNeu
 jameslahm
jameslahm
 hychiang
hychiang
 Jiuzhouh
Jiuzhouh
 weizhiwang
weizhiwang Taeksoo
Taeksoo
 mawjdgus
mawjdgus
 KrithikV
KrithikV


























































