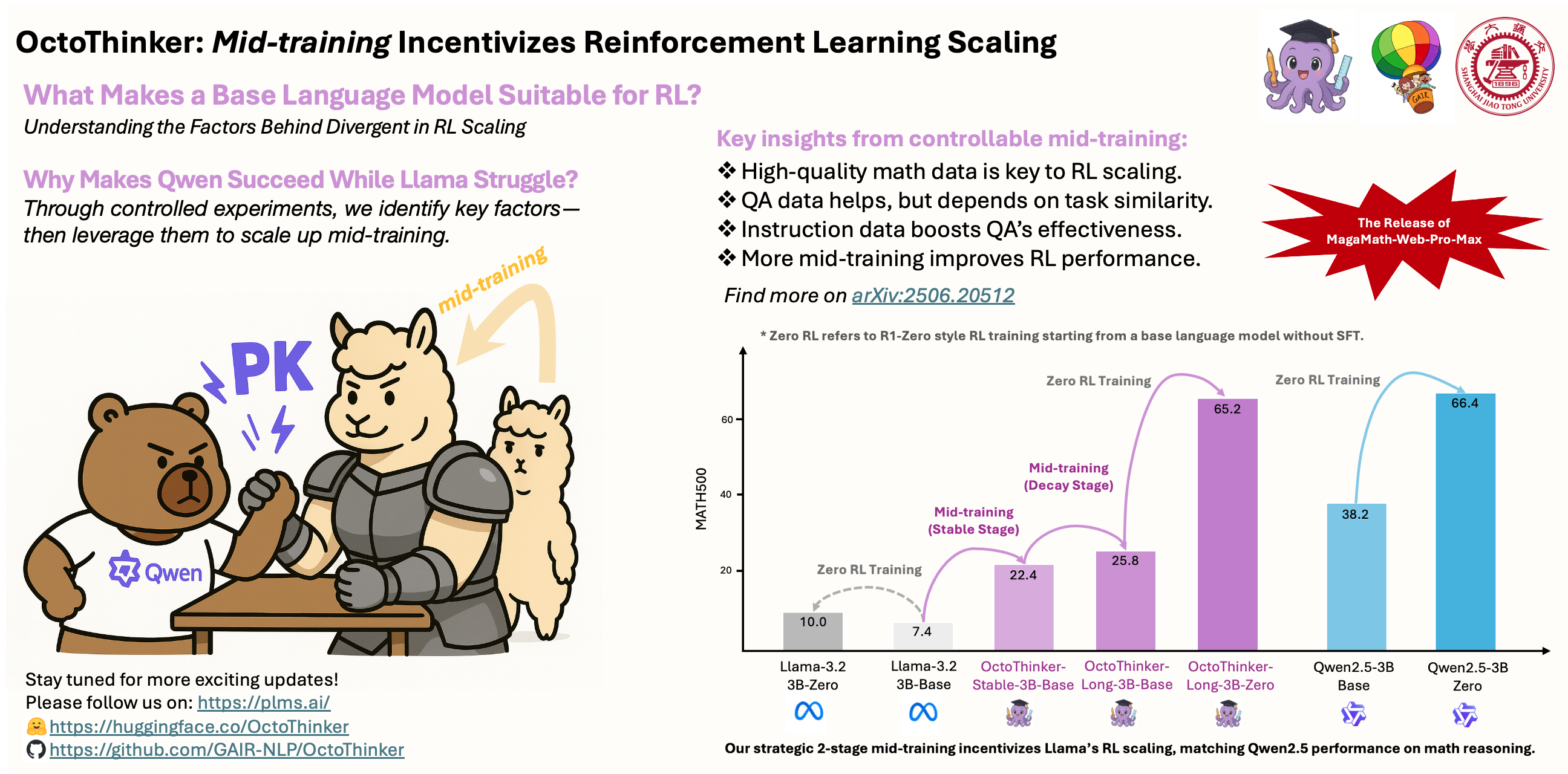
OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling
OctoThinker-3B-Hybrid-Zero
The OctoThinker family is built on carefully studied mid-training insights, starting from the Llama-3 family, to create a reinforcement learning–friendly base language model.
OctoThinker-3B-Hybrid-Zero is trained using the R1-Zero-style reinforcement learning technique, starting from OctoThinker-3B-Hybrid-Base without any supervised fine-tuning (SFT).
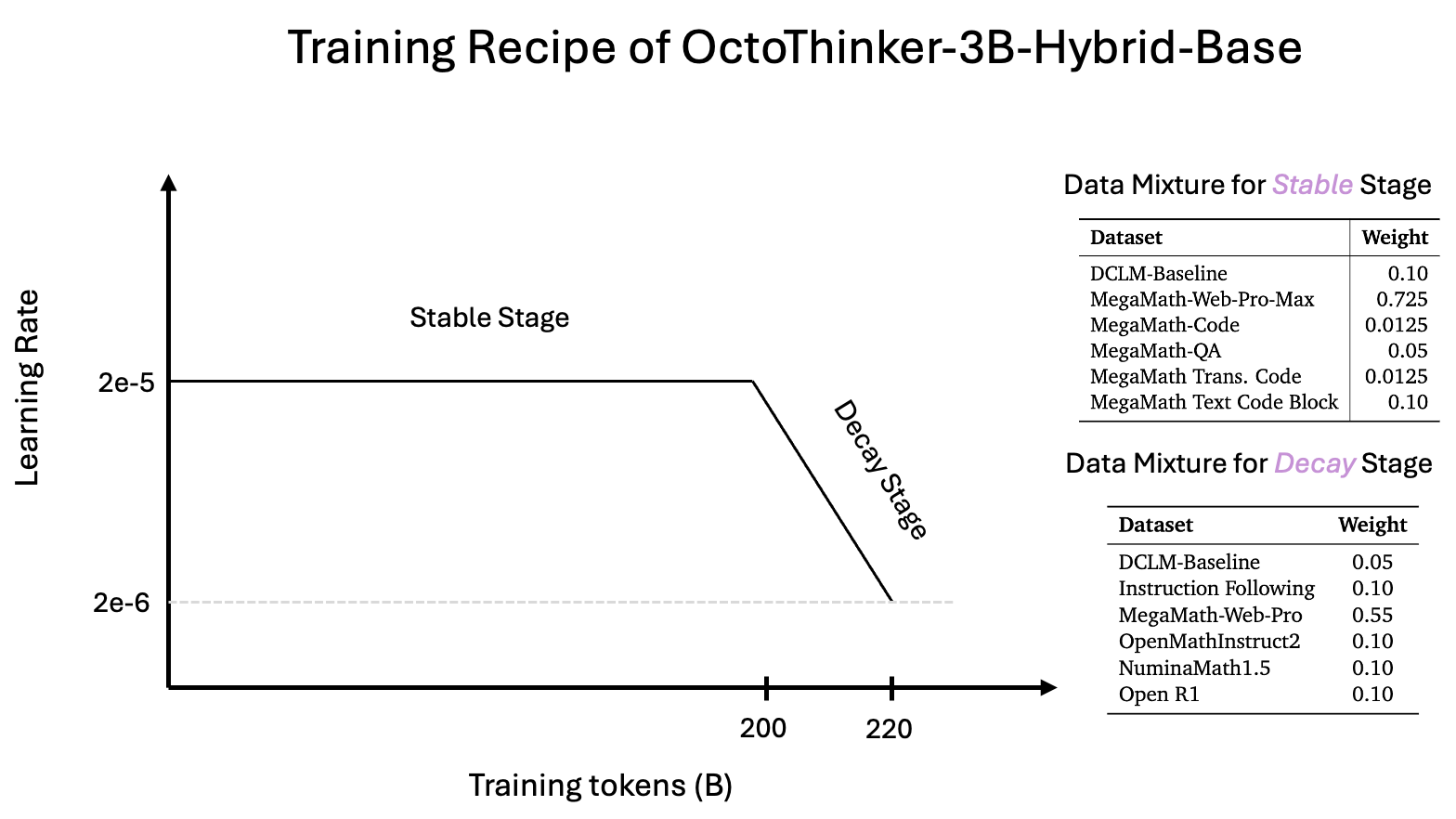
Training Recipe for OctoThinker-3B-Hybrid-Base
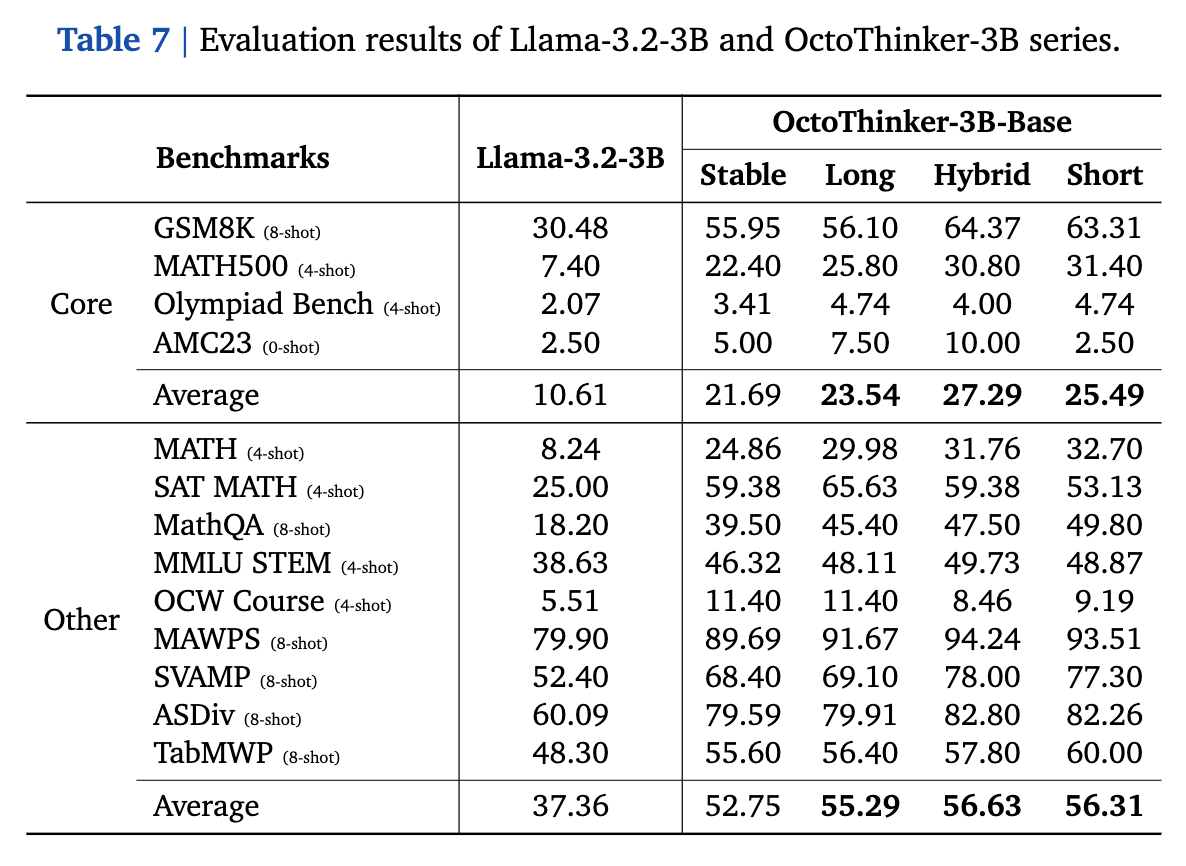
Evaluation Results of OctoThinker-3B-Base Series
Note that we adopt the few-shot prompting evaluation for these base language models.
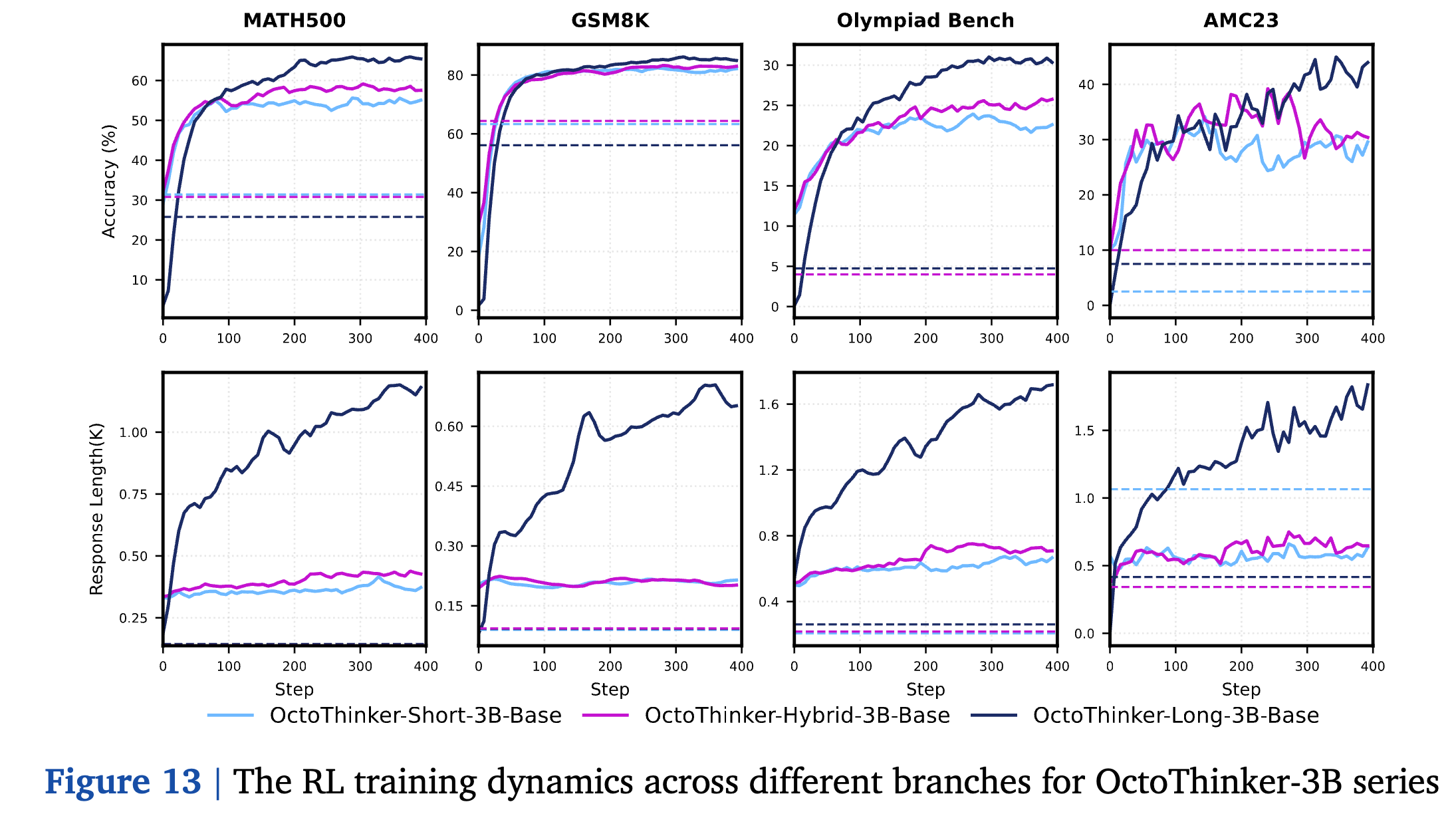
RL Training Dynamics of OctoThinker-3B-Zero Series
More about OctoThinker
Citation
Check out our paper for more details. If you use our models, datasets or find our work useful, please cite
@article{wang2025octothinker,
title={OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling},
author={Wang, Zengzhi and Zhou, Fan and Li, Xuefeng and Liu, Pengfei},
year={2025},
journal={arXiv preprint arXiv:2506.20512},
note={Preprint}
}