
Qwen3-MegaScience
Collection
Qwen3-MegaScience
•
5 items
•
Updated
•
4
This repository contains the Qwen3-1.7B-MegaScience model, which is part of the research presented in the paper titled "MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning".
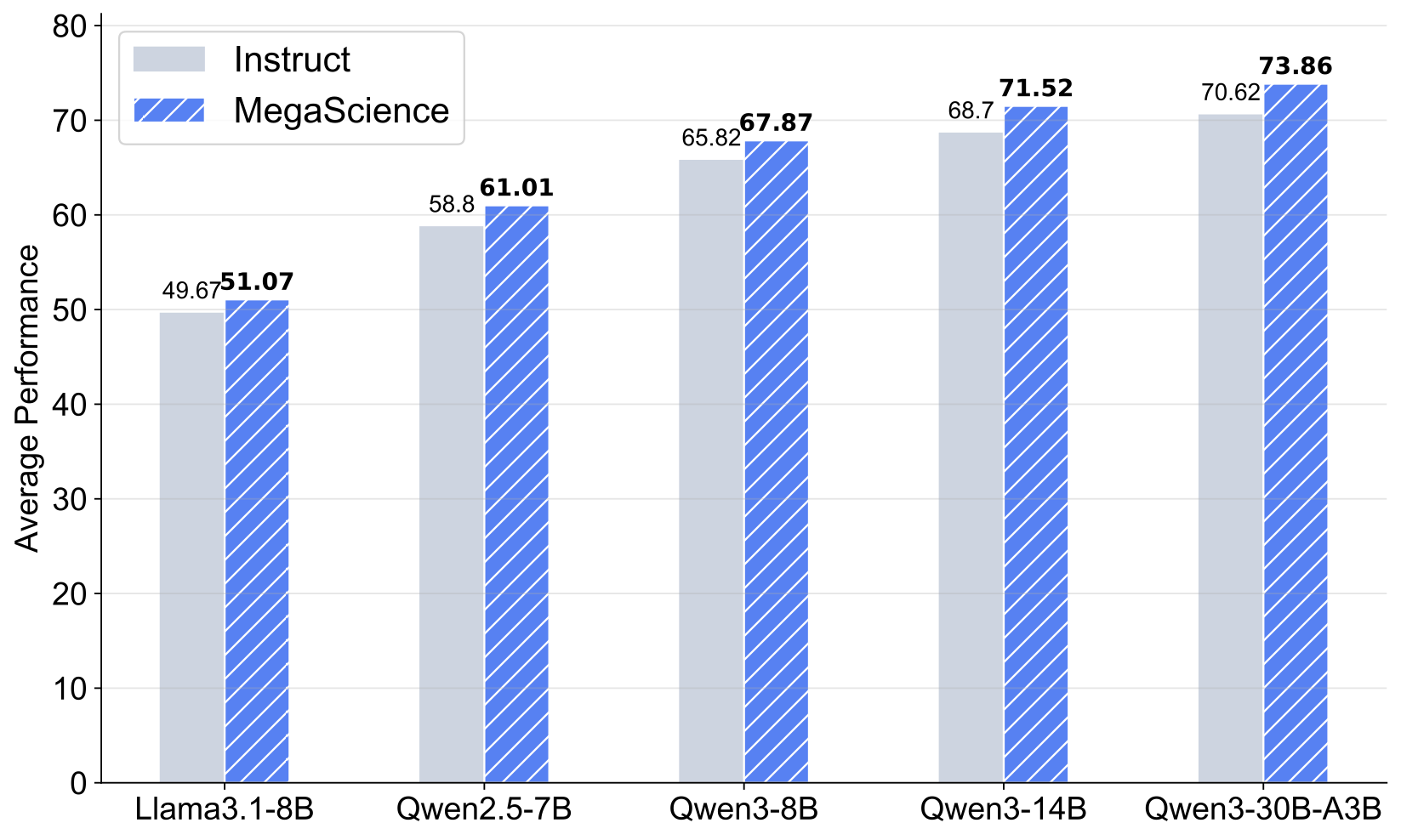
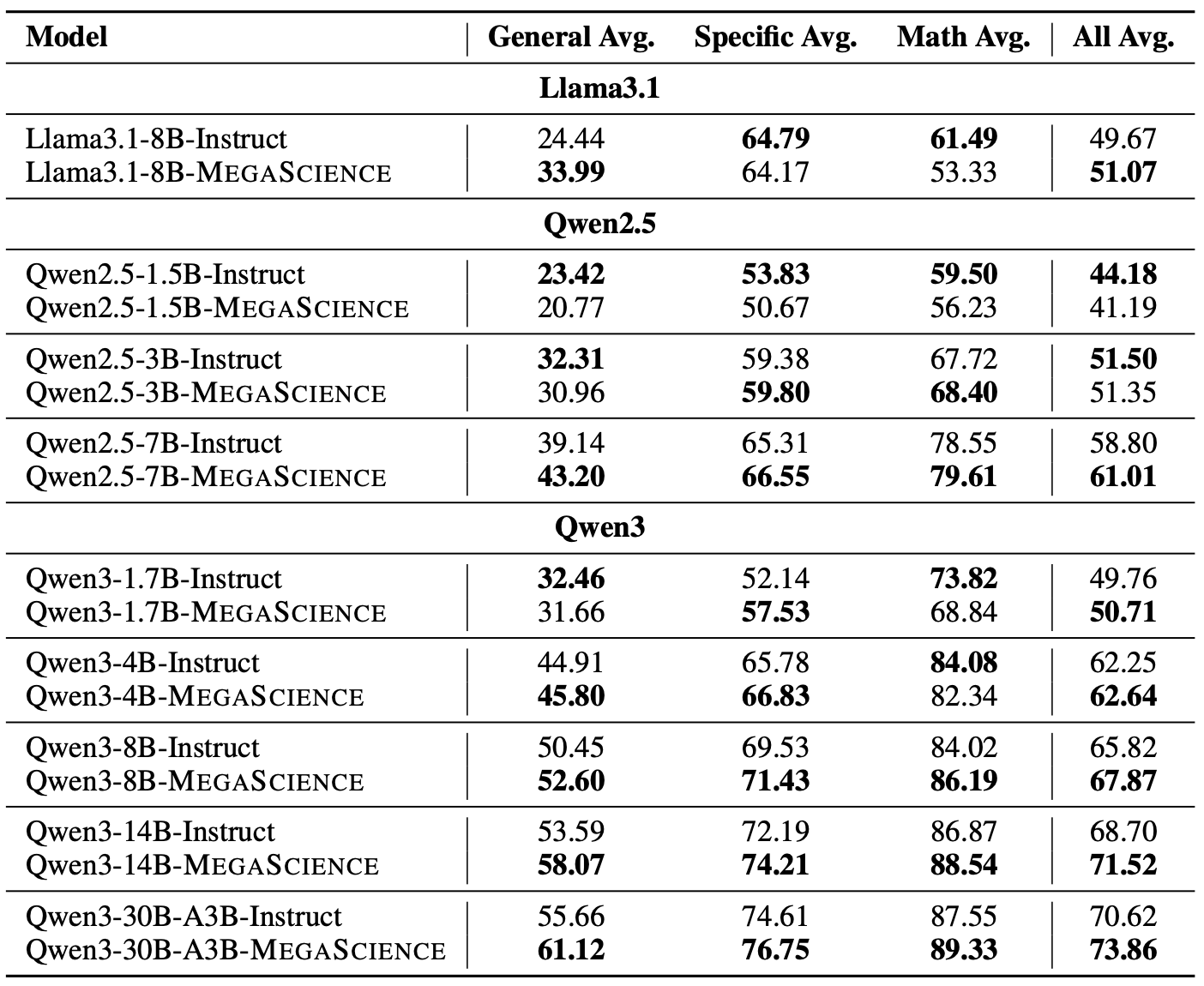
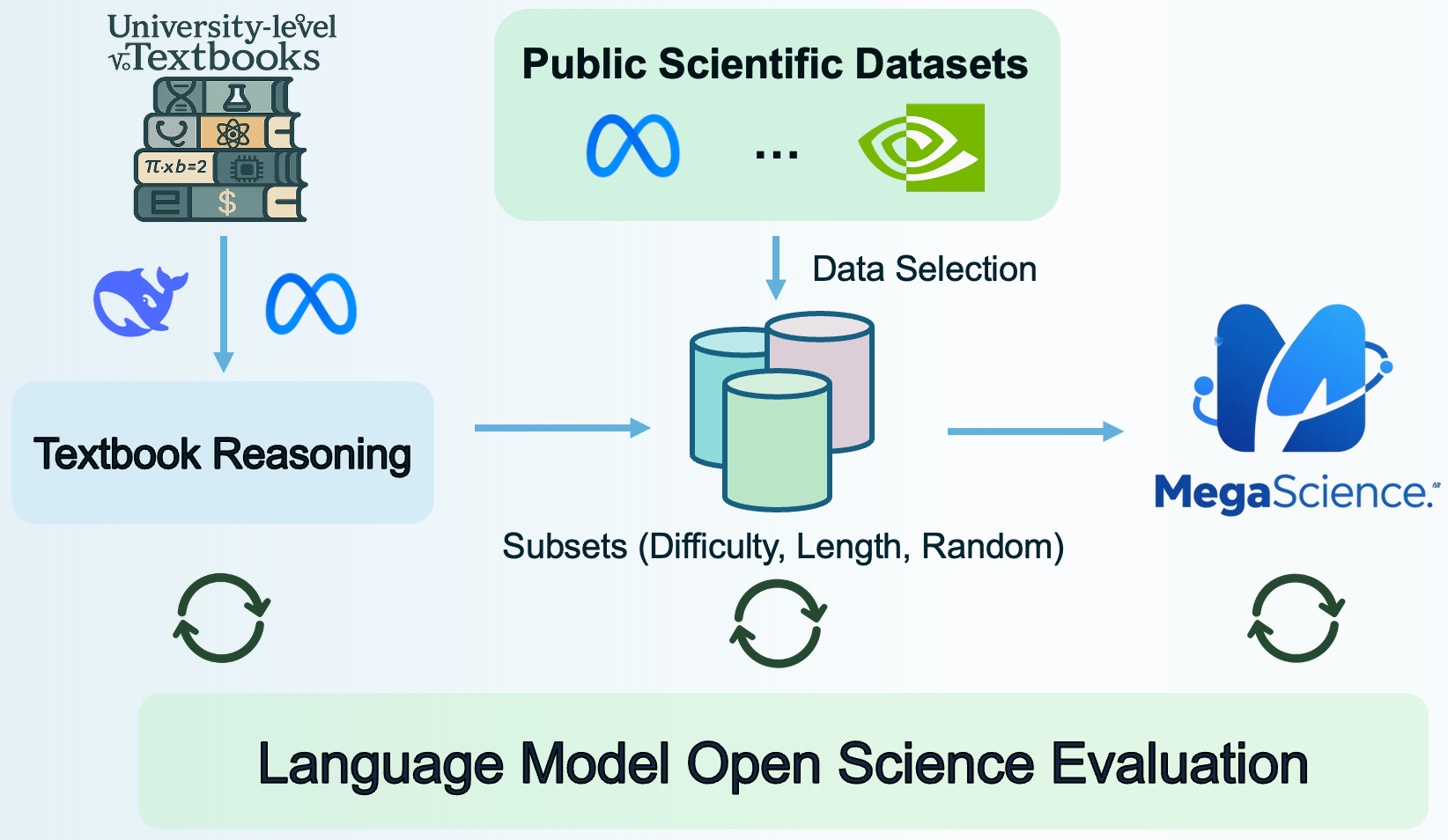
Scientific reasoning is critical for developing AI scientists and supporting human researchers in advancing the frontiers of natural science discovery. However, the open-source community has primarily focused on mathematics and coding while neglecting the scientific domain, largely due to the absence of open, large-scale, high-quality, verifiable scientific reasoning datasets. To bridge this gap, we first present TextbookReasoning, an open dataset featuring truthful reference answers extracted from 12k university-level scientific textbooks, comprising 650k reasoning questions spanning 7 scientific disciplines. We further introduce MegaScience, a large-scale mixture of high-quality open-source datasets totaling 1.25 million instances, developed through systematic ablation studies that evaluate various data selection methodologies to identify the optimal subset for each publicly available scientific dataset. Meanwhile, we build a comprehensive evaluation system covering diverse subjects and question types across 15 benchmarks, incorporating comprehensive answer extraction strategies to ensure accurate evaluation metrics. Our experiments demonstrate that our datasets achieve superior performance and training efficiency with more concise response lengths compared to existing open-source scientific datasets. Furthermore, we train Llama3.1, Qwen2.5, and Qwen3 series base models on MegaScience, which significantly outperform the corresponding official instruct models in average performance. In addition, MegaScience exhibits greater effectiveness for larger and stronger models, suggesting a scaling benefit for scientific tuning. We release our data curation pipeline, evaluation system, datasets, and seven trained models to the community to advance scientific reasoning research.
The official code and data processing pipeline can be found at the MegaScience GitHub repository.
This model can be loaded and used directly with the Hugging Face transformers library. Since this is a Qwen-based model, it supports the chat template for structured conversations.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "MegaScience/Qwen3-1.7B-MegaScience"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it, otherwise float16
device_map="auto",
)
messages = [
{"role": "user", "content": "What is the primary function of mitochondria?\
Answer:"},
]
# Apply chat template and generate response
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.7,
top_p=0.9,
eos_token_id=tokenizer.eos_token_id,
)
generated_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(generated_text)
Check out our paper for more details. If you use our dataset or find our work useful, please cite
@article{fan2025megascience,
title={MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning},
author={Fan, Run-Ze and Wang, Zengzhi and Liu, Pengfei},
year={2025},
journal={arXiv preprint arXiv:2507.16812},
url={https://arxiv.org/abs/2507.16812}
}
Base model
Qwen/Qwen3-1.7B-Base