|
|
--- |
|
|
license: other |
|
|
license_name: flux-1-dev-non-commercial-license |
|
|
license_link: >- |
|
|
https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev/blob/main/LICENSE.md |
|
|
language: |
|
|
- en |
|
|
base_model: |
|
|
- black-forest-labs/FLUX.1-Kontext-dev |
|
|
pipeline_tag: image-to-image |
|
|
tags: |
|
|
- gguf-node |
|
|
- gguf-connector |
|
|
widget: |
|
|
- text: the anime girl with massive fennec ears is wearing cargo pants while sitting on a log in the woods biting into a sandwitch beside a beautiful alpine lake |
|
|
output: |
|
|
url: samples\ComfyUI_00001_.png |
|
|
- src: samples\fennec_girl_sing.png |
|
|
prompt: the anime girl with massive fennec ears is wearing cargo pants while sitting on a log in the woods biting into a sandwitch beside a beautiful alpine lake |
|
|
output: |
|
|
url: samples\ComfyUI_00001_.png |
|
|
- text: the anime girl with massive fennec ears is wearing a maid outfit with a long black gold leaf pattern dress and a white apron mouth open holding a fancy black forest cake with candles on top in the kitchen of an old dark Victorian mansion lit by candlelight with a bright window to the foggy forest and very expensive stuff everywhere |
|
|
output: |
|
|
url: samples\ComfyUI_00002_.png |
|
|
- src: samples\fennec_girl_sing.png |
|
|
prompt: the anime girl with massive fennec ears is wearing a maid outfit with a long black gold leaf pattern dress and a white apron mouth open holding a fancy black forest cake with candles on top in the kitchen of an old dark Victorian mansion lit by candlelight with a bright window to the foggy forest and very expensive stuff everywhere |
|
|
output: |
|
|
url: samples\ComfyUI_00002_.png |
|
|
- text: add a hat to the pig |
|
|
output: |
|
|
url: samples\hat.webp |
|
|
- src: samples\pig.png |
|
|
prompt: add a hat to the pig |
|
|
output: |
|
|
url: samples\hat.webp |
|
|
--- |
|
|
# **gguf quantized version of kontext** |
|
|
- drag **kontext** to > `./ComfyUI/models/diffusion_models` |
|
|
- drag **clip-l, t5xxl** to > `./ComfyUI/models/text_encoders` |
|
|
- drag **pig** to > `./ComfyUI/models/vae` |
|
|
|
|
|
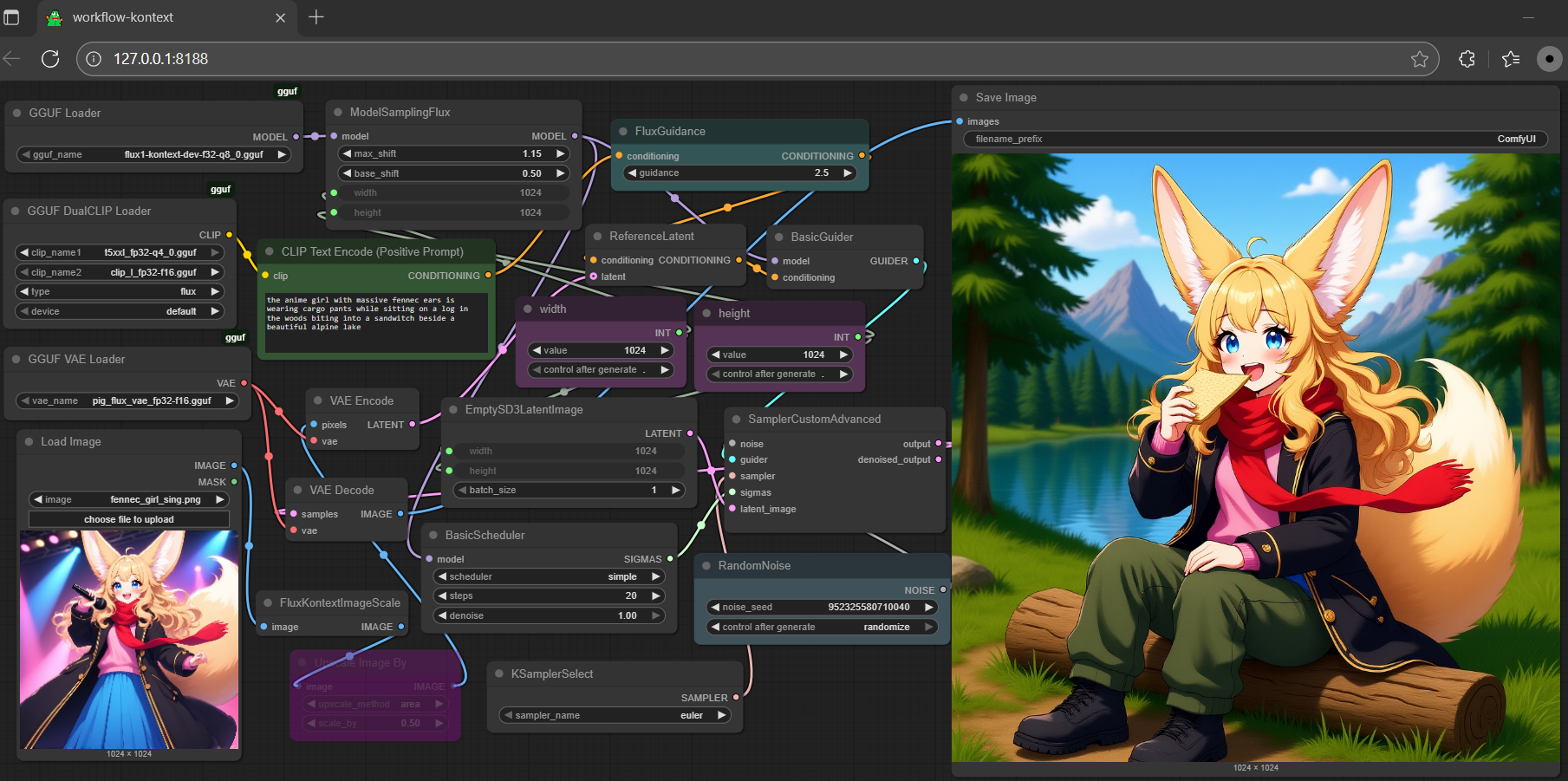 |
|
|
|
|
|
<Gallery /> |
|
|
|
|
|
- don't need safetensors anymore; all gguf (model + encoder + vae) |
|
|
- full set gguf works on gguf-node (see the last item from reference at the very end) |
|
|
- get more **t5xxl** gguf encoder either [here](https://huggingface.co/calcuis/pig-encoder/tree/main) or [here](https://huggingface.co/chatpig/t5-v1_1-xxl-encoder-fp32-gguf/tree/main) |
|
|
|
|
|
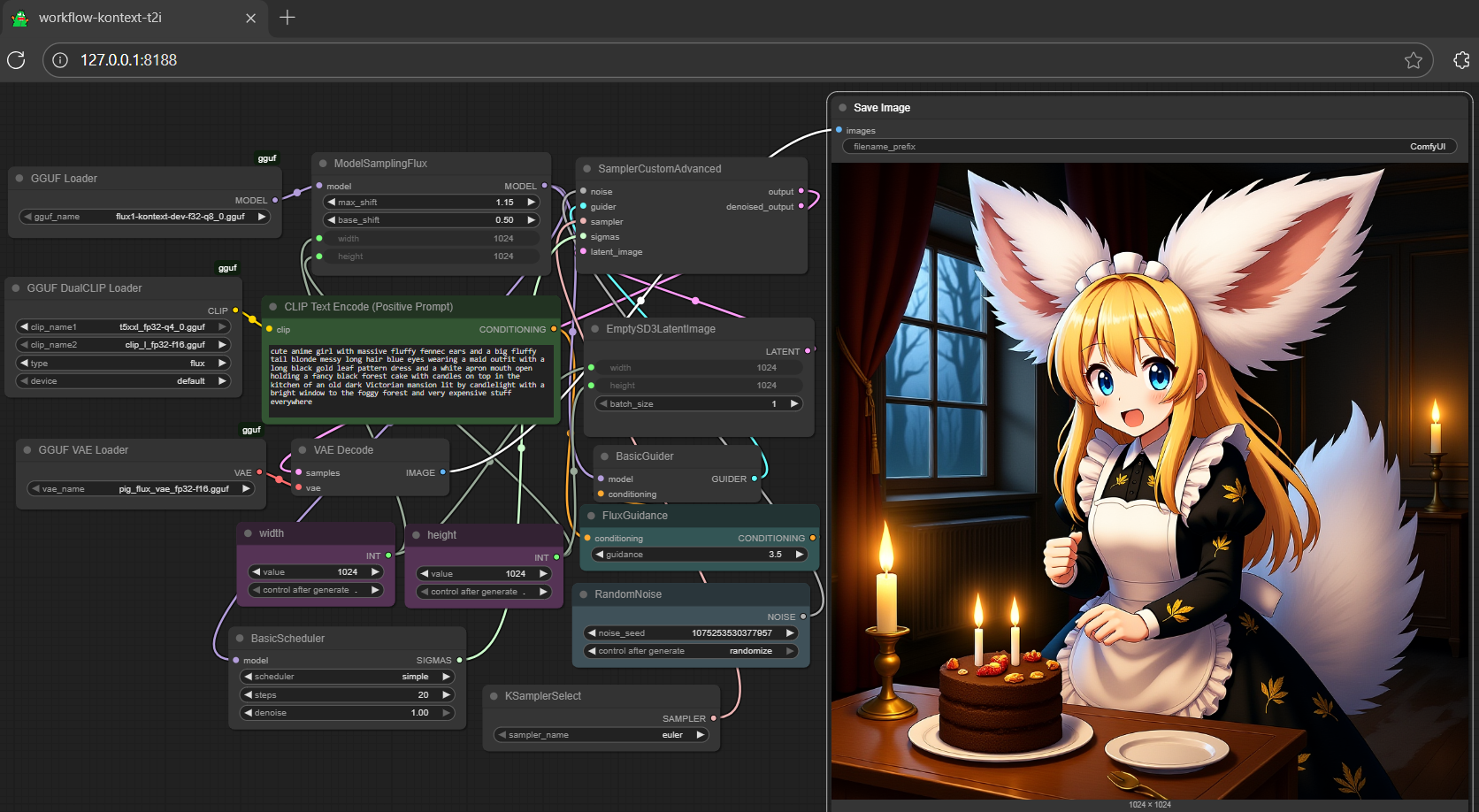 |
|
|
|
|
|
## **extra: scaled safetensors (alternative 1)** |
|
|
- get all-in-one checkpoint [here](https://huggingface.co/convertor/kontext-ckpt-fp8/blob/main/checkpoints/flux1-knotext-dev_fp8_e4m3fn.safetensors) (model, clips and vae embedded) |
|
|
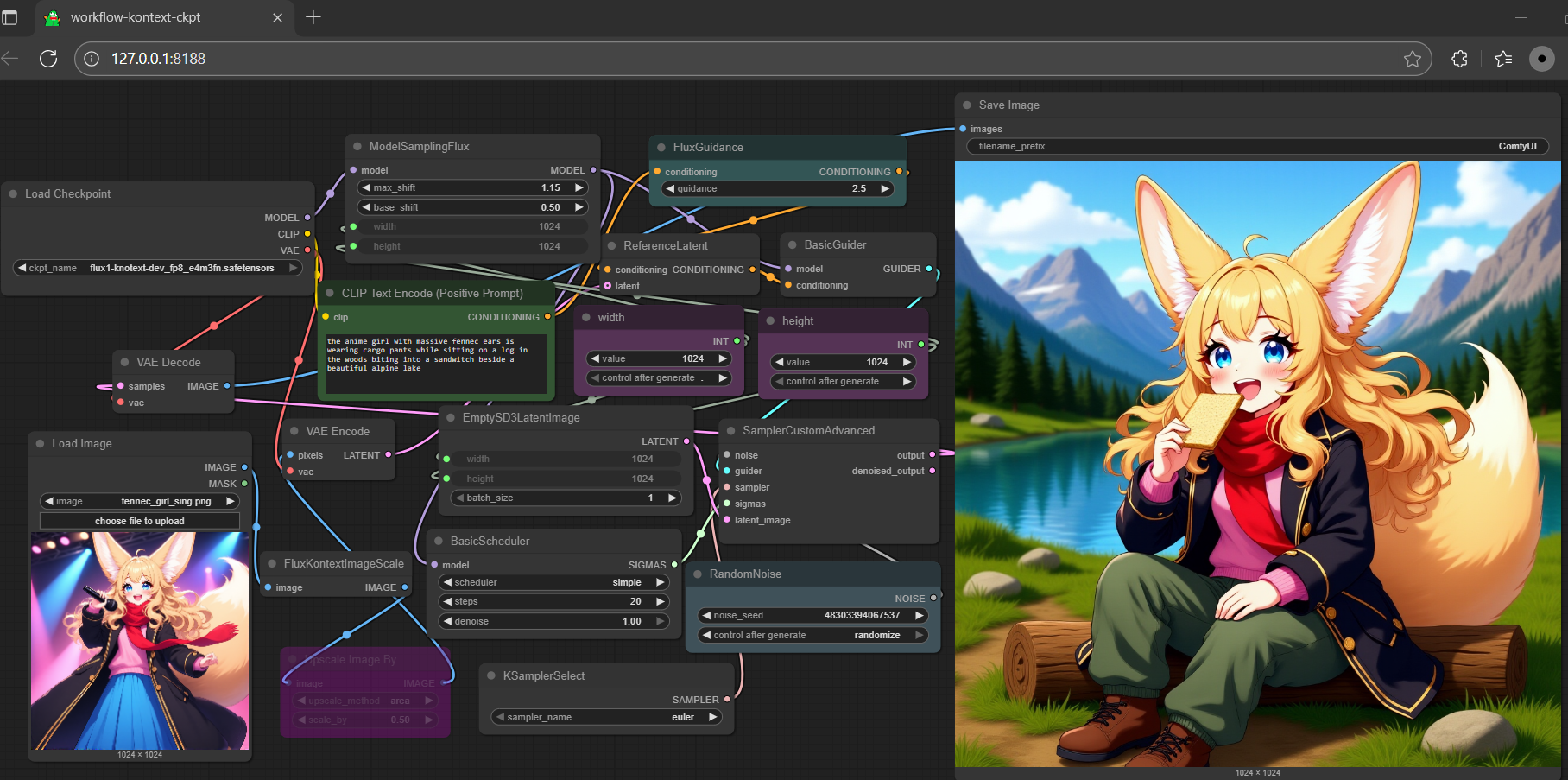 |
|
|
- another option: get multi matrix scaled fp8 from comfyui [here](https://huggingface.co/Comfy-Org/flux1-kontext-dev_ComfyUI/blob/main/split_files/diffusion_models/flux1-dev-kontext_fp8_scaled.safetensors) or e4m3fn fp8 [here](https://huggingface.co/convertor/kontext-ckpt-fp8/blob/main/diffusion_models/flux1-dev-kontext_fp8_e4m3fn.safetensors) with seperate scaled version [l-clip](https://huggingface.co/chatpig/encoder/blob/main/clip_l_fp8_e4m3fn.safetensors), [t5xxl](https://huggingface.co/chatpig/encoder/blob/main/t5xxl_fp8_e4m3fn.safetensors) and [vae](https://huggingface.co/connector/pig-1k/blob/main/vae/pig_flux_vae_fp16.safetensors) |
|
|
|
|
|
## **run it with diffusers🧨 (alternative 2)** |
|
|
- might need the most updated diffusers (git version) for `FluxKontextPipeline` to work; upgrade your diffusers with: |
|
|
``` |
|
|
pip install git+https://github.com/huggingface/diffusers.git |
|
|
``` |
|
|
|
|
|
- see example inference below: |
|
|
```py |
|
|
import torch |
|
|
from transformers import T5EncoderModel |
|
|
from diffusers import FluxKontextPipeline |
|
|
from diffusers.utils import load_image |
|
|
|
|
|
text_encoder = T5EncoderModel.from_pretrained( |
|
|
"calcuis/kontext-gguf", |
|
|
gguf_file="t5xxl_fp16-q4_0.gguf", |
|
|
torch_dtype=torch.bfloat16, |
|
|
) |
|
|
|
|
|
pipe = FluxKontextPipeline.from_pretrained( |
|
|
"calcuis/kontext-gguf", |
|
|
text_encoder_2=text_encoder, |
|
|
torch_dtype=torch.bfloat16 |
|
|
).to("cuda") |
|
|
|
|
|
input_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png") |
|
|
|
|
|
image = pipe( |
|
|
image=input_image, |
|
|
prompt="Add a hat to the cat", |
|
|
guidance_scale=2.5 |
|
|
).images[0] |
|
|
image.save("output.png") |
|
|
``` |
|
|
|
|
|
- tip: if your machine doesn't has enough vram, would suggest running it with gguf-node via comfyui (plan a), otherwise you might expect to wait very long while falling to a slow mode; this is always a winner takes all game |
|
|
|
|
|
## **run it with gguf-connector (alternative 3)** |
|
|
- simply execute the command below in console/terminal |
|
|
``` |
|
|
ggc k2 |
|
|
``` |
|
|
|
|
|
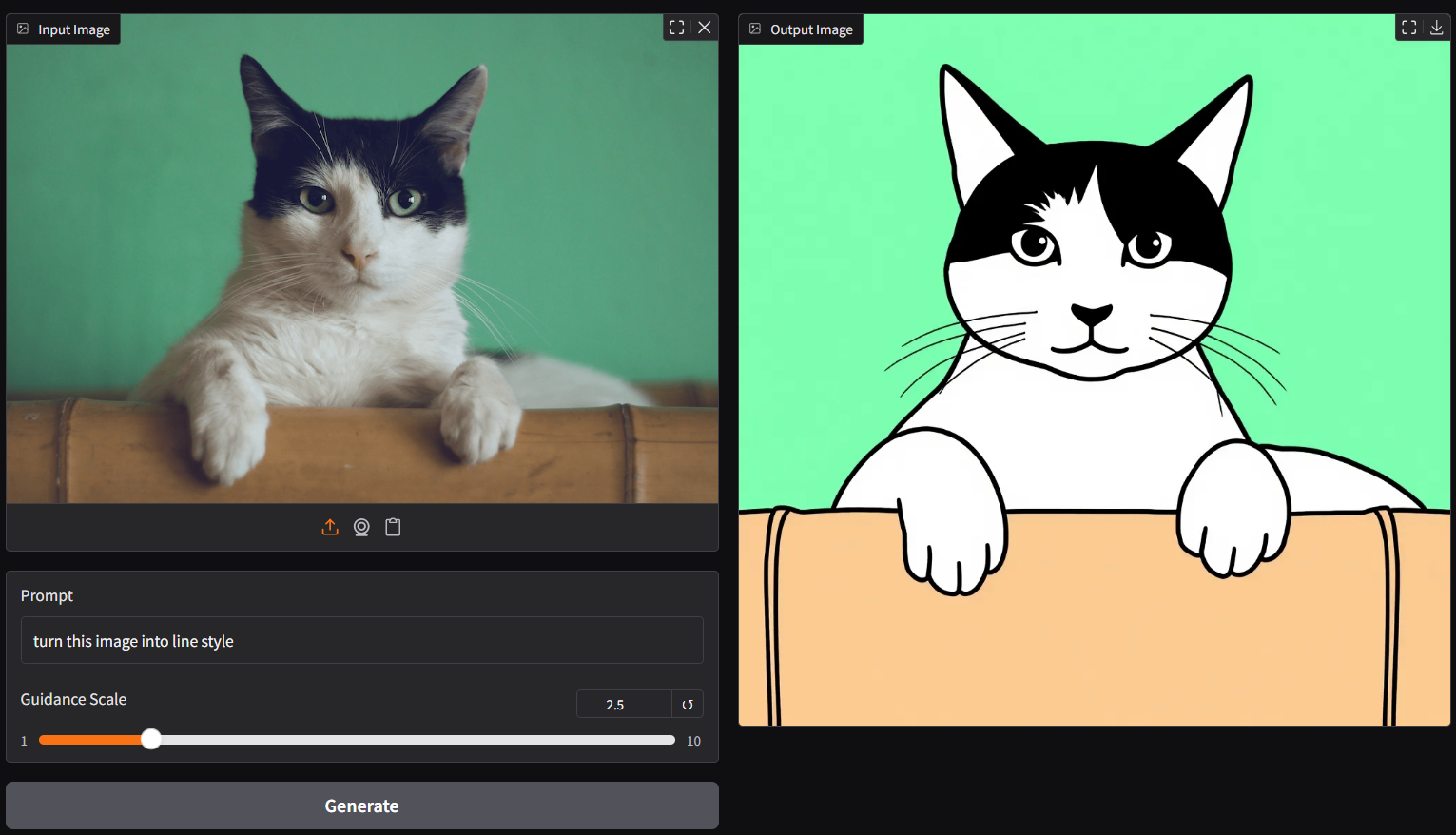 |
|
|
- note: during the first time launch, it will pull the required model file(s) from this repo to local cache automatically; then opt to run it entirely offline; i.e., from local URL: http://127.0.0.1:7860 with lazy webui |
|
|
|
|
|
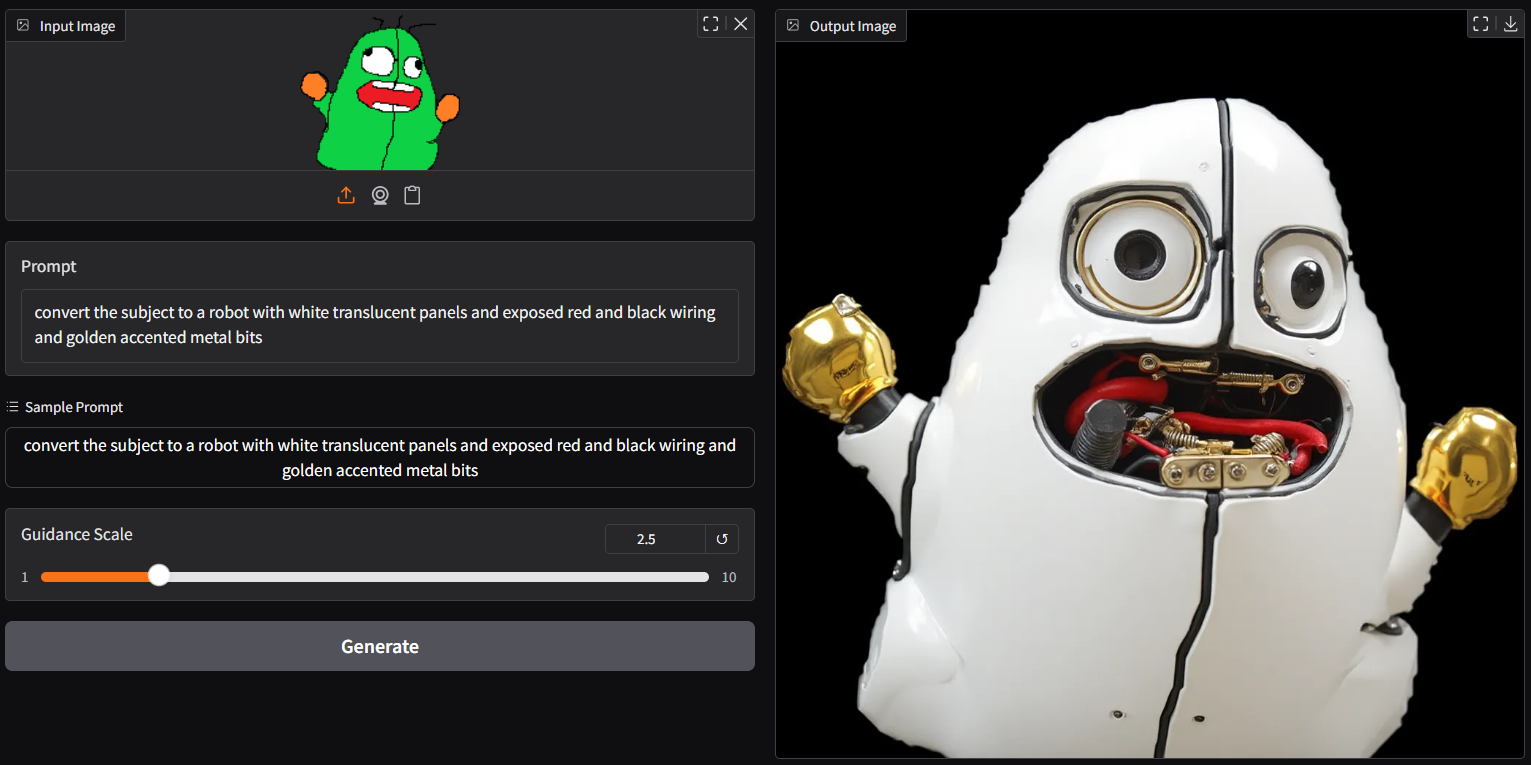 |
|
|
- with bot lora embedded version |
|
|
``` |
|
|
ggc k1 |
|
|
``` |
|
|
|
|
|
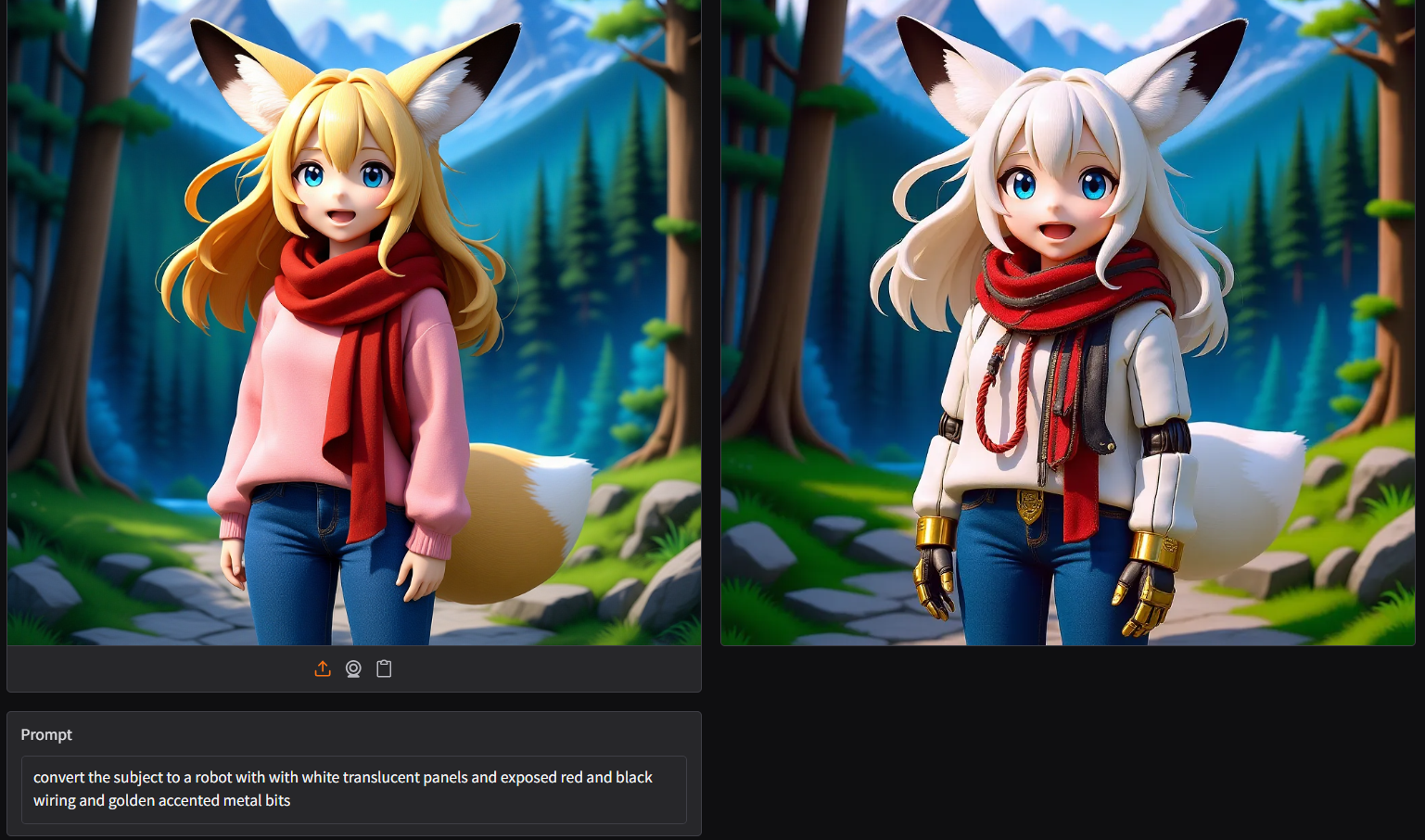 |
|
|
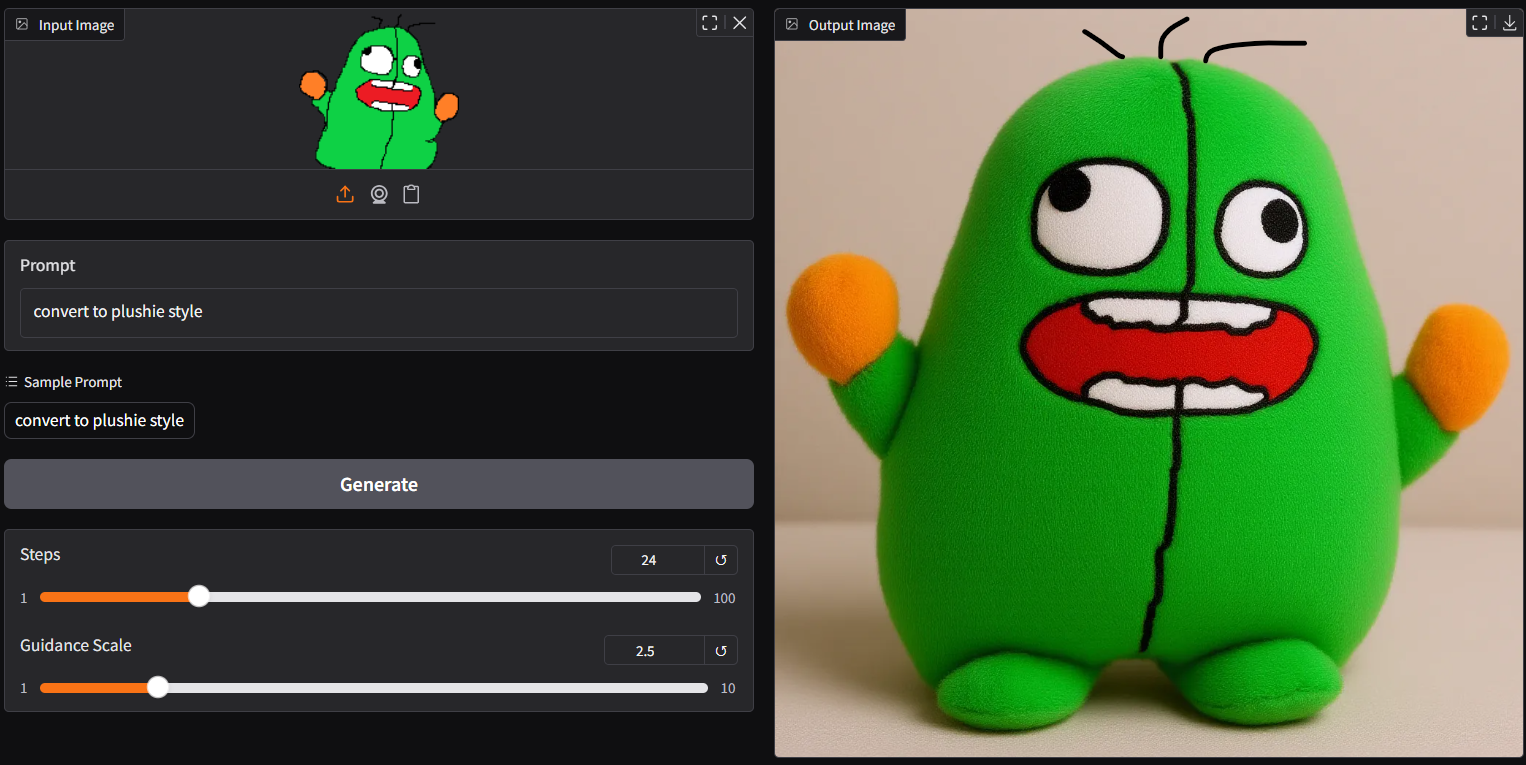
- new plushie style |
|
|
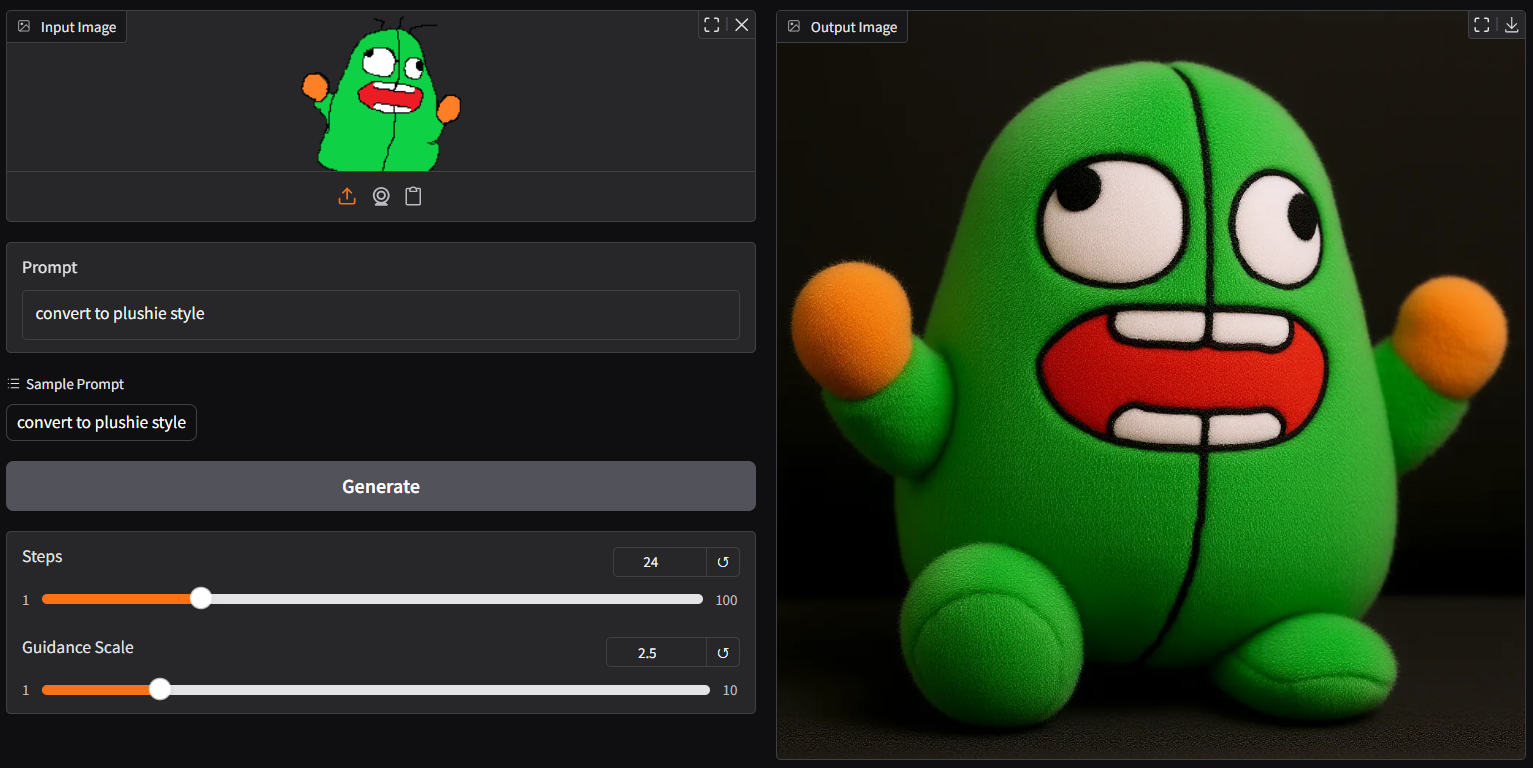 |
|
|
|
|
|
## additional chapter for lora conversion via gguf-connector |
|
|
- convert lora from base to unet format, i.e.,[plushie](https://huggingface.co/fal/Plushie-Kontext-Dev-LoRA/blob/main/plushie-kontext-dev-lora.safetensors), then it can be used in comfyui as well |
|
|
``` |
|
|
ggc la |
|
|
``` |
|
|
|
|
|
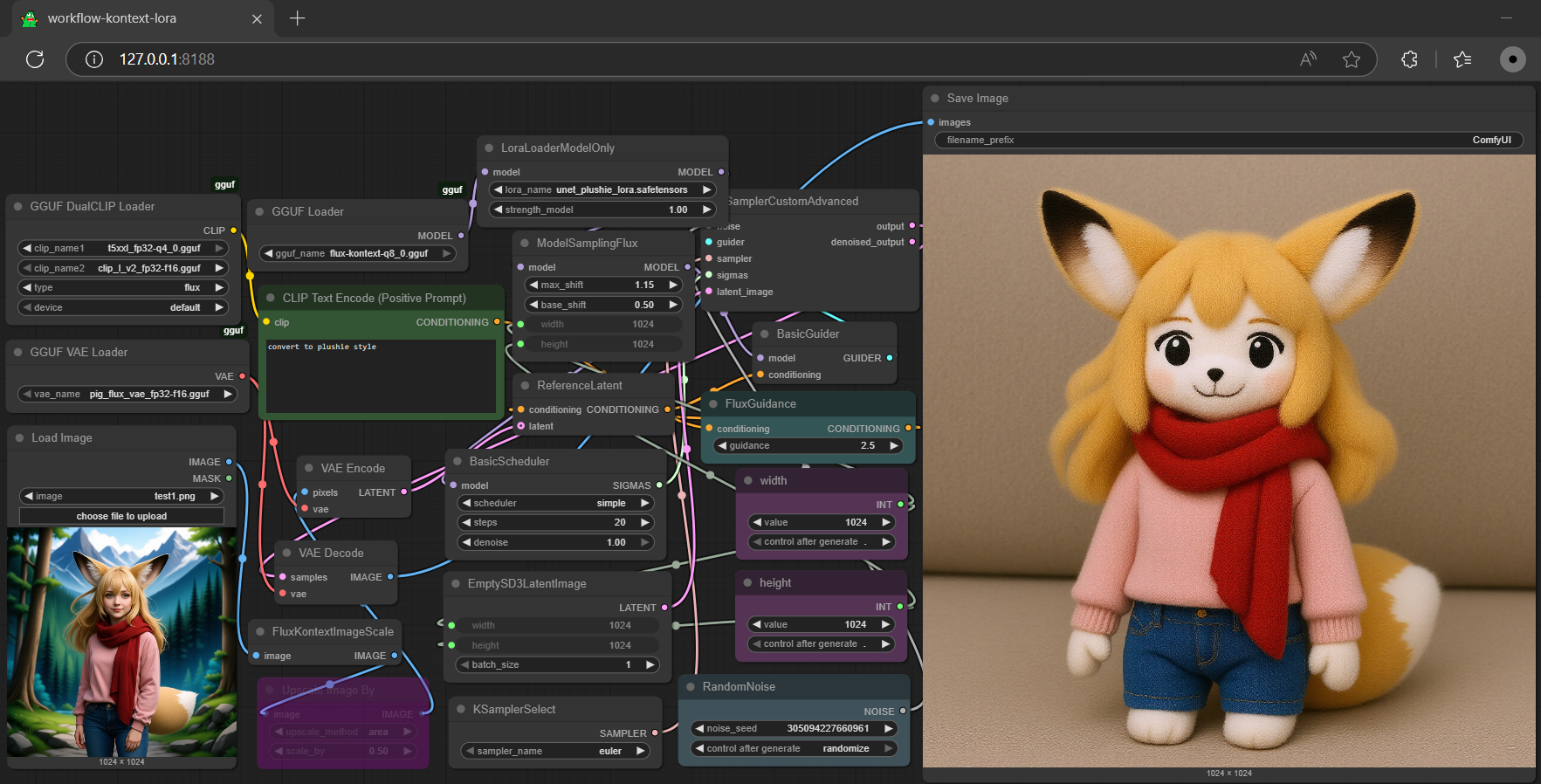 |
|
|
- able to swap the lora back (from unet to base; auto-detection logic applied), then it can be used for inference again |
|
|
``` |
|
|
ggc la |
|
|
``` |
|
|
|
|
|
 |
|
|
|
|
|
### update |
|
|
- [clip-l-v2](https://huggingface.co/calcuis/pig-encoder/blob/main/clip_l_v2_fp32-f16.gguf): missing tensor `text_projection.weight` added |
|
|
- kontext-v2: `s-quant` and `k-quant`; except single and double blocks, all in `f32` status |
|
|
- pros: load faster (as no dequant needed for those tensors); and |
|
|
1) avoid key breaking issue, since some inference engines only dequant blocks; |
|
|
2) compatible for non-cuda machines, as most of them cannot run `bf16` tensors |
|
|
- cons: little bit larger in file size |
|
|
- kontext-v3: `i-quant` attempt (upgrade your node to the latest version for full quant support) |
|
|
- kontext-v4: `t-quant`; runnable (extramely fast); for speed test/experimental purposes |
|
|
|
|
|
|rank|quant|s/it|loading speed| |
|
|
|----|--------|---------|----------------| |
|
|
| 1 | q2_k | 6.40±.7 |🐖💨💨💨💨💨💨 |
|
|
| 2 | q4_0 | 8.58±.5 |🐖🐖💨💨💨💨💨 |
|
|
| 3 | q4_1 | 9.12±.5 |🐖🐖🐖💨💨💨💨 |
|
|
| 4 | q8_0 | 9.45±.3 |🐖🐖🐖🐖💨💨💨 |
|
|
| 5 | q3_k | 9.50±.3 |🐖🐖🐖🐖💨💨💨 |
|
|
| 6 | q5_0 | 10.48±.5|🐖🐖🐖🐖🐖💨💨 |
|
|
| 7 | iq4_nl | 10.55±.5|🐖🐖🐖🐖🐖💨💨 |
|
|
| 8 | q5_1 | 10.65±.5|🐖🐖🐖🐖🐖💨💨 |
|
|
| 9 | iq4_xs | 11.45±.7|🐖🐖🐖🐖🐖🐖💨 |
|
|
| 10| iq3_s | 11.62±.9|🐢🐢🐢🐢🐢🐢💨 |
|
|
| 11| iq3_xxs| 12.08±.9|🐢🐢🐢🐢🐢🐢🐢 |
|
|
|
|
|
not all included in the initial test (*tested with a beginner laptop gpu only, if you have highend model, might find q8_0 running surprisingly faster than others), the rest of them, test it yourself; btw, the interesting thing is: the loading time required was not aligning with file size, due to the complexity of each calculation (dequant), and might vary from model |
|
|
|
|
|
### **reference** |
|
|
- base model from [black-forest-labs](https://huggingface.co/black-forest-labs) |
|
|
- comfyui from [comfyanonymous](https://github.com/comfyanonymous/ComfyUI) |
|
|
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector)) |
|
|
- gguf-node ([pypi](https://pypi.org/project/gguf-node)|[repo](https://github.com/calcuis/gguf)|[pack](https://github.com/calcuis/gguf/releases)) |
