
Lucy
Collection
4 items
•
Updated
•
15

Authors: Alan Dao, Bach Vu Dinh, Alex Nguyen, Norapat Buppodom

Lucy is a compact but capable 1.7B model focused on agentic web search and lightweight browsing. Built on Qwen3-1.7B, Lucy inherits deep research capabilities from larger models while being optimized to run efficiently on mobile devices, even with CPU-only configurations.
We achieved this through machine-generated task vectors that optimize thinking processes, smooth reward functions across multiple categories, and pure reinforcement learning without any supervised fine-tuning.
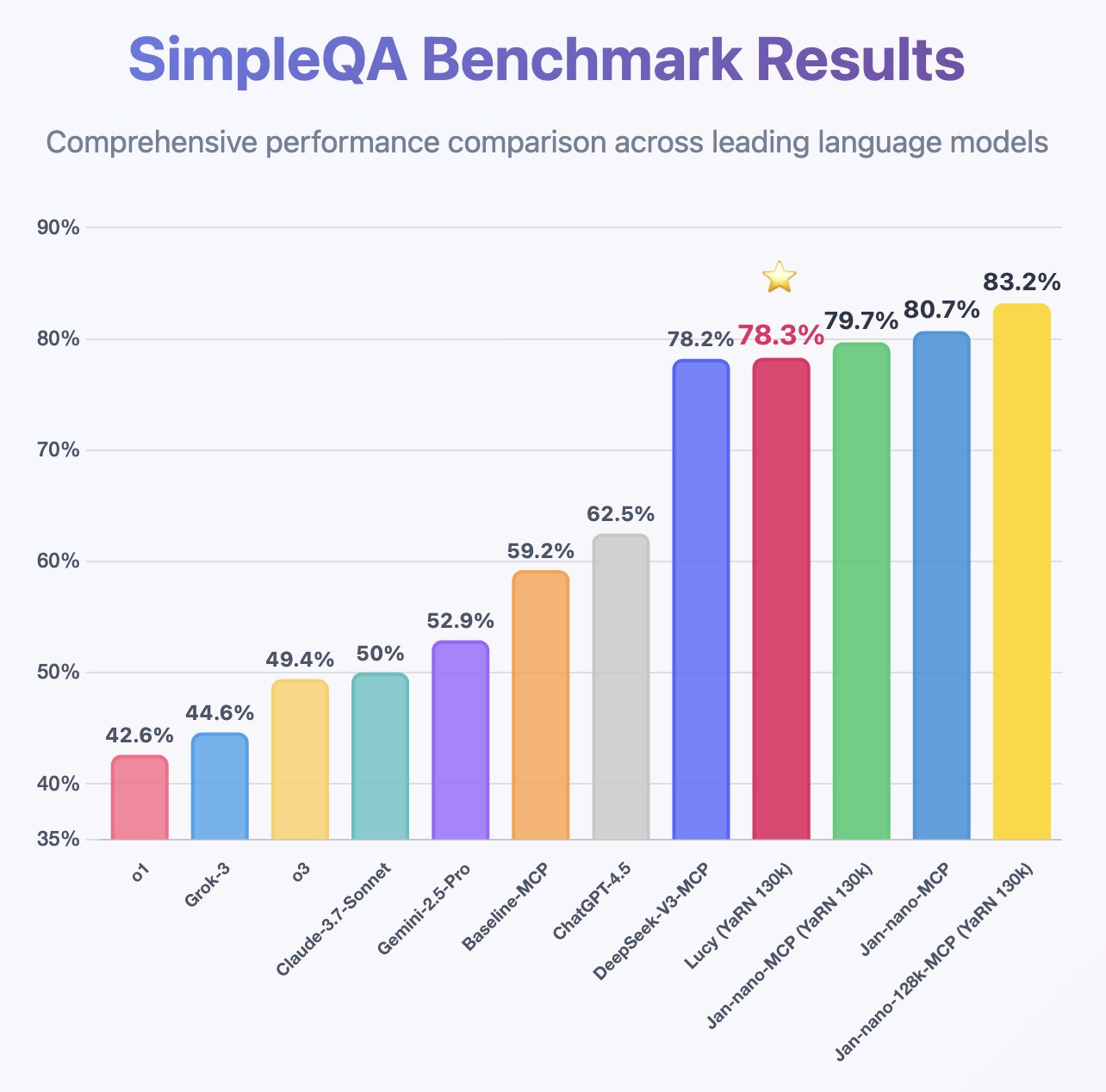
Following the same MCP benchmark methodology used for Jan-Nano and Jan-Nano-128k, Lucy demonstrates impressive performance despite being only a 1.7B model, achieving higher accuracy than DeepSeek-v3 on SimpleQA.
Lucy can be deployed using various methods including vLLM, llama.cpp, or through local applications like Jan, LMStudio, and other compatible inference engines. The model supports integration with search APIs and web browsing tools through the MCP.
Deploy using VLLM:
vllm serve Menlo/Lucy-128k \
--host 0.0.0.0 \
--port 1234 \
--enable-auto-tool-choice \
--tool-call-parser hermes
Or llama-server from llama.cpp:
llama-server ...
Temperature: 0.7
Top-p: 0.9
Top-k: 20
Min-p: 0.0
@misc{dao2025lucyedgerunningagenticweb,
title={Lucy: edgerunning agentic web search on mobile with machine generated task vectors},
author={Alan Dao and Dinh Bach Vu and Alex Nguyen and Norapat Buppodom},
year={2025},
eprint={2508.00360},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.00360},
}
**Paper **: Lucy: edgerunning agentic web search on mobile with machine generated task vectors.
3-bit
4-bit
5-bit
6-bit
8-bit