
ColorMAE: Exploring data-independent masking strategies in Masked AutoEncoders
Image and Video Understanding Lab, AI Initiative, KAUST
Carlos Hinojosa, Shuming Liu, Bernard Ghanem
Paper ·
GitHub ·
Supplementary Material ·
Project ·
BibTeX
Can we enhance MAE performance beyond random masking without relying on input data or incurring additional computational costs?
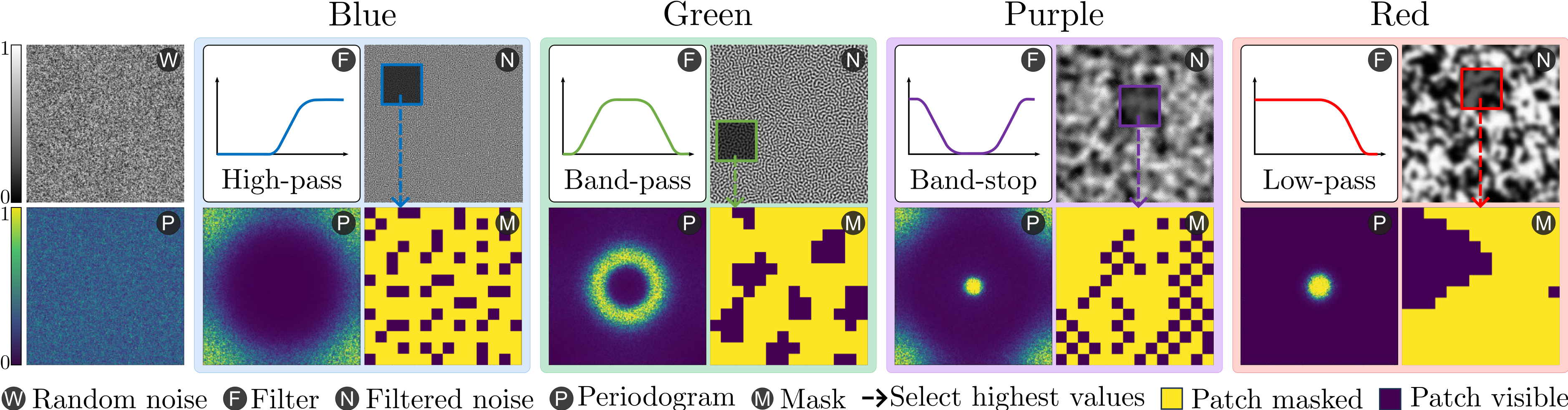
We introduce ColorMAE, a simple yet effective data-independent method which generates different binary mask patterns by filtering random noise. Drawing inspiration from color noise in image processing, we explore four types of filters to yield mask patterns with different spatial and semantic priors. ColorMAE requires no additional learnable parameters or computational overhead in the network, yet it significantly enhances the learned representations.
Installation
To get started with ColorMAE, follow these steps to set up the required environment and dependencies. This guide will walk you through creating a Conda environment, installing necessary packages, and setting up the project for use.
- Clone our repo to your local machine
git clone https://github.com/carlosh93/ColorMAE.git
cd ColorMAE
- Create conda environment with python 3.10.12
conda create --prefix ./venv python=3.10.12 -y
conda activate ./venv
- Install Pytorch 2.0.1 and mmpretrain 1.0.2:
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install -U openmim && mim install mmpretrain==1.0.2 mmengine==0.8.4 mmcv==2.0.1
pip install yapf==0.40.1
Note: You can install mmpretrain as a Python package (using the above commands) or from source (see here).
Getting Started
Setup Environment
At first, add the current folder to PYTHONPATH, so that Python can find your code. Run command in the current directory to add it.
Note: Please run it every time after you opened a new shell.
export PYTHONPATH=`pwd`:$PYTHONPATH
Data Preparation
Prepare the ImageNet-2012 dataset according to the instruction. We provide a script and step by step guide here.
Download Color Noise Patterns
The following table provides the color noise patterns used in the paper
| Color Noise | Description | Link | Md5 |
|---|---|---|---|
| Green Noise | Mid-frequency component of noise. | Download | a76e71 |
| Blue Noise | High-frequency component of noise. | Download | ca6445 |
| Purple Noise | Noise with only high and low-frequency content. | Download | 590c8f |
| Red Noise | Low-frequency component of noise. | Download | 1dbcaa |
You can download these pre-generated color noise patterns and place them in the corresponding folder inside noise_colors directory of the project.
Models and results
In the following tables we provide the pretrained and finetuned models with their corresponding results presented in the paper.
Note: This repository hosts the ViT-Large checkpoints. The ViT-Base checkpoints are currently available on OSF but will be gradually migrated to this repository.
Pretrained models
| Model | Params (M) | Flops (G) | Config | Download |
|---|---|---|---|---|
colormae_vit-base-p16_8xb512-amp-coslr-300e_in1k.py |
111.91 | 16.87 | config | model | log |
colormae_vit-base-p16_8xb512-amp-coslr-800e_in1k.py |
111.91 | 16.87 | config | model | log |
colormae_vit-base-p16_8xb512-amp-coslr-1600e_in1k.py |
111.91 | 16.87 | config | model | log |
Image Classification on ImageNet-1k
| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Config | Download |
|---|---|---|---|---|---|---|
vit-base-p16_colormae-green-300e-pre_8xb128-coslr-100e_in1k |
ColorMAE-G 300-Epochs | 86.57 | 17.58 | 83.01 | config | model | log |
vit-base-p16_colormae-green-800e-pre_8xb128-coslr-100e_in1k |
ColorMAE-G 800-Epochs | 86.57 | 17.58 | 83.61 | config | model | log |
vit-base-p16_colormae-green-1600e-pre_8xb128-coslr-100e_in1k |
ColorMAE-G 1600-Epochs | 86.57 | 17.58 | 83.77 | config | model | log |
Semantic Segmentation on ADE20K
| Model | Pretrain | Params (M) | Flops (G) | mIoU (%) | Config | Download |
|---|---|---|---|---|---|---|
name |
ColorMAE-G 300-Epochs | xx.xx | xx.xx | 45.80 | config | N/A |
name |
ColorMAE-G 800-Epochs | xx.xx | xx.xx | 49.18 | config | N/A |
Object Detection and Instance Segmentation on COCO
| Model | Pretrain | Params (M) | Flops (G) | $AP^{bbox}$ (%) | Config | Download |
|---|---|---|---|---|---|---|
name |
ColorMAE-G 300-Epochs | xx.xx | xx.xx | 48.70 | config | N/A |
name |
ColorMAE-G 800-Epochs | xx.xx | xx.xx | 49.50 | config | N/A |
Using the Models
Predict image
Download the vit-base-p16_colormae-green-300e-pre_8xb128-coslr-100e_in1k.pth pretrained classification model and place it inside the pretrained folder, then run:
from mmpretrain import ImageClassificationInferencer
image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
config = 'benchmarks/image_classification/configs/vit-base-p16_8xb128-coslr-100e_in1k.py'
checkpoint = 'pretrained/vit-base-p16_colormae-green-300e-pre_8xb128-coslr-100e_in1k.pth'
inferencer = ImageClassificationInferencer(model=config, pretrained=checkpoint, device='cuda')
result = inferencer(image)[0]
print(result['pred_class'])
print(result['pred_score'])
Use the pretrained model
Also, you can use the pretrained ColorMAE model to extract features.
import torch
from mmpretrain import get_model
config = "configs/colormae_vit-base-p16_8xb512-amp-coslr-300e_in1k.py"
checkpoint = "pretrained/colormae-green-epoch_300.pth"
model = get_model(model=config, pretrained=checkpoint)
inputs = torch.rand(1, 3, 224, 224)
out = model(inputs)
print(type(out))
# To extract features.
feats = model.extract_feat(inputs)
print(type(feats))
Pretraining Instructions
We use mmpretrain for pretraining the models similar to MAE. Please refer here for the instructions: PRETRAIN.md.
Finetuning Instructions
We evaluate transfer learning performance using our pre-trained ColorMAE models on different datasets and downstream tasks including: Image Classification, Semantic Segmentation, and Object Detection. Please refer to the FINETUNE.md file in the corresponding folder.
Acknowledgments
- Our code is based on the MAE implementation of the mmpretrain project: https://github.com/open-mmlab/mmpretrain/tree/main/configs/mae. We thank all contributors from MMPreTrain, MMSegmentation, and MMDetection.
- This work was supported by the KAUST Center of Excellence on GenAI under award number 5940.
How to cite
If you use our code or models in your research, please cite our work as follows:
@inproceedings{hinojosa2024colormae,
title={ColorMAE: Exploring data-independent masking strategies in Masked AutoEncoders},
author={Hinojosa, Carlos and Liu, Shuming and Ghanem, Bernard},
booktitle={European Conference on Computer Vision},
url={https://www.ecva.net/papers/eccv_2024/papers_ECCV/html/3072_ECCV_2024_paper.php}
year={2024}
}
Troubleshooting
CuDNN Warning
If you encounter the following warning at the beginning of pretraining:
UserWarning: Applied workaround for CuDNN issue, install nvrtc.so (Triggered internally at /opt/conda/conda-bld/pytorch_1682343995026/work/aten/src/ATen/native/cudnn/Conv_v8.cpp:80.)
return F.conv2d(input, weight, bias, self.stride,
Solution: This warning indicates a missing or incorrectly linked nvrtc.so library in your environment. To resolve this issue, create a symbolic link to the appropriate libnvrtc.so file. Follow these steps:
- Navigate to the library directory of your virtual environment:
cd venv/lib/ # Adjust the path if your environment is located elsewhere
- Create a symbolic link to libnvrtc.so.11.8.89:
ln -sfn libnvrtc.so.11.8.89 libnvrtc.so