
{kind=link}
Wan2.2
Collection
5 items
•
Updated
•
61
![]()
💜 Wan | 🖥️ GitHub | 🤗 Hugging Face | 🤖 ModelScope | 📑 Technical Report | 📑 Blog | 💬 WeChat Group | 📖 Discord
Wan: Open and Advanced Large-Scale Video Generative Models
We are excited to introduce Wan2.2, a major upgrade to our foundational video models. With Wan2.2, we have focused on incorporating the following innovations:
👍 Effective MoE Architecture: Wan2.2 introduces a Mixture-of-Experts (MoE) architecture into video diffusion models. By separating the denoising process cross timesteps with specialized powerful expert models, this enlarges the overall model capacity while maintaining the same computational cost.
👍 Cinematic-level Aesthetics: Wan2.2 incorporates meticulously curated aesthetic data, complete with detailed labels for lighting, composition, contrast, color tone, and more. This allows for more precise and controllable cinematic style generation, facilitating the creation of videos with customizable aesthetic preferences.
👍 Complex Motion Generation: Compared to Wan2.1, Wan2.2 is trained on a significantly larger data, with +65.6% more images and +83.2% more videos. This expansion notably enhances the model's generalization across multiple dimensions such as motions, semantics, and aesthetics, achieving TOP performance among all open-sourced and closed-sourced models.
👍 Efficient High-Definition Hybrid TI2V: Wan2.2 open-sources a 5B model built with our advanced Wan2.2-VAE that achieves a compression ratio of 16×16×4. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can also run on consumer-grade graphics cards like 4090. It is one of the fastest 720P@24fps models currently available, capable of serving both the industrial and academic sectors simultaneously.
This repository contains our TI2V-5B model, built with the advanced Wan2.2-VAE that achieves a compression ratio of 16×16×4. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can runs on single consumer-grade GPU such as the 4090. It is one of the fastest 720P@24fps models available, meeting the needs of both industrial applications and academic research.
If your research or project builds upon Wan2.1 or Wan2.2, we welcome you to share it with us so we can highlight it for the broader community.
Clone the repo:
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
Install dependencies:
# Ensure torch >= 2.4.0
pip install -r requirements.txt
| Models | Download Links | Description |
|---|---|---|
| T2V-A14B | 🤗 Huggingface 🤖 ModelScope | Text-to-Video MoE model, supports 480P & 720P |
| I2V-A14B | 🤗 Huggingface 🤖 ModelScope | Image-to-Video MoE model, supports 480P & 720P |
| TI2V-5B | 🤗 Huggingface 🤖 ModelScope | High-compression VAE, T2V+I2V, supports 720P |
💡Note: The TI2V-5B model supports 720P video generation at 24 FPS.
Download models using huggingface-cli:
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-TI2V-5B --local-dir ./Wan2.2-TI2V-5B
Download models using modelscope-cli:
pip install modelscope
modelscope download Wan-AI/Wan2.2-TI2V-5B --local_dir ./Wan2.2-TI2V-5B
This repository supports the Wan2.2-TI2V-5B Text-Image-to-Video model and can support video generation at 720P resolutions.
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage"
💡Unlike other tasks, the 720P resolution of the Text-Image-to-Video task is
1280*704or704*1280.
This command can run on a GPU with at least 24GB VRAM (e.g, RTX 4090 GPU).
💡If you are running on a GPU with at least 80GB VRAM, you can remove the
--offload_model True,--convert_model_dtypeand--t5_cpuoptions to speed up execution.
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
💡If the image parameter is configured, it is an Image-to-Video generation; otherwise, it defaults to a Text-to-Video generation.
💡Similar to Image-to-Video, the
sizeparameter represents the area of the generated video, with the aspect ratio following that of the original input image.
torchrun --nproc_per_node=8 generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --dit_fsdp --t5_fsdp --ulysses_size 8 --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
The process of prompt extension can be referenced here.
We test the computational efficiency of different Wan2.2 models on different GPUs in the following table. The results are presented in the format: Total time (s) / peak GPU memory (GB).

The parameter settings for the tests presented in this table are as follows: (1) Multi-GPU: 14B:
--ulysses_size 4/8 --dit_fsdp --t5_fsdp, 5B:--ulysses_size 4/8 --offload_model True --convert_model_dtype --t5_cpu; Single-GPU: 14B:--offload_model True --convert_model_dtype, 5B:--offload_model True --convert_model_dtype --t5_cpu(--convert_model_dtype converts model parameter types to config.param_dtype); (2) The distributed testing utilizes the built-in FSDP and Ulysses implementations, with FlashAttention3 deployed on Hopper architecture GPUs; (3) Tests were run without the--use_prompt_extendflag; (4) Reported results are the average of multiple samples taken after the warm-up phase.
Wan2.2 builds on the foundation of Wan2.1 with notable improvements in generation quality and model capability. This upgrade is driven by a series of key technical innovations, mainly including the Mixture-of-Experts (MoE) architecture, upgraded training data, and high-compression video generation.
Wan2.2 introduces Mixture-of-Experts (MoE) architecture into the video generation diffusion model. MoE has been widely validated in large language models as an efficient approach to increase total model parameters while keeping inference cost nearly unchanged. In Wan2.2, the A14B model series adopts a two-expert design tailored to the denoising process of diffusion models: a high-noise expert for the early stages, focusing on overall layout; and a low-noise expert for the later stages, refining video details. Each expert model has about 14B parameters, resulting in a total of 27B parameters but only 14B active parameters per step, keeping inference computation and GPU memory nearly unchanged.

The transition point between the two experts is determined by the signal-to-noise ratio (SNR), a metric that decreases monotonically as the denoising step $t$ increases. At the beginning of the denoising process, $t$ is large and the noise level is high, so the SNR is at its minimum, denoted as ${SNR}{min}$. In this stage, the high-noise expert is activated. We define a threshold step ${t}{moe}$ corresponding to half of the ${SNR}{min}$, and switch to the low-noise expert when $t<{t}{moe}$.

To validate the effectiveness of the MoE architecture, four settings are compared based on their validation loss curves. The baseline Wan2.1 model does not employ the MoE architecture. Among the MoE-based variants, the Wan2.1 & High-Noise Expert reuses the Wan2.1 model as the low-noise expert while uses the Wan2.2's high-noise expert, while the Wan2.1 & Low-Noise Expert uses Wan2.1 as the high-noise expert and employ the Wan2.2's low-noise expert. The Wan2.2 (MoE) (our final version) achieves the lowest validation loss, indicating that its generated video distribution is closest to ground-truth and exhibits superior convergence.
To enable more efficient deployment, Wan2.2 also explores a high-compression design. In addition to the 27B MoE models, a 5B dense model, i.e., TI2V-5B, is released. It is supported by a high-compression Wan2.2-VAE, which achieves a $T\times H\times W$ compression ratio of $4\times16\times16$, increasing the overall compression rate to 64 while maintaining high-quality video reconstruction. With an additional patchification layer, the total compression ratio of TI2V-5B reaches $4\times32\times32$. Without specific optimization, TI2V-5B can generate a 5-second 720P video in under 9 minutes on a single consumer-grade GPU, ranking among the fastest 720P@24fps video generation models. This model also natively supports both text-to-video and image-to-video tasks within a single unified framework, covering both academic research and practical applications.

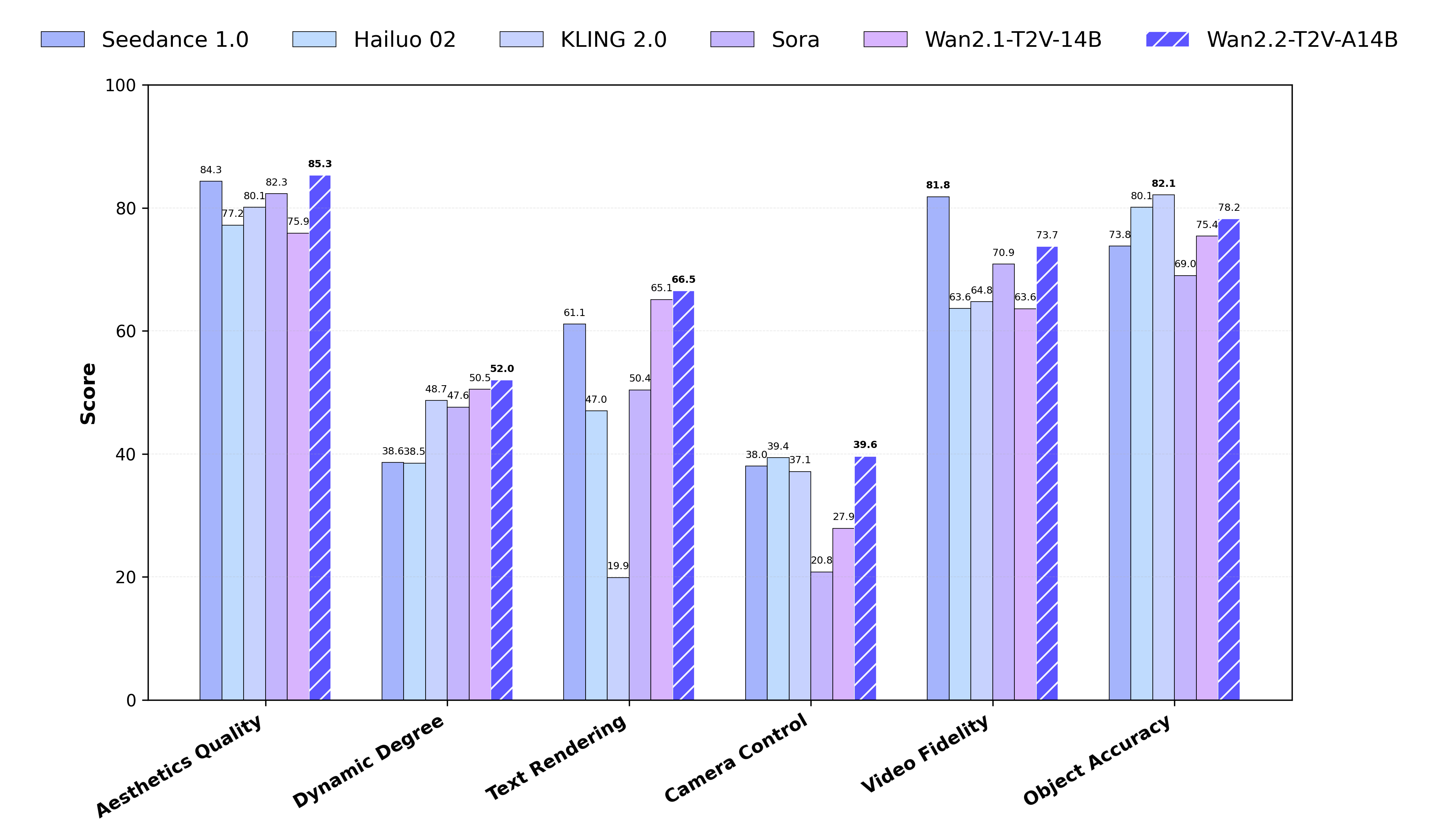
We compared Wan2.2 with leading closed-source commercial models on our new Wan-Bench 2.0, evaluating performance across multiple crucial dimensions. The results demonstrate that Wan2.2 achieves superior performance compared to these leading models.
If you find our work helpful, please cite us.
@article{wan2025,
title={Wan: Open and Advanced Large-Scale Video Generative Models},
author={Team Wan and Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
journal = {arXiv preprint arXiv:2503.20314},
year={2025}
}
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the license.
We would like to thank the contributors to the SD3, Qwen, umt5-xxl, diffusers and HuggingFace repositories, for their open research.
If you would like to leave a message to our research or product teams, feel free to join our Discord or WeChat groups!