Abstract
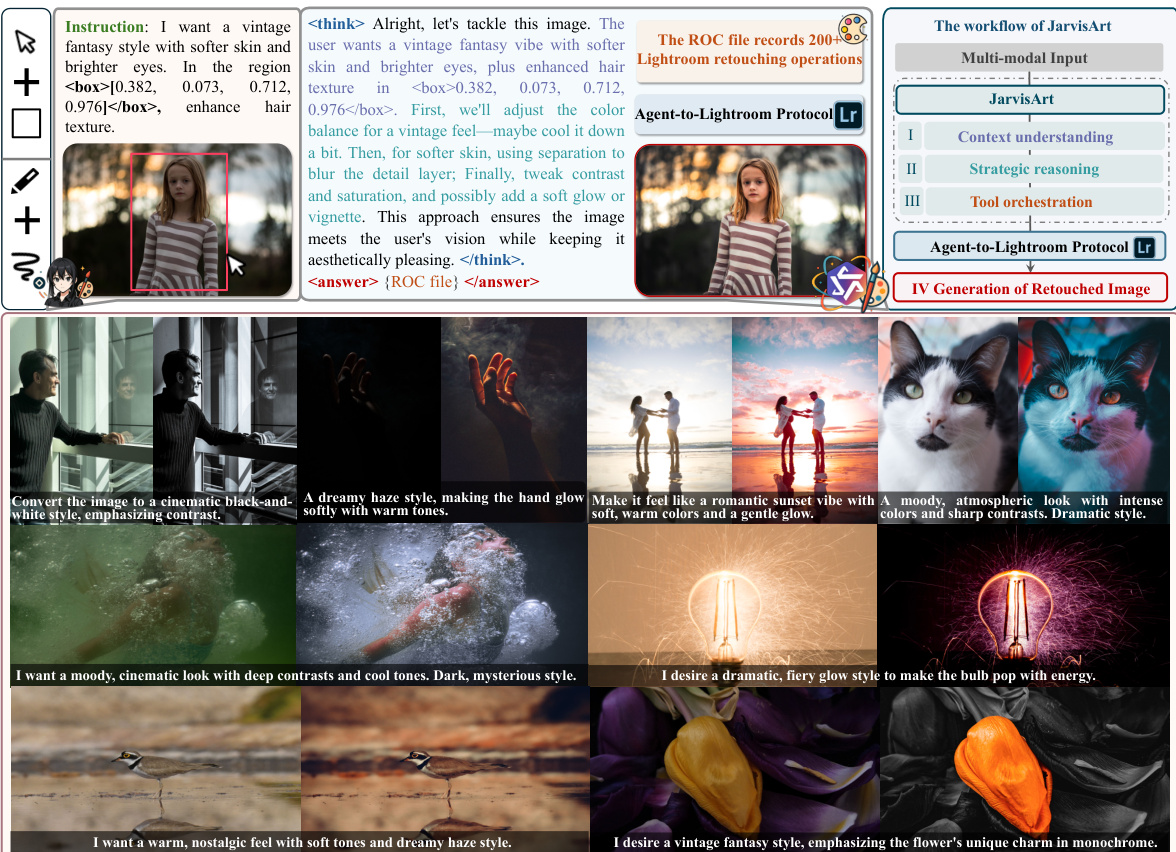
We introduce JarvisArt, a multi-modal large language model (MLLM)-driven agent that understands user intent, mimics professional artists' reasoning, and intelligently coordinates over 200 retouching tools within Lightroom. JarvisArt undergoes a two-stage training process and demonstrates user-friendly interaction, superior generalization, and fine-grained control over both global and local adjustments. Notably, it outperforms GPT-4o with a 60% improvement in average pixel-level metrics on our MMArt-Bench benchmark while maintaining comparable instruction-following capabilities.
Professional Reasoning
Mimics the reasoning process of professional artists through Chain-of-Thought supervised fine-tuning and GRPO-R optimization.
Comprehensive Toolset
Intelligently coordinates over 200 retouching tools within Lightroom for both global and local adjustments.
User-Friendly Interaction
Supports intuitive, free-form edits through natural inputs like text prompts, bounding boxes, or brushstrokes.