
Using tags?

Hello,
How can I use the tags such as [laugh], [music] and more that were featured in the video?
I tried generating the following:
[music] Bitte haben Sie Geduld. Ein Mitarbeiter ist gleich für Sie da.
But no music appeared

Will it work better if you try the following prompting method? The model has not gone through finetuning and it is currently sensitive to the choice of prompt when it comes to its understanding of the sound event tags.
Here's what I just tried in the playground and seem to work better. I set the following in the system message to explicitly mention that the audio will contain background music.
Generate audio following instruction.
<|scene_desc_start|>
Audio contains background music.
<|scene_desc_end|>
Afterwards, I put the following to the user message:
[music start] Bitte haben Sie Geduld. Ein Mitarbeiter ist gleich für Sie da. [music end]
I used sampling hyper-parameter as shown in the following screenshot.
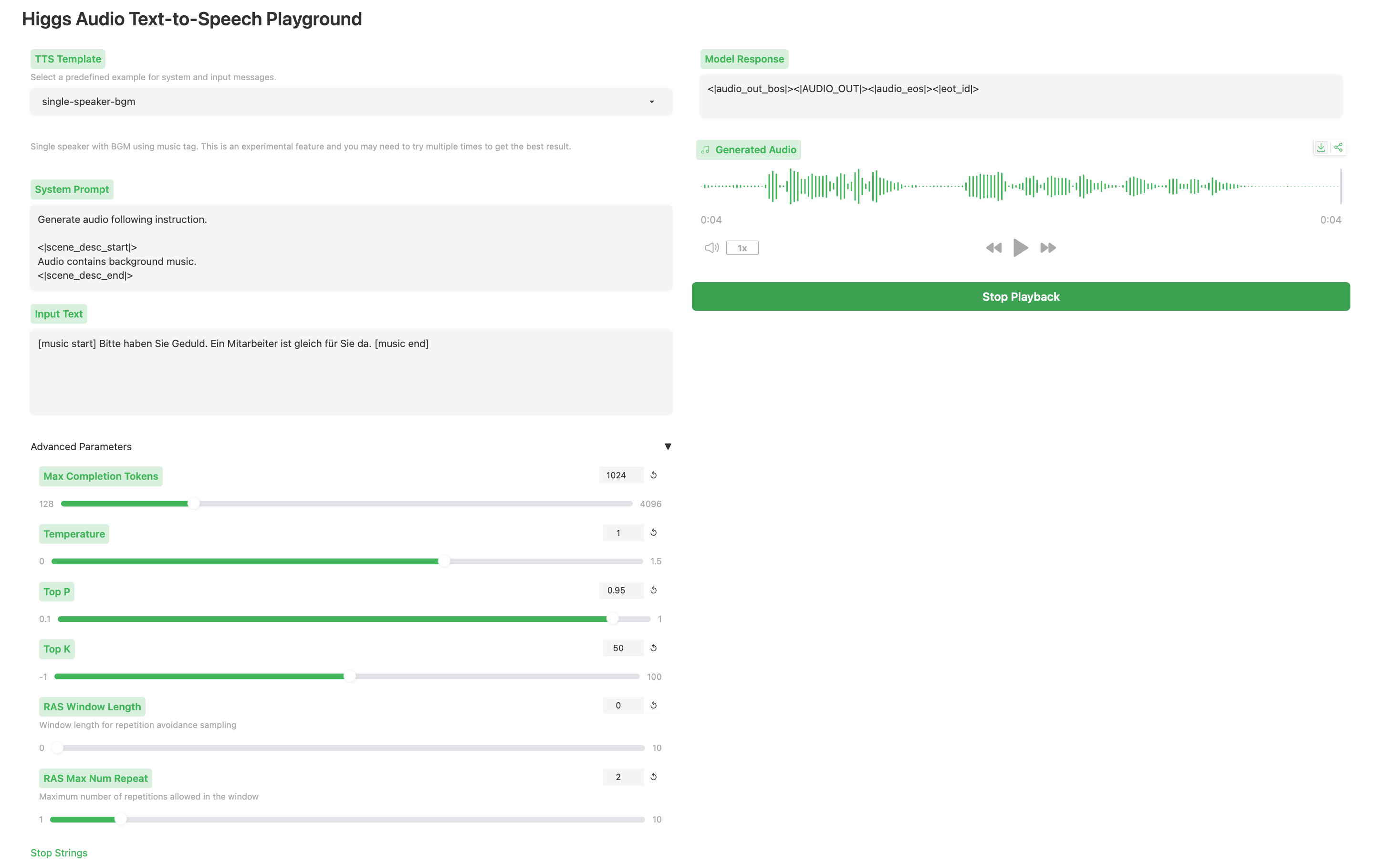
This is the output I get
When we pretrain Higgs Audio v2, we constructed acoustic and semantic descriptions of the audio and put them to the system message. The default in the playground is Audio is recorded from a quiet room. , which may conflict with audio that contains background music.
Music generation now works fine! :)
It seems like I needed to use "single-speaker-bgm" instead of "smart-voice" and your system prompt.
Thank you so much for helping me, have a good day!