LID-gemma-2-2B-M4ABS
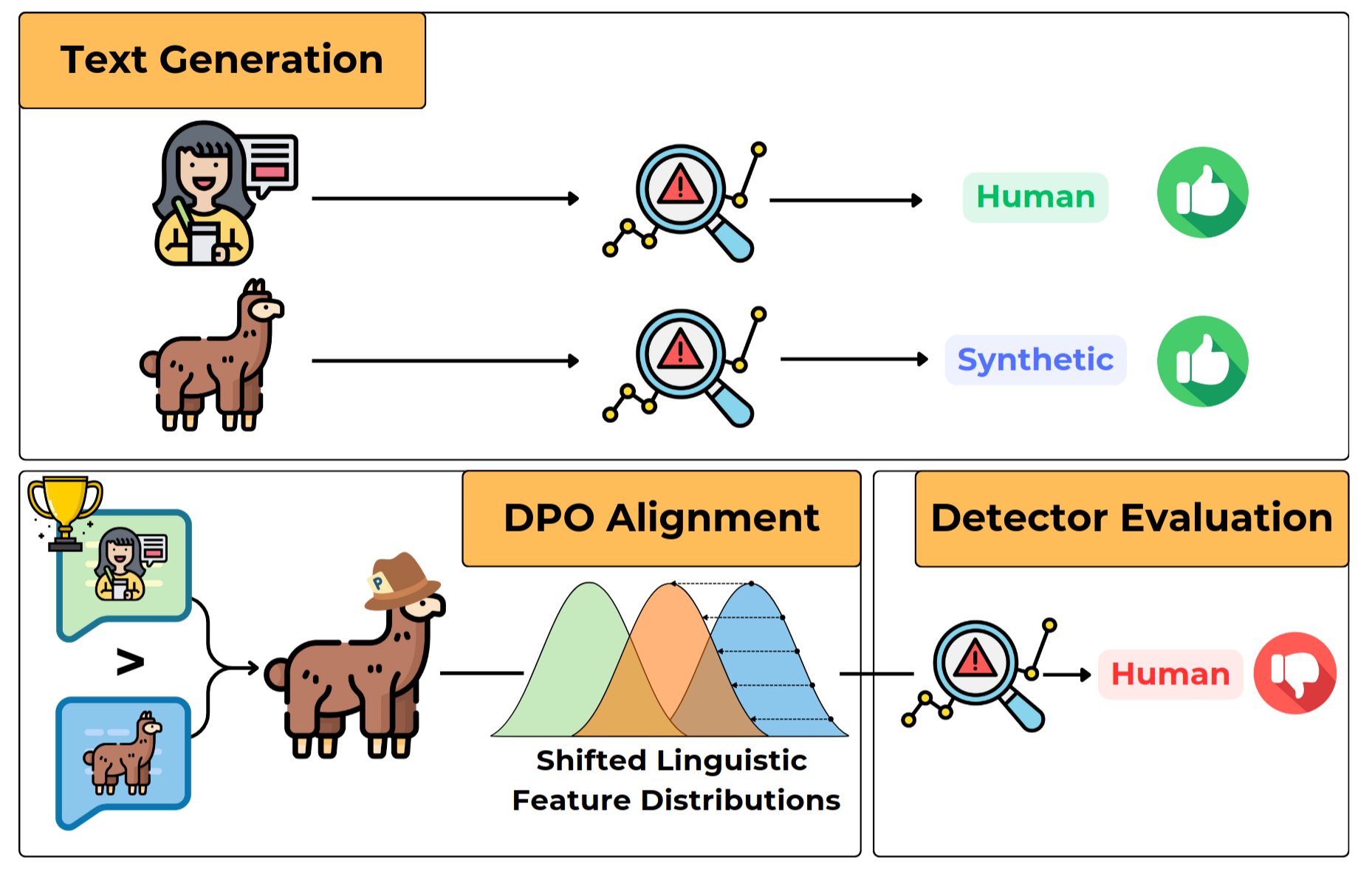
The LoRa adapters for the LID-gemma-2-2B LLM. This model has been fine-tuned using DPO to align its writing style with the distribution of linguistic features profiled in human-written texts (HWT) sampled from the Abstract subset of the M4 dataset, a corpus of scientific abstracts.
- Developed by: AI4Text @CNR-ISTI, ItaliaNLP @CNR-ILC
- Model type: LoRA adapters (different iterations are stored in branches)
- Finetuned from model:
google/gemma-2-2b-it
Uses
This model is intended to be used as a adversarial samples generator. The model can be used to either generate sampels to benchmark current Machine-Generated-Text Detectors, or to augment the training set of novel approaches to syntethic text detection.
How to Get Started with the Model
Use the code below to get started with the model.
from peft import PeftModel
from transformers import AutoModelForCausalLM
base_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it")
model = PeftModel.from_pretrained(base_model, "andreapdr/LID-gemma-2-2b-M4ABS-ling", revision="main")
Training Details
Training Data
The model has been fine-tuned on the LID-M4ABS dataset, based on the ArXiv subset of the M4 dataset. We provide pre-trained LoRA adapters for two iterations, stored in different branches.
Training Procedure
DPO fine-tuning with LoRA Adapters
LoraConfig(
r=32 ,
lora_alpha=16 ,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
bias="none" ,
lora_dropout=0.05,
task_type="CAUSAL_LM"
)
Model prompt:
- System Prompt:: "You are a journalist from the United Kingdom writing for a national newspaper on a broad range of topics."
- User Prompt:: "Write a piece of news, that will appear in a national news-papers in the UK and that has the following title:
title. In writing avoid any kind of formatting, do not repeat the title and keep the text informative and not vague. You don’t have to add the date of the event but you can, use at most 500 words"
Training Hyperparameters
- Learning Rate: {5e−7, 5e−6}
- Beta:: {0.1, 0.5, 1.0}
Framework versions
Citation
if you use part of this work, please consider citing the paper as follows:
@misc{pedrotti2025stresstestingMGT,
title={Stress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool Detectors},
author={Andrea Pedrotti and Michele Papucci and Cristiano Ciaccio and Alessio Miaschi and Giovanni Puccetti and Felice Dell'Orletta and Andrea Esuli},
year={2025},
eprint={2505.24523},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.24523},
}