
id
stringlengths 36
36
| source
stringclasses 15
values | formatted_source
stringclasses 13
values | text
stringlengths 2
7.55M
|
|---|---|---|---|
5d244ae6-f400-4d0a-aec8-8de91dd43281
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Rational Terrorism or Why shouldn't we burn down tobacco fields?
Related: Taking ideas seriously
Let us say hypothetically you care about stopping people smoking.
You were going to donate $1000 dollars to givewell to save a life, instead you learn about an anti-tobacco campaign that is better. So you chose to donate $1000 dollars to a campaign to stop people smoking instead of donating it to a givewell charity to save an African's life. You justify this by expecting more people to live due to having stopped smoking (this probably isn't true, but for the sake of argument)
The consequences of donating to the anti-smoking campaign is that 1 person dies in africa and 20 live that would have died instead live all over the world.
Now you also have the choice of setting fire to many tobacco plantations, you estimate that the increased cost of cigarettes would save 20 lives but it will kill likely 1 guard worker. You are very intelligent so you think you can get away with it. There are no consequences to this action. You don't care much about the scorched earth or loss of profits.
If there are causes with payoff matrices like this, then it seems like a real world instance of the trolley problem. We are willing to cause loss of life due to inaction to achieve our goals but not cause loss of life due to action.
What should you do?
Killing someone is generally wrong but you are causing the death of someone in both cases. You either need to justify that leaving someone to die is ethically not the same as killing someone, or inure yourself that when you chose to spend $1000 dollars in a way that doesn't save a life, you are killing. Or ignore the whole thing.
This just puts me off being utilitarian to be honest.
Edit: To clarify, I am an easy going person, I don't like making life and death decisions. I would rather live and laugh, without worrying about things too much.
This confluence of ideas made me realise that we are making life and death decisions every time we spend $1000 dollars. I'm not sure where I will go from here.
|
a8025cc1-62b6-4872-8fe5-eb1d12b07166
|
trentmkelly/LessWrong-43k
|
LessWrong
|
STRUCTURE: A Crash Course in Your Brain
This post is part of my Hazardous Guide To Rationality. I don't expect this to be new or exciting to frequent LW people, and I would super appreciate comments and feedback in light of intents for the sequence, as outlined in the above link. Also, note this is a STRUCTURE post, again see the above link for what that means.
Intro
Talking about truth and reality can be hard. First, we're going to take a stroll through what we currently know about how the human mind works, and what the implications are for one's ability to be right.
Outline of main ideas. Could be post per main bullet.
* The Unconscious exists
* There is "more happening" in your brain than you are consciously aware of
* S1 / S2 introduction (research if I actually recommend Thinking Fast and Slow as the best intro)
* Confabulation is a thing
* You have an entire sub-module in your brain which is specialized for making up reasons for why you do things. Because of this, even if you ask yourself, "Why did I just tip over that vase?" and get a ready answer, it is hard to figure out if that is a true reason for your behavior.
* By default, thoughts feel like facts.
* The lower-level a thought produced by your brain, the less it feels like, 'A thing I think which could be true of false" and the more it feels like, "The way the world obviously is, duh."
* Your intuitions do not have special magical access to the truth. They are sometimes wrong, and sometimes right. But unless you pay attention, you are likely to by default, believe them to be compleely correct.
* We are Predictably Wrong
* You don't automatically know what you actual beliefs are.
* You also have the ability to say "I believe XYZ" while having no meaningful/consequential relations of XYZ to the rest of your world model. You can also not notice that this is the case.
* Luckily, you do still have some non-zero ability to have anticipation/expectations about reality, and have world models/beliefs.
* When b
|
4401cd0c-00fd-47a9-8df0-2624e2bc6c18
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The national security dimension of OpenAI's leadership struggle
As the very public custody battle over OpenAI's artificial intelligences winds down, I would like to point out a few facts, and then comment briefly on their possible significance.
It has already been noticed that "at least two of the board members, Tasha McCauley and Helen Toner, have ties to the Effective Altruism movement", as the New York Times puts it. Both these board members also have national security ties.
With Helen Toner it's more straightforward; she has a master's degree in Security Studies at Georgetown University, "the most CIA-specific degree" at a university known as a gateway to deep state institutions. That doesn't mean she's in the CIA; but she's in that milieu.
As for Tasha McCauley, it's more oblique: her actor husband played Edward Snowden, the famous NSA defector, in the 2016 biographical film. Hollywood's relationship to the American intelligence community is, I think, a little more vexed than Georgetown's. McCauley and her husband might well be pro-Snowden civil libertarians who want deep state power curtailed; that would make them the "anti national security" faction on the OpenAI board, so to speak.
Either way, this means that the EAs on the board, who both presumably voted to oust Sam Altman as CEO, are adjacent to the US intelligence community, and/or its critics, many of whom are intelligence veterans anyway.
((ADDED A WEEK LATER: It has been pointed out to me that even if Joseph Gordon-Levitt did meet a few ex-spooks on the set of Snowden, that doesn't in itself equate to his wife having "national security ties". Obviously that's true; I just assumed that the connections run a lot deeper, and that may sound weird if you're used to thinking of the intelligence community and the culture industry as entirely separate. In any case, I accept the criticism that this is pure speculation on my part, and that I should have made my larger points in some other way.))
Those are my facts. Now for my interpretation.
Artificial intellig
|
e9b8ee30-de61-4c30-88aa-846896a07162
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
The Pragmascope Idea
Pragma (Greek): thing, object.
A “pragmascope”, then, would be some kind of measurement or visualization device which shows the “things” or “objects” present.
I currently see the pragmascope as *the* major practical objective of [work on natural abstractions](https://www.lesswrong.com/posts/cy3BhHrGinZCp3LXE/testing-the-natural-abstraction-hypothesis-project-intro). As I see it, the core theory of natural abstractions is now 80% nailed down, I’m now working to get it across the theory-practice gap, and the pragmascope is the big milestone on the other side of that gap.
This post introduces the idea of the pragmascope and what it would look like.
Background: A Measurement Device Requires An Empirical Invariant
----------------------------------------------------------------
First, an aside on developing new measurement devices.
### Why The Thermometer?
What makes a thermometer a good measurement device? Why is “temperature”, as measured by a thermometer, such a useful quantity?
Well, at the most fundamental level… we stick a thermometer in two different things. Then, we put those two things in contact. Whichever one showed a higher “temperature” reading on the thermometer gets colder, whichever one showed a lower “temperature” reading on the thermometer gets hotter, all else equal (i.e. controlling for heat exchanged with other things in the environment). And this is robustly true across a huge range of different things we can stick a thermometer into.
It didn’t have to be that way! We could imagine a world (with very different physics) where, for instance, heat always flows from red objects to blue objects, from blue objects to green objects, and from green objects to red objects. But we don’t see that in practice. Instead, we see that each system can be assigned a single number (“temperature”), and then when we put two things in contact, the higher-number thing gets cooler and the lower-number thing gets hotter, regardless of which two things we picked.
Underlying the usefulness of the thermometer is an *empirical* fact, an *invariant*: the fact that which-thing-gets-hotter and which-thing-gets-colder when putting two things into contact can be predicted from a single one-dimensional real number associated with each system (i.e. “temperature”), for an extremely wide range of real-world things.
Generalizing: a useful measurement device starts with identifying some empirical invariant. There needs to be a wide variety of systems which interact in a predictable way across many contexts, *if* we know some particular information about each system. In the case of the thermometer, a wide variety of systems get hotter/colder when in contact, in a predictable way across many contexts, *if* we know the temperature of each system.
So what would be an analogous empirical invariant for a pragmascope?
### The Role Of The Natural Abstraction Hypothesis
The [natural abstraction hypothesis](https://www.lesswrong.com/posts/cy3BhHrGinZCp3LXE/testing-the-natural-abstraction-hypothesis-project-intro) has three components:
1. Chunks of the world generally interact with far-away chunks of the world via relatively-low-dimensional summaries
2. A broad class of cognitive architectures converge to use subsets of these summaries (i.e. they’re instrumentally convergent)
3. These summaries match human-recognizable “things” or “concepts”
For purposes of the pragmascope, we’re particularly interested in claim 2: a broad class of cognitive architectures converge to use subsets of the summaries. If true, that sure sounds like an empirical invariant!
So what would a corresponding measurement device look like?
What would a pragmascope look like, concretely?
-----------------------------------------------
The “measurement device” (probably a python function, in practice) should take in some cognitive system (e.g. a trained neural network) and maybe its environment (e.g. simulator/data), and spit out some data structure representing the natural “summaries” in the system/environment. Then, we should easily be able to take some *other* cognitive system trained on the same environment, extract the natural “summaries” from that, and compare. Based on the natural abstraction hypothesis, we expect to observe things like:
* A broad class of cognitive architectures trained on the same data/environment end up with subsets of the same summaries.
* Two systems with the same summaries are able to accurately predict the same things on new data from the same environment/distribution.
* On inspection, the summaries correspond to human-recognizable “things” or “concepts”.
* A system is able to accurately predict things involving the same human-recognizable concepts the pragmascope says it has learned, and cannot accurately predict things involving human-recognizable concepts the pragmascope says it has not learned.
It’s these empirical observations which, if true, will underpin the usefulness of the pragmascope. The more precisely and robustly these sorts of properties hold, the more useful the pragmascope. Ideally we’d even be able to *prove* some of them.
### What’s The Output Data Structure?
One obvious currently-underspecified piece of the picture: what data structures will the pragmascope output, to represent the “summaries”? I have some [current-best-guesses based on the math](https://www.lesswrong.com/posts/cqdDGuTs2NamtEhBW/maxent-and-abstractions-current-best-arguments), but the main answer at this point is “I don’t know yet”. I expect looking at the internals of trained neural networks will give lots of feedback about what the natural data structures are.
Probably the earliest empirical work will just punt on standard data structures, and instead focus on translating internal-concept-representations in one net into corresponding internal-concept-representations in another. For instance, here’s one experiment I recently proposed:
* Train two nets, with different architectures (both capable of achieving zero training loss and good performance on the test set), on the same data.
* Compute the small change in data dx which would induce a small change in trained parameter values d\theta along each of the narrowest directions of the ridge in the loss landscape (i.e. eigenvectors of the Hessian with largest eigenvalue).
* Then, compute the small change in parameter values d\theta in the *second* net which would result from the same small change in data dx.
* Prediction: the d\theta directions computed will approximately match the narrowest directions of the ridge in the loss landscape of the second net.
Conceptually, this sort of experiment is intended to take all the stuff one network learned, and compare it to all the stuff the other network learned. It wouldn’t yield a full pragmascope, because it wouldn’t say anything about how to factor all the stuff a network learns into individual concepts, but it would give a very well-grounded starting point for translating stuff-in-one-net into stuff-in-another-net (to first/second-order approximation).
|
884969a4-0c62-4fc3-833e-c8100825d25d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
You are Underestimating The Likelihood That Convergent Instrumental Subgoals Lead to Aligned AGI
This post is an argument for the Future Fund's "AI Worldview" prize. Namely, I claim that the estimates given for the following probability are too high:
> P(misalignment x-risk|AGI)”: Conditional on AGI being developed by 2070, humanity will go extinct or drastically curtail its future potential due to loss of control of AGI
The probability given here is 15%. I believe 5% is a more realistic estimate here.
I believe that, if convergent instrumental subgoals don't imply alignment, that the original odds given are probably too low. I simply don't believe that the alignment problem is solvable. Therefore, I believe our only real shot at surviving the existence of AGI is if the AGI finds it better to keep us around, based upon either us providing utility or lowering risk to the AGI.
Fortunately, I think the odds that an AGI will find it a better choice to keep us around are higher than the ~5:1 odds given.
I believe keeping humans around, and supporting their wellbeing, both lowers risk and advances instrumental subgoals for the AGI for the following reasons:
* hardware sucks, machines break all the time, and the current global supply chain necessary for maintaining operational hardware would not be cheap or easy to replace without taking on substantial risk
* perfectly predicting the future in chaotic system is impossible beyond some time horizon, which means there are no paths for the AGI that guarantee its survival; keeping alive a form of intelligence with very different risk profiles might be a fine hedge against failure
My experience working on supporting Google's datacenter hardware left me with a strong impression that for large numbers of people, the fact that hardware breaks down and dies, often, requiring a constant stream of repairs, is invisible. Likewise, I think a lot of adults take the existence of functioning global supply chains for all manner of electronic and computing hardware as givens. I find that most adults, even most adult
|
5d488a63-5d33-4219-95df-e83d1698ed8f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Reputation bets
People don’t often put their money where their mouth is, but they do put their reputation where their mouth is all the time. If I say ‘The Strategy of Conflict is pretty good’ I am betting some reputation on you liking it if you look at it. If you do like it, you will think better of me, and if you don’t, you will think worse. Even if I just say ‘it’s raining’, I’m staking my reputation on this. If it isn’t raining, you will think there is something wrong with me. If it is raining, you will decrease your estimate of how many things are wrong with me the teensiest bit.
If we have reputation bets all the time, why would it be so great to have more money bets?
Because reputation bets are on a limited class of propositions. They are all of the form ’doing X will make me look good’. This is pretty close to betting that an observer will endorse X. Such bets are most useful for statements that are naturally about what the observer will endorse. For instance (a) ’you would enjoy this blog’ is pretty close to (b) ‘you will endorse the claim that you would enjoy this blog’. It isn’t quite the same – for instance, if the listener refuses to look at the blog, but judges by its title that it is a silly blog, then (a) might be true while (b) is false. But still, if I want to bet on (a), betting on (b) is a decent proxy.
Reputation bets are also fairly useful for statements where the observer will mostly endorse true statements, such as ‘there is ice cream in the freezer’. Reputation bets are much less useful (for judging truth) where the observer is as likely to be biased and ignorant as the person making the statement. For instance, ‘removing height restrictions on buildings would increase average quality of life in our city’. People still do make reputation bets in these cases, but they are betting on their judgment of the other person’s views.
If the set of things where people mostly endorse true answers is roughly the set where it is pretty clear what the true answer is,
|
c805136b-ab96-44b1-adf5-edb21e2bbfb0
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Are extrapolation-based AIs alignable?
(This is an account of my checking a certain alignment idea and finding that it doesn't work. Also my thinking is pretty naive and could easily be wrong.)
When thinking about AIs that are trained on some dataset and learn to extrapolate it, like the current crop of LLMs, I asked myself: can such an AI be aligned purely by choosing an appropriate dataset to train on? In other words, does there exist any dataset such that generating extrapolations from it leads to good outcomes, even in the hands of bad actors? If we had such a dataset, we'd have an aligned AI.
But unfortunately it seems hard. For example if the dataset includes instructions to build a nuke, then a bad actor could just ask for that. Moreover, if there's any circumstance at all under which we want the AI to say "here's the instructions to build a nuke" (to help a good actor stop an incoming asteroid, say), then a bad actor could extrapolate from that phrase and get the same result.
It seems the problem is that extrapolation doesn't have situational awareness. If the AI is based on extrapolating a certain dataset, there's no way to encode in the dataset itself which parts of it can be said when. And putting a thin wrapper on top, like ChatGPT, doesn't seem to help much, because from what I've seen it's easy enough to bypass.
What is the hope for alignment, then? Can we build an AI with situational awareness from the ground up, not relying on an "extrapolation core" (because the core would itself be an unaligned AI that bad actors could use)? I don't know.
EDIT: the sequel to this post is Aligned AI as a wrapper around an LLM.
|
b96512fd-8295-47ab-9d95-f4c3b3856d8e
|
StampyAI/alignment-research-dataset/arbital
|
Arbital
|
Harmless supernova fallacy
Harmless supernova fallacies are a class of arguments, usually a subspecies of false dichotomy or continuum fallacy, which [can equally be used to argue](https://arbital.com/p/3tc) that almost any physically real phenomenon--including a supernova--is harmless / manageable / safe / unimportant.
- **Bounded, therefore harmless:** "A supernova isn't infinitely energetic--that would violate the laws of physics! Just wear a flame-retardant jumpsuit and you'll be fine." (All physical phenomena are finitely energetic; some are nonetheless energetic enough that a flame-retardant jumpsuit won't stop them. "Infinite or harmless" is a false dichotomy.)
- **Continuous, therefore harmless:** "Temperature is continuous; there's no qualitative threshold where something becomes 'super' hot. We just need better versions of our existing heat-resistant materials, which is a well-understood engineering problem." (Direct instance of the standard continuum fallacy: the existence of a continuum of states between two points does not mean they are not distinct. Some temperatures, though not qualitatively distinct from lower temperatures, exceed what we can handle using methods that work for lower temperatures. "Quantity has a quality all of its own.")
- **Varying, therefore harmless:** "A supernova wouldn't heat up all areas of the solar system to exactly the same temperature! It'll be hotter closer to the center, and cooler toward the outside. We just need to stay on a part of Earth that's further way from the Sun." (The temperatures near a supernova vary, but they are all quantitatively high enough to be far above the greatest manageable level; there is no nearby temperature low enough to form a survivable valley.)
- **Mundane, therefore harmless** or **straw superpower**: "Contrary to what many non-astronomers seem to believe, a supernova can't burn hot enough to sear through time itself, so we'll be fine." (False dichotomy: the divine ability is not required for the phenomenon to be dangerous / non-survivable.)
- **Precedented, therefore harmless:** "Really, we've already had supernovas around for a while: there are already devices that produce 'super' amounts of heat by fusing elements low in the periodic table, and they're called thermonuclear weapons. Society has proven well able to regulate existing thermonuclear weapons and prevent them from being acquired by terrorists; there's no reason the same shouldn't be true of supernovas." (Reference class tennis / noncentral fallacy / continuum fallacy: putting supernovas on a continuum with hydrogen bombs doesn't make them able to be handled by similar strategies, nor does finding a class such that it contains both supernovas and hydrogen bombs.)
- **Undefinable, therefore harmless:** "What is 'heat', really? Somebody from Greenland might think 295 Kelvin was 'warm', somebody from the equator might consider the same weather 'cool'. And when exactly does a 'sun shining' become a 'supernova'? This whole idea seems ill-defined." (Someone finding it difficult to make exacting definitions about a physical process doesn't license the conclusion that the physical process is harmless. %%note: It also happens that the distinction between the runaway process in a supernova and a sun shining is empirically sharp; but this is not why the argument is invalid--a super-hot ordinary fire can also be harmful even if we personally are having trouble defining "super" and "hot". %%)
|
adfe86f6-d5b5-44b2-bcf6-e9a39545aaa1
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
Technical AGI safety research outside AI
I think there are many questions whose answers would be useful for technical AGI safety research, but which will probably require expertise outside AI to answer. In this post I list 30 of them, divided into four categories. Feel free to get in touch if you’d like to discuss these questions and why I think they’re important in more detail. I personally think that making progress on the ones in the first category is particularly vital, and plausibly tractable for researchers from a wide range of academic backgrounds.
**Studying and understanding safety problems**
1. How strong are the economic or technological pressures towards building very general AI systems, as opposed to narrow ones? How plausible is the [CAIS model](https://www.fhi.ox.ac.uk/reframing/) of advanced AI capabilities arising from the combination of many narrow services?
2. What are the most compelling arguments for and against [discontinuous](https://intelligence.org/files/IEM.pdf) versus [continuous](https://sideways-view.com/2018/02/24/takeoff-speeds/) takeoffs? In particular, how should we think about the analogy from human evolution, and the scalability of intelligence with compute?
3. What are the tasks via which narrow AI is most likely to have a destabilising impact on society? What might cyber crime look like when many important jobs have been automated?
4. How plausible are safety concerns about [economic dominance by influence-seeking agents](https://www.alignmentforum.org/posts/HBxe6wdjxK239zajf/more-realistic-tales-of-doom), as well as [structural loss of control](https://www.lawfareblog.com/thinking-about-risks-ai-accidents-misuse-and-structure) scenarios? Can these be reformulated in terms of standard economic ideas, such as [principal-agent problems](http://www.overcomingbias.com/2019/04/agency-failure-ai-apocalypse.html) and the effects of automation?
5. How can we make the concepts of agency and goal-directed behaviour more specific and useful in the context of AI (e.g. building on Dennett’s work on the intentional stance)? How do they relate to intelligence and the [ability to generalise](https://www.cser.ac.uk/research/paradigms-AGI/) across widely different domains?
6. What are the strongest arguments that have been made about why advanced AI might pose an existential threat, stated as clearly as possible? How do the different claims relate to each other, and which inferences or assumptions are weakest?
**Solving safety problems**
1. What techniques used in studying animal brains and behaviour will be most helpful for analysing AI systems [and their behaviour](https://www.nature.com/articles/s41586-019-1138-y), particularly with the goal of rendering them interpretable?
2. What is the most important information about deployed AI that decision-makers will need to track, and how can we create interfaces which communicate this effectively, making it visible and salient?
3. What are the most effective ways to gather huge numbers of human judgments about potential AI behaviour, and how can we ensure that such data is high-quality?
4. How can we empirically test the [debate](https://openai.com/blog/ai-safety-needs-social-scientists/) and [factored cognition](https://ought.org/research/factored-cognition) hypotheses? How plausible are the [assumptions](https://ai-alignment.com/towards-formalizing-universality-409ab893a456) about the decomposability of cognitive work via language which underlie debate and [iterated distillation and amplification](https://ai-alignment.com/iterated-distillation-and-amplification-157debfd1616)?
5. How can we distinguish between AIs helping us better understand what we want and AIs changing what we want (both as individuals and as a civilisation)? How easy is the latter to do; and how easy is it for us to identify?
6. Various questions in decision theory, logical uncertainty and game theory relevant to [agent foundations](https://intelligence.org/files/TechnicalAgenda.pdf).
7. How can we create [secure](https://forum.effectivealtruism.org/posts/ZJiCfwTy5dC4CoxqA/information-security-careers-for-gcr-reduction) containment and supervision protocols to use on AI, which are also robust to external interference?
8. What are the best communication channels for conveying goals to AI agents? In particular, which ones are most likely to incentivise optimisation of the goal [specified through the channel](https://www.alignmentforum.org/s/SBfqYgHf2zvxyKDtB/p/5bd75cc58225bf06703754b3), rather than [modification of the communication channel itself](https://www.ijcai.org/proceedings/2017/0656.pdf)?
9. How closely linked is the human motivational system to our intellectual capabilities - to what extent does the [orthogonality thesis](https://www.fhi.ox.ac.uk/wp-content/uploads/Orthogonality_Analysis_and_Metaethics-1.pdf) apply to human-like brains? What can we learn from the range of variation in human motivational systems (e.g. induced by brain disorders)?
10. What were the features of the human ancestral environment and evolutionary “training process” that contributed the most to our empathy and altruism? What are the analogues of these in our current AI training setups, and how can we increase them?
11. What are the features of our current cultural environments that contribute the most to altruistic and cooperative behaviour, and how can we replicate these while training AI?
**Forecasting AI**
1. What are the most likely pathways to AGI and the milestones and timelines involved?
2. How do our best systems so far [compare to animals](http://animalaiolympics.com/) and humans, both in terms of performance and in terms of brain size? What do we know from animals about how cognitive abilities scale with brain size, learning time, environmental complexity, etc?
3. What are the economics and logistics of building microchips and datacenters? How will the availability of compute change under different demand scenarios?
4. In what ways is AI usefully [analogous or disanalogous](http://rationallyspeakingpodcast.org/show/rs-231-helen-toner-on-misconceptions-about-china-and-artific.html) to the industrial revolution; electricity; and nuclear weapons?
5. How will the progression of narrow AI shape public and government opinions and narratives towards it, and how will that influence the directions of AI research?
6. Which tasks will there be most economic pressure to automate, and how much money might realistically be involved? What are the biggest social or legal barriers to automation?
7. What are the most salient features of the history of AI, and how should they affect our understanding of the field today?
**Meta**
1. How can we best grow the field of AI safety? See [OpenPhil’s notes on the topic](https://www.openphilanthropy.org/blog/new-report-early-field-growth).
2. How can spread norms in favour of careful, robust testing and other safety measures in machine learning? What can we learn from other engineering disciplines with strict standards, such as aerospace engineering?
3. How can we create infrastructure to improve our ability to accurately predict future development of AI? What are the bottlenecks facing tools like [Foretold.io](https://forum.effectivealtruism.org/posts/5nCijr7A9MfZ48o6f/introducing-foretold-io-a-new-open-source-prediction) and [Metaculus](https://www.metaculus.com/questions/?show-welcome=true), and preventing effective prediction markets from existing?
4. How can we best increase communication and coordination within the AI safety community? What are the major constraints that safety faces on sharing information (in particular ones which other fields don’t face), and how can we overcome them?
5. What norms and institutions should the field of AI safety import from other disciplines? Are there predictable problems that we will face as a research community, or systemic biases which are making us overlook things?
6. What are the biggest disagreements between safety researchers? What’s the distribution of opinions, and what are the key cruxes?
Particular thanks to Beth Barnes and a discussion group at the CHAI retreat for helping me compile this list.
|
e248c3b4-fc70-452b-9921-4463b6d6b903
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : DC Meetup
Discussion article for the meetup : DC Meetup
WHEN: 20 May 2012 03:00:00PM (-0400)
WHERE: National Portrait Gallery, Washington, DC 20001, USA
If the SIAI response to the Givewell critique has been posted, that will be the meetup topic.
Discussion article for the meetup : DC Meetup
|
809a3585-2386-46a6-a5f1-0c0b197146eb
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
Refer the Cooperative AI Foundation’s New COO, Receive $5000
**TL;DR: The** [**Cooperative AI Foundation**](https://www.cooperativeai.com/foundation) **(CAIF) is a new AI safety organisation and we're hiring for a** [**Chief Operating Officer**](https://www.cooperativeai.com/job-listing/chief-operating-officer) **(COO). You can suggest people that you think might be a good fit for the role using** [**this form**](https://docs.google.com/forms/d/e/1FAIpQLSd6OZ2Xlp3n2OLwCuH018dt2VIROxz2WogMRRXWC5MFAK0jRg/viewform?usp=sf_link)**. If you're the first to suggest the person we eventually hire, we'll send you $5000.**
*This post was inspired by conversations with Richard Parr and Cate Hall (though I didn't consult them about the post, and they may not endorse it). Thanks to Anne le Roux and Jesse Clifton for reading a previous draft. Any mistakes are my own.*
Background
==========
The [Cooperative AI Foundation](https://www.cooperativeai.com/foundation) (CAIF, pronounced “safe”) is a new organisation supporting research on the cooperative intelligence of advanced AI systems. We believe that many of the most important problems facing humanity are problems of cooperation, and that AI will be increasingly important when it comes to solving (or exacerbating) such problems. In short, **we’re an A(G)I safety research foundation seeking to build the nascent field of** [**Cooperative AI**](https://www.nature.com/articles/d41586-021-01170-0).
CAIF is supported by an initial endowment of $15 million and [some of the leading thinkers in AI safety and AI governance](https://www.cooperativeai.com/foundation#Trustees), but is currently lacking operational capacity. We’re expanding our team and **our top priority is to hire a** [**Chief Operating Officer**](https://www.cooperativeai.com/job-listing/chief-operating-officer) – a role that will be critical for the scaling and smooth running of the foundation, both now and in the years to come. We believe that this marks an exciting opportunity to have a particularly large impact on the growth of CAIF, the field, and thus on the benefits to humanity that it prioritises.
How You Can Help
================
Do you know someone who might be a good fit for this role? Submit their name (and yours) via [this form](https://docs.google.com/forms/d/e/1FAIpQLSd6OZ2Xlp3n2OLwCuH018dt2VIROxz2WogMRRXWC5MFAK0jRg/viewform?usp=sf_link). CAIF will reach out to the people we think are promising, and if you were the first to suggest the person we eventually hire, we'll send you a **referral bonus of $5000**. The details required from a referral can be found by looking at the form, with the following conditions:
* Referrals must be made by **3 July 2022 23:59 UTC**
* You can't refer yourself (though if you're interested in the role, please [apply](https://2ydtwkl8tw5.typeform.com/to/ERVfu3Hk)!)
* Please **don't** directly post names or personal details in the comments below
* We'll only send you the bonus if the person you suggest (and we hire) isn't someone we'd already considered
* The person you refer doesn't need to already be part of the EA community[[1]](#fn5di05uzqpgy) or be knowledgable about AI safety
* If you've already suggested a name to us (i.e., before this was posted), we'll still send you the bonus
* If you have any questions about the referral scheme, please comment below
Finally, we're also looking for new ways of advertising the role.[[2]](#fnlarl08icxo) If you have suggestions, please post them in the comments below. If we use your suggested method (and we weren't already planning to), we'll send you a **smaller bonus of $250**. Feel free to list all your suggestions in a single comment – we'll send you a bonus for each one that we use.
Why We Posted This
==================
Arguably, the most critical factor in how successful an organisation is (given sufficient funding, at least) is the quality of the people working there. This is especially true for us as a new, small organisation with ambitious plans for growth, and for a role as important as the COO. Because of this, **we are strongly prioritising hiring an excellent person for this role**.
The problem is that finding excellent people is hard (especially for operations roles). Many excellent people that might consider moving to this role are not actively looking for one, and may not already be in our immediate network. This means that **referrals are critical for finding the best person for the job**, hence this post.
$5000 may seem like a lot for simply sending us someone's name, but is a small price to pay in terms of increasing CAIF's impact. Moreover, it's also **well****below****what a recruitment agency would usually charge** for a successful referral to a role like this – and using these agencies is often worth it! Finally, though there is some risk of the referral scheme being exploited, we believe that the upsides outweigh these risks substantially. We suggest that other EA organisations might want to adopt similar schemes in the future.
1. **[^](#fnref5di05uzqpgy)**I owe my appreciation of this point to Cate.
2. **[^](#fnreflarl08icxo)**Like this post, which was suggested by Richard.
|
d7603973-6774-4bb5-8115-7307a1540bf9
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Alignment Newsletter #42
Cooperative IRL as a definition of human-AI group rationality, and an empirical evaluation of theory of mind vs. model learning in HRI
Find all Alignment Newsletter resources [here](http://rohinshah.com/alignment-newsletter/). In particular, you can [sign up](http://eepurl.com/dqMSZj), or look through this [spreadsheet](https://docs.google.com/spreadsheets/d/1PwWbWZ6FPqAgZWOoOcXM8N_tUCuxpEyMbN1NYYC02aM/edit?usp=sharing) of all summaries that have ever been in the newsletter.
Highlights
----------
**[AI Alignment Podcast: Cooperative Inverse Reinforcement Learning](https://futureoflife.org/2019/01/17/cooperative-inverse-reinforcement-learning-with-dylan-hadfield-menell/)** *(Lucas Perry and Dylan Hadfield-Menell)* (summarized by Richard): Dylan puts forward his conception of Cooperative Inverse Reinforcement Learning as a definition of what it means for a human-AI system to be rational, given the information bottleneck between a human's preferences and an AI's observations. He notes that there are some clear mismatches between this problem and reality, such as the CIRL assumption that humans have static preferences, and how fuzzy the abstraction of "rational agents with utility functions" becomes in the context of agents with bounded rationality. Nevertheless, he claims that this is a useful unifying framework for thinking about AI safety.
Dylan argues that the process by which a robot learns to accomplish tasks is best described not just as maximising an objective function but instead in a way which includes the system designer who selects and modifies the optimisation algorithms, hyperparameters, etc. In fact, he claims, it doesn't make sense to talk about how well a system is doing without talking about the way in which it was instructed and the type of information it got. In CIRL, this is modeled via the combination of a "teaching strategy" and a "learning strategy". The former can take many forms: providing rankings of options, or demonstrations, or binary comparisons, etc. Dylan also mentions an extension of this in which the teacher needs to learn their own values over time. This is useful for us because we don't yet understand the normative processes by which human societies come to moral judgements, or how to integrate machines into that process.
**[On the Utility of Model Learning in HRI](https://arxiv.org/abs/1901.01291)** *(Rohan Choudhury, Gokul Swamy et al)*: In human-robot interaction (HRI), we often require a model of the human that we can plan against. Should we use a specific model of the human (a so-called "theory of mind", where the human is approximately optimizing some unknown reward), or should we simply learn a model of the human from data? This paper presents empirical evidence comparing three algorithms in an autonomous driving domain, where a robot must drive alongside a human.
The first algorithm, called Theory of Mind based learning, models the human using a theory of mind, infers a human reward function, and uses that to predict what the human will do, and plans around those actions. The second algorithm, called Black box model-based learning, trains a neural network to directly predict the actions the human will take, and plans around those actions. The third algorithm, model-free learning, simply applies Proximal Policy Optimization (PPO), a deep RL algorithm, to directly predict what action the robot should take, given the current state.
Quoting from the abstract, they "find that there is a significant sample complexity advantage to theory of mind methods and that they are more robust to covariate shift, but that when enough interaction data is available, black box approaches eventually dominate". They also find that when the ToM assumptions are significantly violated, then the black-box model-based algorithm will vastly surpass ToM. The model-free learning algorithm did not work at all, probably because it cannot take advantage of knowledge of the dynamics of the system and so the learning problem is much harder.
**Rohin's opinion:** I'm always happy to see an experimental paper that tests how algorithms perform, I think we need more of these.
You might be tempted to think of this as evidence that in deep RL, a model-based method should outperform a model-free one. This isn't exactly right. The first ToM and black box model-based algorithms use an exact model of the dynamics of the environment modulo the human, that is, they can exactly predict the next state given the current state, the robot action, and the human action. The model-free algorithm must learn this from scratch, so it isn't an apples-to-apples comparison. (Typically in deep RL, both model-based and model-free algorithms have to learn the environment dynamics.) However, you *can* think of the ToM as a model-based method and the Black-box model-based algorithm as a model-free algorithm, where both algorithms have to learn the *human model*instead of the more traditional environment dynamics. With that analogy, you would conclude that model-based algorithms will be more sample efficient and more performant in low-data regimes, but will be outperformed by model-free algorithms with sufficient data, which agrees with my intuitions.
This kind of effect is a major reason for my position that the first powerful AI systems will be modular (analogous to model-based systems), but that they will eventually be replaced by more integrated, end-to-end systems (analogous to model-free systems). Initially, we will be in a (relatively speaking) low-data regime, where modular systems excel, but over time there will be more data and compute and we will transition to regimes where end-to-end systems will solve the same tasks better (though we may then have modular systems for more difficult tasks).
Technical AI alignment
======================
### Iterated amplification sequence
[The reward engineering problem](https://www.alignmentforum.org/posts/4nZRzoGTqg8xy5rr8/the-reward-engineering-problem) *(Paul Christiano)*: The reward engineering problem is the problem of designing some form of reward feedback such that if the agent learns to get high reward, then we are happy with the resulting behavior. We assume that an overseer H is providing reward for an agent A, with H smarter than A.
(Aside: Why are we assuming H is smarter, when we are typically worried about AI that is more intelligent than we are? Because we could hope to use AI tools to create this reward function, so that the human + AI team is smarter than the AI being trained. In iterated amplification, this corresponds to the distillation step.)
We could imagine three approaches: direct supervision (where H provides a reward for every action A takes), imitation learning (where A tries to mimic H, perhaps by trying to fool a discriminator that distinguishes between A and H), and inverse reinforcement learning (where we infer a reward function by observing H's behavior and use that to supervise A).
With all of these approaches, we might hope that since H is smarter than A, A will not be able to trick H with some behavior that gets high reward but is actually undesirable. However, this argument has a major flaw. When A chooses an action, the process or computation by which it chooses that action is important information, which by default (especially with neural nets) only A has access to, and so this can allow it to fool H. For example, if A is tasked with drawing original artwork, it might copy and slightly change existing artwork, which H may not realize if it cannot see how the artwork was made. We could hope to fix this problem with transparency or explanations, but this requires a lot more research.
Imitation learning and IRL have the problem that A may not be capable of doing what H does. In that case, it will be off-distribution and may have weird behavior. Direct supervision doesn't suffer from this problem, but it is very time-inefficient. This could potentially be fixed using semi-supervised learning techniques.
**Rohin's opinion:** The information asymmetry problem between H and A seems like a major issue. For me, it's the strongest argument for why transparency is a *necessary* ingredient of a solution to alignment. The argument against imitation learning and IRL is quite strong, in the sense that it seems like you can't rely on either of them to capture the right behavior. These are stronger than the arguments against [ambitious value learning](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/5eX8ko7GCxwR5N9mN) ([AN #31](https://mailchi.mp/7d0e3916e3d9/alignment-newsletter-31)) because here we assume that H is smarter than A, which we could not do with ambitious value learning. So it does seem to me that direct supervision (with semi-supervised techniques and robustness) is the most likely path forward to solving the reward engineering problem.
There is also the question of whether it is necessary to solve the reward engineering problem. It certainly seems necessary in order to implement iterated amplification given current systems (where the distillation step will be implemented with optimization, which means that we need a reward signal), but might not be necessary if we move away from optimization or if we build systems using some technique other than iterated amplification (though even then it seems very useful to have a good reward engineering solution).
[Capability amplification](https://www.alignmentforum.org/posts/t3AJW5jP3sk36aGoC/capability-amplification) *(Paul Christiano)*: Capability amplification is the problem of taking some existing policy and producing a better policy, perhaps using much more time and compute. It is a particularly interesting problem to study because it could be used to define the goals of a powerful AI system, and it could be combined with [reward engineering](https://www.alignmentforum.org/posts/4nZRzoGTqg8xy5rr8/the-reward-engineering-problem) above to create a powerful aligned system. (Capability amplification and reward engineering are analogous to amplification and distillation respectively.) In addition, capability amplification seems simpler than the general problem of "build an AI that does the right thing", because we get to start with a weak policy A rather than nothing, and were allowed to take lots of time and computation to implement the better policy. It would be useful to tell whether the "hard part" of value alignment is in capability amplification, or somewhere else.
We can evaluate capability amplification using the concepts of reachability and obstructions. A policy C is *reachable* from another policy A if there is some chain of policies from A to C, such that at each step capability amplification takes you from the first policy to something at least as good as the second policy. Ideally, all policies would be reachable from some very simple policy. This is impossible if there exists an *obstruction*, that is a partition of policies into two sets L and H, such that it is impossible to amplify any policy in L to get a policy that is at least as good as some policy in H. Intuitively, an obstruction prevents us from getting to arbitrarily good behavior, and means that all of the policies in H are not reachable from any policy in L.
We can do further work on capability amplification. With theory, we can search for challenging obstructions, and design procedures that overcome them. With experiment, we can study capability amplification with humans (something which [Ought](https://ought.org/) is now doing).
**Rohin's opinion:** There's a clear reason for work on capability amplification: it could be used as a part of an implementation of iterated amplification. However, this post also suggests another reason for such work -- it may help us determine where the "hard part" of AI safety lies. Does it help to assume that you have lots of time and compute, and that you have access to a weaker policy?
Certainly if you just have access to a weaker policy, this doesn't make the problem any easier. If you could take a weak policy and amplify it into a stronger policy efficiently, then you could just repeatedly apply this policy-improvement operator to some very weak base policy (say, a neural net with random weights) to solve the full problem. (In other variants, you have a much stronger aligned base policy, eg. the human policy with short inputs and over a short time horizon; in that case this assumption is more powerful.) The more interesting assumption is that you have lots of time and compute, which does seem to have a lot of potential. I feel pretty optimistic that a human thinking for a long time could reach "superhuman performance" by our current standards; capability amplification asks if we can do this in a particular structured way.
### Value learning sequence
[Reward uncertainty](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/ZiLLxaLB5CCofrzPp) *(Rohin Shah)*: Given that we need human feedback for the AI system to stay "on track" as the environment changes, we might design a system that keeps an estimate of the reward, chooses actions that optimize that reward, but also updates the reward over time based on feedback. This has a few issues: it typically assumes that the human Alice knows the true reward function, it makes a possibly-incorrect assumption about the meaning of Alice's feedback, and the AI system still looks like a long-term goal-directed agent where the goal is the current reward estimate.
This post takes the above AI system and considers what happens if you have a distribution over reward functions instead of a point estimate, and during action selection you take into account future updates to the distribution. (This is the setup of [Cooperative Inverse Reinforcement Learning](https://arxiv.org/abs/1606.03137).) While we still assume that Alice knows the true reward function, and we still require an assumption about the meaning of Alice's feedback, the resulting system looks less like a goal-directed agent.
In particular, the system no longer has an incentive to disable the system that learns values from feedback: while previously it changed the AI system's goal (a negative effect from the goal's perspective), now it provides more information about the goal (a positive effect). In addition, the system has more of an incentive to let itself be shut down. If a human is about to shut it down, it should update strongly that whatever it was doing was very bad, causing a drastic update on reward functions. It may still prevent us from shutting it down, but it will at least stop doing the bad thing. Eventually, after gathering enough information, it would converge on the true reward and do the right thing. Of course, this is assuming that the space of rewards is well-specified, which will probably not be true in practice.
[Following human norms](https://www.alignmentforum.org/posts/eBd6WvzhuqduCkYv3/following-human-norms) *(Rohin Shah)*: One approach to preventing catastrophe is to constrain the AI system to never take catastrophic actions, and not focus as much on what to do (which will be solved by progress in AI more generally). In this setting, we hope that our AI systems accelerate our rate of progress, but we remain in control and use AI systems as tools that allow us make better decisions and better technologies. Impact measures / side effect penalties aim to *define* what not to do. What if we instead *learn* what not to do? This could look like inferring and following human norms, along the lines of [ad hoc teamwork](http://www.cs.utexas.edu/users/ai-lab/?AdHocTeam).
This is different from narrow value learning for a few reasons. First, narrow value learning also learns what *to* do. Second, it seems likely that norm inference only gives good results in the context of groups of agents, while narrow value learning could be applied in singe agent settings.
The main advantages of learning norms is that this is something that humans do quite well, so it may be significantly easier than learning "values". In addition, this approach is very similar to our ways of preventing humans from doing catastrophic things: there is a shared, external system of norms that everyone is expected to follow. However, norm following is a weaker standard than [ambitious value learning](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/5eX8ko7GCxwR5N9mN) ([AN #31](https://mailchi.mp/7d0e3916e3d9/alignment-newsletter-31)), and there are more problems as a result. Most notably, powerful AI systems will lead to rapidly evolving technologies, that cause big changes in the environment that might require new norms; norm-following AI systems may not be able to create or adapt to these new norms.
### Agent foundations
[CDT Dutch Book](https://www.alignmentforum.org/posts/wkNQdYj47HX33noKv/cdt-dutch-book) *(Abram Demski)*
[CDT=EDT=UDT](https://www.alignmentforum.org/posts/WkPf6XCzfJLCm2pbK/cdt-edt-udt) *(Abram Demski)*
### Learning human intent
**[AI Alignment Podcast: Cooperative Inverse Reinforcement Learning](https://futureoflife.org/2019/01/17/cooperative-inverse-reinforcement-learning-with-dylan-hadfield-menell/)** *(Lucas Perry and Dylan Hadfield-Menell)*: Summarized in the highlights!
**[On the Utility of Model Learning in HRI](https://arxiv.org/abs/1901.01291)** *(Rohan Choudhury, Gokul Swamy et al)*: Summarized in the highlights!
[What AI Safety Researchers Have Written About the Nature of Human Values](https://www.lesswrong.com/posts/GermiEmcS6xuZ2gBh/what-ai-safety-researchers-have-written-about-the-nature-of) *(avturchin)*: This post categorizes theories of human values along three axes. First, how complex is the description of the values? Second, to what extent are "values" defined as a function of behavior (as opposed to being a function of eg. the brain's algorithm)? Finally, how broadly applicable is the theory: could it apply to arbitrary minds, or only to humans? The post then summarizes different positions on human values that different researchers have taken.
**Rohin's opinion:** I found the categorization useful for understanding the differences between views on human values, which can be quite varied and hard to compare.
[Risk-Aware Active Inverse Reinforcement Learning](http://arxiv.org/abs/1901.02161) *(Daniel S. Brown, Yuchen Cui et al)*: This paper presents an algorithm that actively solicits demonstrations on states where it could potentially behave badly due to its uncertainty about the reward function. They use Bayesian IRL as their IRL algorithm, so that they get a distribution over reward functions. They use the most likely reward to train a policy, and then find a state from which that policy has high risk (because of the uncertainty over reward functions). They show in experiments that this performs better than other active IRL algorithms.
**Rohin's opinion:** I don't fully understand this paper -- how exactly are they searching over states, when there are exponentially many of them? Are they sampling them somehow? It's definitely possible that this is in the paper and I missed it, I did skim it fairly quickly.
Other progress in AI
====================
### Reinforcement learning
[Soft Actor-Critic: Deep Reinforcement Learning for Robotics](https://ai.googleblog.com/2019/01/soft-actor-critic-deep-reinforcement.html) *(Tuomas Haarnoja et al)*
### Deep learning
[A Comprehensive Survey on Graph Neural Networks](http://arxiv.org/abs/1901.00596) *(Zonghan Wu et al)*
[Graph Neural Networks: A Review of Methods and Applications](http://arxiv.org/abs/1812.08434) *(Jie Zhou, Ganqu Cui, Zhengyan Zhang et al)*
News
====
[Olsson to Join the Open Philanthropy Project](https://twitter.com/catherineols/status/1085702568494301185) (summarized by Dan H): Catherine Olsson, a researcher at Google Brain who was previously at OpenAI, will be joining the Open Philanthropy Project to focus on grant making for reducing x-risk from advanced AI. Given her first-hand research experience, she has knowledge of the dynamics of research groups and a nuanced understanding of various safety subproblems. Congratulations to both her and OpenPhil.
[Announcement: AI alignment prize round 4 winners](https://www.lesswrong.com/posts/nDHbgjdddG5EN6ocg/announcement-ai-alignment-prize-round-4-winners) *(cousin\_it)*: The last iteration of the AI alignment prize has concluded, with awards of $7500 each to [Penalizing Impact via Attainable Utility Preservation](https://www.alignmentforum.org/posts/mDTded2Dn7BKRBEPX/penalizing-impact-via-attainable-utility-preservation) ([AN #39](https://mailchi.mp/036ba834bcaf/alignment-newsletter-39)) and [Embedded Agency](https://www.alignmentforum.org/s/Rm6oQRJJmhGCcLvxh) ([AN #31](https://mailchi.mp/7d0e3916e3d9/alignment-newsletter-31), [AN #32](https://mailchi.mp/8f5d302499be/alignment-newsletter-32)), and $2500 each to [Addressing three problems with counterfactual corrigibility](https://www.alignmentforum.org/posts/owdBiF8pj6Lpwwdup/addressing-three-problems-with-counterfactual-corrigibility) ([AN #30](https://mailchi.mp/c1f376f3a12e/alignment-newsletter-30)) and [Three AI Safety Related Ideas](https://www.alignmentforum.org/posts/vbtvgNXkufFRSrx4j/three-ai-safety-related-ideas)/[Two Neglected Problems in Human-AI Safety](https://www.alignmentforum.org/posts/HTgakSs6JpnogD6c2/two-neglected-problems-in-human-ai-safety) ([AN #38](https://mailchi.mp/588354e4b91d/alignment-newsletter-38)).
|
b692083a-d059-4389-94d3-a861b4f28bbc
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why do you need the story?
* Boy: Why are you washing your hands?
* Shaman: Because this root is poisonous.
* Boy: Then why pull it out of the ground?
* Shaman: Because the pulp within it can cure the mosquito disease.
* Boy: But, I thought you said it was poisonous.
* Shaman: It is, but the outside is more so than the inside.
* Boy: Still, if it's poisonous, how can it cure things.
* Shaman: It's the dose that makes the poison.
* Boy: So can I eat the pulp?
* Shaman: No, because you are not sick, it's the disease that makes the medicine.
* Boy: So it's good for a sick man, but bad for me?
* Shaman: Yes, because, the sick man must suffer in order to be cured.
* Boy: Why?
* Shaman: Because he made the spirits angry, that's why he got the disease.
* Boy: So why will suffering make it better?
* Shaman: Suffering is part of admitting guilt and seeking forgiveness, the root helps the sick man atone for his transgression. Afterwards, the spirits lift the disease.
* Boy: The spirits seem evil.
* Shaman: The spirits are neither evil, nor are they, good, as we understand it.
* Boy: Ohhh
* Shaman: Here, sit, let me tell you how our world was made...
----------------------------------------
Ok, that sounds like a half believable wise mystic, right? That would make for a decent intro to a mediocre young-adult fantasy coming of age powertrip novel
Now, imagine if the shaman just left it as "The root is poisonous if you are not sick, but it helps if you are sick and eat a bit of its pulp, most of the time". No rules of thumb about dose making the poison, no speculations as to how it works, no postulation of metaphysical rules, no analogies to morality, no grand story for the creation of the universe.
That'd be one boring shaman, right? Outright unbelievable. Nobody would trust such a witcherman to take them in the middle of the jungle and give them a psychedelic brew, he's daft. The other guy though... he might be made of the right stuff to hold ayahuasca ceremonies.
--------------
|
f82e2a66-e327-4ac7-9ba0-49506b27eb1c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Analysis of Algorithms and Partial Algorithms
|
30a4d42d-7152-4928-bf80-816d516b9b37
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Maze-solving agents: Add a top-right vector, make the agent go to the top-right
Overview: We modify the goal-directed behavior of a trained network, without any gradients or finetuning. We simply add or subtract "motivational vectors" which we compute in a straightforward fashion.
In the original post, we defined a "cheese vector" to be "the difference in activations when the cheese is present in a maze, and when the cheese is not present in the same maze." By subtracting the cheese vector from all forward passes in a maze, the network ignored cheese.
I (Alex Turner) present a "top right vector" which, when added to forward passes in a range of mazes, attracts the agent to the top-right corner of each maze. Furthermore, the cheese and top-right vectors compose with each other, allowing (limited but substantial) mix-and-match modification of the network's runtime goals.
I provide further speculation about the algebraic value editing conjecture:
> It's possible to deeply modify a range of alignment-relevant model properties, without retraining the model, via techniques as simple as "run forward passes on prompts which e.g. prompt the model to offer nice- and not-nice completions, and then take a 'niceness vector', and then add the niceness vector to future forward passes."
I close by asking the reader to make predictions about our upcoming experimental results on language models.
This post presents some of the results in this top-right vector Google Colab, and then offers speculation and interpretation.
I produced the results in this post, but the vector was derived using a crucial observation from Peli Grietzer. Lisa Thiergart independently analyzed top-right-seeking tendencies, and had previously searched for a top-right vector. A lot of the content and infrastructure was made possible by my MATS 3.0 team: Ulisse Mini, Peli Grietzer, and Monte MacDiarmid. Thanks also to Lisa Thiergart, Aryan Bhatt, Tamera Lanham, and David Udell for feedback and thoughts.
Background
This post is straightforward, as long as you remember a few concept
|
4f09a2af-611f-4875-bab7-77b6a0468cdf
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Genetically Modified Humans Born (Allegedly)
I realize normally we don't talk about the news or hot-button issues, but this is of sufficiently high importance I am posting anyway.
There is a link from Nature News on Monday here. There is a link from MIT Technology Review discussing the documents uploaded by the team behind the effort here.
Summarizing the report I heard on the radio this morning:
* The lead scientist is He Jiankui, with a team at Southern University of Science and Technology, in Shenzhen.
* 7 couples in the experiment, each with HIV+ fathers and HIV- mothers.
* CRISPR was used to genetically edit embryos to eliminate the CCR5 gene, providing HIV resistance.
* Allegedly twin girls have been born with these edits.
I don't think DNA testing of the twins has taken place yet. If anyone has a line on good, nuanced sources, I'd be interested in hearing about it.
|
7b75a4f0-b12e-4e5e-88d6-552aa253c60f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Less Wrong in Dublin
Discussion article for the meetup : Less Wrong in Dublin
WHEN: 02 February 2013 04:30:25PM (+0000)
WHERE: 28 Dame St Dublin, Co. Dublin (The Mercantile)
A meeting of minds.
Discussion article for the meetup : Less Wrong in Dublin
|
d8933ac0-a901-45bb-8443-e9c6284c4b0f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Joan of Arc Challenge For Objective List Theory
Introduction
The Joan of Arc challenge to objective list theory, as I shall argue, shows that only happiness is of intrinsic value. Pluralists—people who say that there are many things of intrinsic value—otherwise known as objective list theorists (maybe there’s some technical distinction between the two, but if so, I haven’t been able to find it) think that there are several things that are of intrinsic value. Objective list theorists hold roughly the following: that which is of intrinsic value is only happiness, knowledge, relationships, and achievements. To paraphrase Hitchens’ famous quote about those who proclaim “there is no god but Allah,” such people end their sentence a few words too late.
The basic idea behind the Joan of Arc challenge is that all of the things other than happiness that are on the objective list potentially hinge on whether various people take innocuous actions that no one will ever find out about. As a consequence, objective list theory has deeply counterintuitive implications about what you should do in private—holding that people being harmed is desirable. This objection will become clearer in the later sections.
All in all, I think this is potentially the second or third best argument for hedonism, after the lopsided lives challenge and maybe also the argument advanced here.
Knowledge
Lots of people think that they know something about Joan of Arc. She was burned to death, had a rap battle against Miley Cyrus, stood up for . . . (I’m actually realizing I know embarrassingly little about Joan of Arc, though I think it was something religious—maybe to do with the beginning of Protestantism?). But what if . . . everything you know about Joan of Arc is a lie? What if it was all the product of a grand conspiracy—Joan of Arc wasn’t really burned at the stakes? What if she actually lived out her life in peace and happiness and harmony?
No, I obviously don’t think that’s actually the case. But if it were, that would be good, right? If
|
430f0bff-b81f-4415-8685-8bb56ce24e1c
|
StampyAI/alignment-research-dataset/blogs
|
Blogs
|
August 2018 Newsletter
#### Updates
* New posts to the new [AI Alignment Forum](https://www.alignmentforum.org): [Buridan’s Ass in Coordination Games](https://www.alignmentforum.org/posts/4xpDnGaKz472qB4LY/buridan-s-ass-in-coordination-games); [Probability is Real, and Value is Complex](https://www.alignmentforum.org/posts/oheKfWA7SsvpK7SGp/probability-is-real-and-value-is-complex); [Safely and Usefully Spectating on AIs Optimizing Over Toy Worlds](https://www.alignmentforum.org/posts/ikN9qQEkrFuPtYd6Y/safely-and-usefully-spectating-on-ais-optimizing-over-toy)
* MIRI Research Associate Vanessa Kosoy wins a $7500 AI Alignment Prize for “[The Learning-Theoretic AI Alignment Research Agenda](https://agentfoundations.org/item?id=1816).” Applications for [the prize’s next round](https://www.lesswrong.com/posts/juBRTuE3TLti5yB35/announcement-ai-alignment-prize-round-3-winners-and-next) will be open through December 31.
* Interns from MIRI and the Center for Human-Compatible AI collaborated at an AI safety [research workshop](https://intelligence.org/workshops/#july-2018).
* This year’s [AI Summer Fellows Program](http://www.rationality.org/workshops/apply-aisfp) was very successful, and its one-day blogathon resulted in a number of interesting write-ups, such as [Dependent Type Theory and Zero-Shot Reasoning](https://www.alignmentforum.org/posts/Xfw2d5horPunP2MSK/dependent-type-theory-and-zero-shot-reasoning), [Conceptual Problems with Utility Functions](https://www.alignmentforum.org/posts/Nx4DsTpMaoTiTp4RQ/conceptual-problems-with-utility-functions) (and [follow-up](https://www.alignmentforum.org/posts/QmeguSp4Pm7gecJCz/conceptual-problems-with-utility-functions-second-attempt-at)), [Complete Class: Consequentialist Foundations](https://www.alignmentforum.org/posts/sZuw6SGfmZHvcAAEP/complete-class-consequentialist-foundations), and [Agents That Learn From Human Behavior Can’t Learn Human Values That Humans Haven’t Learned Yet](https://www.alignmentforum.org/posts/DfewqowdzDdCD7S9y/agents-that-learn-from-human-behavior-can-t-learn-human).
* See Rohin Shah’s [alignment newsletter](https://www.alignmentforum.org/posts/EQ9dBequfxmeYzhz6/alignment-newsletter-15-07-16-18) for more discussion of recent posts to the new AI Alignment Forum.
#### News and links
* The Future of Humanity Institute is seeking [project managers](https://www.fhi.ox.ac.uk/project-managers/) for its Research Scholars Programme and its Governance of AI Program.
The post [August 2018 Newsletter](https://intelligence.org/2018/08/27/august-2018-newsletter/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org).
|
ae3b4690-a04c-430f-b2c8-601ba9f2e48d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Plan for mediocre alignment of brain-like [model-based RL] AGI
(This post is a more simple, self-contained, and pedagogical version of Post #14 of Intro to Brain-Like AGI Safety.)
(Vaguely related to this Alex Turner post and this John Wentworth post.)
I would like to have a technical plan for which there is a strong robust reason to believe that we’ll get an aligned AGI and a good future. This post is not such a plan.
However, I also don’t have a strong reason to believe that this plan wouldn’t work. Really, I want to throw up my hands and say “I don’t know whether this would lead to a good future or not”. By “good future” here I don’t mean optimally-good—whatever that means—but just “much better than the world today, and certainly much better than a universe full of paperclips”. I currently have no plan, not even a vague plan, with any prayer of getting to an optimally-good future. That would be a much narrower target to hit.
Even so, that makes me more optimistic than at least some people.[1] Or at least, more optimistic about this specific part of the story. In general I think many things can go wrong as we transition to the post-AGI world—see discussion by Dai & Soares—and overall I feel very doom-y, particularly for reasons here.
This plan is specific to the possible future scenario (a.k.a. “threat model” if you’re a doomer like me) that future AI researchers will develop “brain-like AGI”, i.e. learning algorithms that are similar to the brain’s within-lifetime learning algorithms. (I am not talking about evolution-as-a-learning-algorithm.) These algorithms, I claim, are in the general category of model-based reinforcement learning. Model-based RL is a big and heterogeneous category, but I suspect that for any kind of model-based RL AGI, this plan would be at least somewhat applicable. For very different technological paths to AGI, this post is probably pretty irrelevant.
But anyway, if someone published an algorithm for x-risk-capable brain-like AGI tomorrow, and we urgently needed to do something, this blog post i
|
e61976b8-e546-4472-b737-9b94268fe2bc
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Causal confusion as an argument against the scaling hypothesis
Abstract
We discuss the possibility that causal confusion will be a significant alignment and/or capabilities limitation for current approaches based on "the scaling paradigm": unsupervised offline training of increasingly large neural nets with empirical risk minimization on a large diverse dataset. In particular, this approach may produce a model which uses unreliable (“spurious”) correlations to make predictions, and so fails on “out-of-distribution” data taken from situations where these correlations don’t exist or are reversed. We argue that such failures are particularly likely to be problematic for alignment and/or safety in the case when a system trained to do prediction is then applied in a control or decision-making setting.
We discuss:
* Arguments for this position
* Counterarguments
* Possible approaches to solving the problem
* Key Cruxes for this position and possible fixes
* Practical implications for capability and alignment
* Relevant research directions
We believe this topic is important because many researchers seem to view scaling as a path toward AI systems that 1) are highly competent (e.g. human-level or superhuman), 2) understand human concepts, and 3) reason with human concepts.
We believe the issues we present here are likely to prevent (3), somewhat less likely to prevent (2), and even less likely to prevent (1) (but still likely enough to be worth considering). Note that (1) and (2) have to do with systems’ capabilities, and (3) with their alignment; thus this issue seems likely to be differentially bad from an alignment point of view.
Our goal in writing this document is to clearly elaborate our thoughts, attempt to correct what we believe may be common misunderstandings, and surface disagreements and topics for further discussion and research.
A DALL-E 2 generation for "a green stop sign in a field of red flowers".
Current foundation models still fail on examples that seem simple for humans, and causal confusion and spurio
|
699cf16f-5e64-4247-bd83-169b8e6b2989
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
My highly personal skepticism braindump on existential risk from artificial intelligence.
**Summary**
-----------
This document seeks to outline why I feel uneasy about high existential risk estimates from AGI (e.g., 80% doom by 2070). When I try to verbalize this, I view considerations like
* selection effects at the level of which arguments are discovered and distributed
* community epistemic problems, and
* increased uncertainty due to chains of reasoning with imperfect concepts
as real and important.
I still think that existential risk from AGI is important. But I don’t view it as certain or close to certain, and I think that something is going wrong when people see it as all but assured.
**Discussion of weaknesses**
----------------------------
I think that this document was important for me personally to write up. However, I also think that it has some significant weaknesses:
1. There is some danger in verbalization leading to rationalization.
2. It alternates controversial points with points that are dead obvious.
3. It is to a large extent a reaction to my imperfectly digested understanding of a worldview pushed around the [ESPR](https://espr-camp.org/)/CFAR/MIRI/LessWrong cluster from 2016-2019, which nobody might hold now.
In response to these weaknesses:
1. I want to keep in mind that I do want to give weight to my gut feeling, and that I might want to update on a feeling of uneasiness rather than on its accompanying reasonings or rationalizations.
2. Readers might want to keep in mind that parts of this post may look like a [bravery debate](https://slatestarcodex.com/2013/05/18/against-bravery-debates/). But on the other hand, I've seen that the points which people consider obvious and uncontroversial vary from person to person, so I don’t get the impression that there is that much I can do on my end for the effort that I’m willing to spend.
3. Readers might want to keep in mind that actual AI safety people and AI safety proponents may hold more nuanced views, and that to a large extent I am arguing against a “Nuño of the past” view.
Despite these flaws, I think that this text was personally important for me to write up, and it might also have some utility to readers.
**Uneasiness about chains of reasoning with imperfect concepts**
----------------------------------------------------------------
### **Uneasiness about conjunctiveness**
It’s not clear to me how conjunctive AI doom is. Proponents will argue that it is very disjunctive, that there are lot of ways that things could go wrong. I’m not so sure.
In particular, when you see that a parsimonious decomposition (like Carlsmith’s) tends to generate lower estimates, you can conclude:
1. That the method is producing a biased result, and trying to account for that
2. That the topic under discussion is, in itself, conjunctive: that there are several steps that need to be satisfied. For example, “AI causing a big catastrophe” and “AI causing human exinction given that it has caused a large catastrophe” seem like they are two distinct steps that would need to be modelled separately,
I feel uneasy about only doing 1.) and not doing 2.) I think that the principled answer might be to split some probability into each case. Overall, though, I’d tend to think that AI risk is more conjunctive than it is disjunctive
I also feel uneasy about the social pressure in my particular social bubble. I think that the social pressure is for me to just accept [Nate Soares’ argument](https://www.lesswrong.com/posts/cCMihiwtZx7kdcKgt/comments-on-carlsmith-s-is-power-seeking-ai-an-existential) here that Carlsmith’s method is biased, rather than to probabilistically incorporate it into my calculations. As in “oh, yes, people know that conjunctive chains of reasoning have been debunked, Nate Soares addressed that in a blogpost saying that they are biased”.
### **I don’t trust the concepts**
My understanding is that MIRI and others’ work started in the 2000s. As such, their understanding of the shape that an AI would take doesn’t particularly resemble current deep learning approaches.
In particular, I think that many of the initial arguments that I most absorbed were motivated by something like an [AIXI](https://en.wikipedia.org/wiki/AIXI#:~:text=AIXI%20%5B'ai%CC%AFk%CD%A1si%CB%90%5D%20is%20a,2005%20book%20Universal%20Artificial%20Intelligence.) ([Somolonoff induction](https://en.wikipedia.org/wiki/Solomonoff%27s_theory_of_inductive_inference) + some decision theory). Or, alternatively, by imagining what a very buffed-up [Eurisko](https://en.wikipedia.org/wiki/Eurisko) would look like. This seems to be like a fruitful generative approach which can *generate*things that could go wrong, rather than *demonstrating* that something will go wrong, or pointing to failures that we know will happen.
As deep learning attains more and more success, I think that some of the old concerns port over. But I am not sure which ones, to what extent, and in which context. This leads me to reduce some of my probability. Some concerns that apply to a more formidable Eurisko but which may not apply by default to near-term AI systems:
* Alien values
* Maximalist desire for world domination
* Convergence to a utility function
* Very competent strategizing, of the “treacherous turn” variety
* Self-improvement
* etc.
**Uneasiness about in-the-limit reasoning**
One particular form of argument, or chain of reasoning, goes like:
1. An arbitrarily intelligent/capable/powerful process would be of great danger to humanity. This [implies](https://en.wikipedia.org/wiki/Intermediate_value_theorem) that there is some point, either at arbitrary intelligence or before it, such that a very intelligent process would start to be and then definitely be a great danger to humanity.
2. If the field of artificial intelligence continues improving, eventually we will get processes that are first as intelligent/capable/powerful as a single human mind, and then greatly exceed it.
3. This would be dangerous
The thing is, I agree with that chain of reasoning. But I see it as applying in the limit, and I am much more doubtful about it being used to justify specific dangers in the near future. In particular, I think that dangers that may appear in the long-run may manifest in limited and less dangerous form in earlier on.
I see various attempts to give models of AI timelines as approximate. In particular:
* Even if an approach is accurate at predicting when above-human level intelligence/power/capabilities would arise
* This doesn’t mean that the dangers of in-the-limit superintelligence would manifest at the same time
**AGI, so what?**
For a given operationalization of AGI, e.g., good enough to be forecasted on, I think that there is some possibility that we will reach such a level of capabilities, and yet that this will not be very impressive or world-changing, even if it would have looked like magic to previous generations. More specifically, it seems plausible that AI will continue to improve without soon reaching high [shock levels](http://sl4.org/shocklevels.html) which exceed humanity’s ability to adapt.
This would be similar to how the industrial revolution was transformative but not *that* transformative. One possible scenario for this might be a world where we have pretty advanced AI systems, but we have adapted to that, in the same way that we have adapted to electricity, the internet, recommender systems, or social media. Or, in other words, once I concede that AGI could be as transformative as the industrial revolution, I don't have to concede that it would be maximally transformative.
### **I don’t trust chains of reasoning with imperfect concepts**
The concerns in this section, when combined, make me uneasy about chains of reasoning that rely on imperfect concepts. Those chains may be very conjunctive, and they may apply to the behaviour of an in-the-limit-superintelligent system, but they may not be as action-guiding for systems in our near to medium term future.
For an example of the type of problem that I am worried about, but in a different domain, consider Georgism, the idea of deriving all government revenues from a land value tax. From a recent [blogpost](https://daviddfriedman.blogspot.com/2023/01/a-problem-with-georgism.html) by David Friedman: “since it is taxing something in perfectly inelastic supply, taxing it does not lead to any inefficient economic decisions. The site value does not depend on any decisions made by its owner, so a tax on it does not distort his decisions, unlike a tax on income or produced goods.”
Now, this reasoning appears to be sound. Many people have been persuaded by it. However, because the concepts are imperfect, there can still be flaws. One possible flaw might be that the land value would have to be measured, and that inefficiency might come from there. Another possible flaw was recently pointed out by David Friedman in the [blogpost](https://daviddfriedman.blogspot.com/2023/01/a-problem-with-georgism.html) linked above, which I understand as follows: the land value tax rewards counterfactual improvement, and this leads to predictable inefficiencies because you want to be rewarding Shapley value instead, which is much more difficult to estimate.
I think that these issues are fairly severe when attempting to make predictions for events further in the horizon, e.g., ten, thirty years. The concepts shift like sand under your feet.
**Uneasiness about selection effects at the level of arguments**
----------------------------------------------------------------
I am uneasy about what I see as selection effects at the level of arguments. I think that there is a small but intelligent community of people who have spent significant time producing some convincing arguments about AGI, but no community which has spent the same *amount of effort* looking for arguments against.
[Here](https://philiptrammell.com/blog/46) is a neat blogpost by Phil Trammel on this topic.
Here are some excerpts from a casual discussion among [Samotsvety Forecasting](https://samotsvety.org/) team members:
> The selection effect story seems pretty broadly applicable to me. I'd guess most Christian apologists, Libertarians, Marxists, etc. etc. etc. have a genuine sense of dialectical superiority: "All of these common objections are rebutted in our FAQ, yet our opponents aren't even aware of these devastating objections to their position", etc. etc.
>
> You could throw in bias in evaluation too, but straightforward selection would give this impression even to the fair-minded who happen to end up in this corner of idea space. There are many more 'full time' (e.g.) Christian apologists than anti-apologists, so the balance of argumentative resources (and so apparent balance of reason) will often look slanted.
>
> This doesn't mean the view in question is wrong: back in my misspent youth there were similar resources re, arguing for evolution vs. creationists/ID (<https://www.talkorigins.org>/). But it does strongly undercut "but actually looking at the merits clearly favours my team" alone as this isn't truth tracking (more relevant would be 'cognitive epidemiology' steers: more informed people tend to gravitate to one side or another, proponents/opponents appear more epistemically able, etc.)
>
>
>
> ---
>
> An example for me is Christian theology. In particular, consider Aquinas' five proofs of good (summarized in [Wikipedia](https://en.wikipedia.org/wiki/Five_Ways_(Aquinas)#The_Five_Ways)), or the various [ontological arguments](https://en.wikipedia.org/wiki/Ontological_argument). Back in the day, in took me a bit to a) understand what exactly they are saying, and b) understand why they don't go through. The five ways in particular were written to reassure Dominican priests who might be doubting, and in their time they did work for that purpose, because the topic is complex and hard to grasp.
>
>
>
> ---
>
> You should be worried about the 'Christian apologist' (or philosophy of religion, etc.) selection effect when those likely to discuss the view are selected for sympathy for it. Concretely, if on acquaintance with the case for AI risk your reflex is 'that's BS, there's no way this is more than 1/million', you probably aren't going to spend lots of time being a dissident in this 'field' versus going off to do something else.
>
> This gets more worrying the more generally epistemically virtuous folks are 'bouncing off': e.g. neuroscientists who think relevant capabilities are beyond the ken of 'just add moar layers', ML Engineers who think progress in the field is more plodding than extraordinary, policy folks who think it will be basically safe by default etc. The point is this distorts the apparent balance of reason - maybe this is like Marxism, or NGDP targetting, or Georgism, or general semantics, perhaps many of which we will recognise were off on the wrong track.
>
> (Or, if you prefer being strictly object-level, it means the strongest case for scepticism is unlikely to be promulgated. If you could pin folks bouncing off down to explain their scepticism, their arguments probably won't be that strong/have good rebuttals from the AI risk crowd. But if you could force them to spend years working on their arguments, maybe their case would be much more competitive with proponent SOTA).
>
>
>
> ---
>
> It is general in the sense there is a spectrum from (e.g.) evolutionary biology to (e.g.) Timecube theory, but AI risk is somewhere in the range where it is a significant consideration.
>
> It obviously isn't an infallible one: it would apply to early stage contrarian scientific theories and doesn't track whether or not they are ultimately vindicated. You rightly anticipated the base-rate-y reply I would make.
>
> Garfinkel and Shah still think AI is a very big deal, and identifying them at the sceptical end indicates how far afield from 'elite common sense' (or similar) AI risk discussion is. Likewise I doubt that there are some incentives to by a dissident from this consensus means there isn't a general trend in selection for those more intuitively predisposed to AI concern.
>
>
There are some possible counterpoints to this, and other Samotsvety Forecasting team members made those, and that’s fine. But my individual impression is that the selection effects argument packs a whole lot of punch behind it.
One particular dynamic that I’ve seen some gung-ho AI risk people mention is that (paraphrasing): “New people each have their own unique snowflake reasons for rejecting their particular theory of how AI doom will develop. So I can convince each particular person, but only by talking to them individually about their objections.”
So, in illustration, the overall balance could look something like:

Whereas the individual matchup could look something like:

And so you would expect the natural belief dynamics stemming from that type of matchup.
What you would want to do is to have all the evidence for and against, and then weigh it.
I also think that there are selection effects around which evidence surfaces on each side, rather than only around which arguments people start out with.
It is interesting that when people move to the Bay area, this is often very “helpful” for them in terms of updating towards higher AI risk. I think that this is a sign that a bunch of social fuckery is going on. In particular, I think it might be the case that Bay area movement leaders identify arguments for shorter timelines and higher probability of x-risk with “the rational”, which produces strong social incentives to be persuaded and to come up with arguments in one direction.
More specifically, I think that “if I isolate people from their normal context, they are more likely to agree with my idiosyncratic beliefs” is a mechanisms that works for many types of beliefs, not just true ones. And more generally, I think that “AI doom is near” and associated beliefs are a memeplex, and I am inclined to discount their specifics.
**Miscellanea**
---------------
### **Difference between in-argument reasoning and all-things-considered reasoning**
I’d also tend to differentiate between the probability that an argument or a model gives, and the all-things considered probability. For example, I might look at Ajeya’s timeline, and I might generate a probability by inputting my curves in its model. But then I would probably add additional uncertainty on top of that model.
My weak impression is that some of the most gung-ho people do not do this.
### **Methodological uncertainty**
It’s unclear whether we can get good accuracy predicting dynamics that may happen across decades. I might be inclined to discount further based on that. One particular uncertainty that I worry about is that we can get “AI will be a big deal and be dangerous”, but that danger taking a different shape than what we expected.
For this reason, I am more sympathetic to tools other than forecasting for long-term decision-making, e.g., as outlined [here](https://forum.effectivealtruism.org/posts/wyHjpcCxuqFzzRgtX/a-practical-guide-to-long-term-planning-and-suggestions-for).
### **Uncertainty about unknown unknowns**
I think that unknown unknowns mostly delay AGI. E.g., covid, nuclear war, and many other things could lead to supply chain disruptions. There are unknown unknowns in the other direction, but the higher one's probability goes, the more unknown unknowns should shift one towards 50%.
### **Updating on virtue**
I think that *updating on virtue*is a legitimate move. By this I mean to notice how morally or epistemically virtuous someone is, to update based on that about whether their arguments are made in good faith or from a desire to control, and to assign them more or less weight accordingly.
I think that a bunch of people around the CFAR cluster that I was exposed to weren't particularly virtuous and willing to go to great lengths to convince people that AI is important. In particular, I think that isolating people from the normal flow of their lives for extended periods has an unreasonable effectiveness at making them more pliable and receptive to new and weird ideas, whether they are right or wrong. I am a bit freaked out about the extent to which [ESPR](https://espr-camp.org/), a rationality camp for kids in which I participated, did that.
(Brief aside: An ESPR instructor points out that ESPR separated itself from CFAR after 2019, and has been trying to mitigate these factors. I do think that the difference is important, but this post isn't about ESPR in particular but about AI doom skepticism and so will not be taking particular care here.)
Here is a comment from a CFAR cofounder, which has since left the organization, taken from [this](https://www.facebook.com/morphenius/videos/10158119720662635/?comment_id=10158120282677635&reply_comment_id=10158120681527635) Facebook comment thread (paragraph divisions added by me):
> **Question by bystander**: Around 3 minutes, you mention that looking back, you don't think CFAR's real drive was \_actually\_ making people think better. Would be curious to hear you elaborate on what you think the real drive was.
>
> **Answer**: I'm not going to go into it a ton here. It'll take a bit for me to articulate it in a way that really lands as true to me. But a clear-to-me piece is, CFAR always fetishized the end of the world. It had more to do with injecting people with that narrative and propping itself up as important.
>
> We did a lot of moral worrying about what "better thinking" even means and whether we're helping our participants do that, and we tried to fulfill our moral duty by collecting information that was kind of related to that, but that information and worrying could never meaningfully touch questions like "Are these workshops worth doing at all?" We would ASK those questions periodically, but they had zero impact on CFAR's overall strategy.
>
> The actual drive in the background was a lot more like "Keep running workshops that wow people" with an additional (usually consciously (!) hidden) thread about luring people into being scared about AI risk in a very particular way and possibly recruiting them to MIRI-type projects.
>
> Even from the very beginning CFAR simply COULD NOT be honest about what it was doing or bring anything like a collaborative tone to its participants. We would infantilize them by deciding what they needed to hear and practice basically without talking to them about it or knowing hardly anything about their lives or inner struggles, and we'd organize the workshop and lectures to suppress their inclination to notice this and object.
>
> That has nothing to do with grounding people in their inner knowing; it's exactly the opposite. But it's a great tool for feeling important and getting validation and coercing manipulable people into donating time and money to a Worthy Cause™ we'd specified ahead of time. Because we're the rational ones, right? 😛
>
> The switch Anna pushed back in 2016 to CFAR being explicitly about xrisk was in fact a shift to more honesty; it just abysmally failed the is/ought distinction in my opinion. And, CFAR still couldn't quite make the leap to full honest transparency even then. ("Rationality for its own sake for the sake of existential risk" is doublespeak gibberish. Philosophical summersaults won't save the fact that the energy behind a statement like that is more about controlling others' impressions than it is about being goddamned honest about what the desire and intention really is.)
>
>
The dynamics at ESPR, a rationality camp I was involved with, were at times a bit more dysfunctional than that, particularly before 2019. For that reason, I am inclined to update downwards. I think that this is a personal update, and I don’t necessarily expect it to generalize.
I think that some of the same considerations that I have about ESPR might also hold for those who have interacted with people seeking to persuade, e.g., mainline CFAR workshops, 80,000 hours career advising calls, ATLAS, or similar. But to be clear I haven't interacted much with those other groups myself and my sense is that CFAR—which organized the iterations of ESPR up to 2019— went off the guardrails but that these other organizations haven't.
### **Industry vs AI safety community**
It’s unclear to me what the views of industry people are. In particular, the question seems a bit confused. I want to get at the independent impression that people get from working with state-of-the-art AI models. But industry people may already be influenced by AI safety community concerns, so it’s unclear how to isolate the independent impression. Doesn’t seem undoable, though.
**Suggested decompositions**
----------------------------
The above reasons for skepticism lead me to suggest the following decompositions for my forecasting group, Samotsvety, to use when forecasting AGI and its risks:
### **Very broad decomposition**
I:
* Will AGI be a big deal?
* Conditional on it being “a big deal”, will it lead to problems?
* Will those problems be existential?
II:
1. AI capabilities will continue advancing
2. The advancement of AI capabilities will lead to social problems
3. … and eventually to a great catastrophe
4. … and eventually to human extinction
### **Are we right about this stuff decomposition**
1. We are right about this AGI stuff
2. This AGI stuff implies that AGI will be dangerous
3. … and it will lead to human extinction
### **Inside the model/outside the model decomposition**
I:
* Model/Decomposition X gives a probability
* Are the concepts in the decomposition robust enough to support chains of inference?
* What is the probability of existential risk if they aren’t?
I:
* Model/Decomposition X gives a probability
* Is model X roughly correct?
+ Are the concepts in the decomposition robust enough to support chains of inference?
+ Will the implicit assumptions that it is making pan out?
* What is the probability of existential risk if model X is not correct?
**Implications of skepticism**
------------------------------
I view the above as moving me away from certainty that we will get AGI in the short term. For instance, I think that having 70 or 80%+ probabilities on AI catastrophe within our lifetimes is probably just incorrect, insofar as a probability can be incorrect.
Anecdotally, I recently met someone at an EA social event that a) was uncalibrated, e.g., on Open Philanthropy’s [calibration tool](https://www.openphilanthropy.org/calibration), but b) assigned 96% to AGI doom by 2070. Pretty wild stuff.
Ultimately, I’m personally somewhere around 40% for "By 2070, will it become possible and financially feasible to build [advanced-power-seeking](https://arxiv.org/abs/2206.13353) AI systems?", and somewhere around 10% for doom. I don’t think that the difference matters all that much for practical purposes, but:
1. I am marginally more concerned about unknown unknowns and other non-AI risks
2. I would view interventions that increase civilizational robustness (e.g., bunkers) more favourably, because these are a bit more robust to unknown risks and could protect against a wider range or risks
3. I don’t view AGI soon as particularly likely
4. I view a stance which “aims to safeguard humanity through the 21st century” as more appealing than “Oh fuck AGI risk”
**Conclusion**
--------------
I’ve tried to outline some factors about why I feel uneasy with high existential risk estimates. I view the most important points as:
1. Distrust of reasoning chains using fuzzy concepts
2. Distrust of selection effects at the level of arguments
3. Distrust of community dynamics
It’s not clear to me whether I have bound myself into a situation in which I can’t update from other people’s object-level arguments. I might well have, and it would lead to me playing in a perhaps-unnecessary hard mode.
If so, I could still update from e.g.:
* Trying to make predictions, and seeing which generators are more predictive of AI progress
* Investigations that I do myself, that lead me to acquire independent impressions, like playing with state-of-the-art models
* Deferring to people that I trust independently, e.g., Gwern
Lastly, I would loathe it if the same selection effects applied to this document: If I spent a few days putting this document together, it seems easy for the AI safety community to easily put a few cumulative weeks into arguing against this document, just by virtue of being a community.
This is all.
Acknowledgements
================
I am grateful to the [Samotsvety](https://samotsvety.org/) forecasters that have discussed this topic with me, and to Ozzie Gooen for comments and review. The above post doesn't necessarily represent the views of other people at the [Quantified Uncertainty Research Institute](https://quantifieduncertainty.org/), which nonetheless supports my research.
|
b12b85b5-3435-401d-a712-249064fc2b8e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Exploiting the Typical Mind Fallacy for more accurate questioning?
I was reading Yvain's Generalizing from One Example, which talks about the typical mind fallacy. Basically, it describes how humans assume that all other humans are like them. If a person doesn't cheat on tests, they are more likely to assume others won't cheat on tests either. If a person sees mental images, they'll be more likely to assume that everyone else sees mental images.
As I'm wont to do, I was thinking about how to make that theory pay rent. It occurred to me that this could definitely be exploitable. If the typical mind fallacy is correct, we should be able to have it go the other way; we can derive information about a person's proclivities based on what they think about other people.
Eg, most employers ask "have you ever stolen from a job before," and have to deal with misreporting because nobody in their right mind will say yes. However, imagine if the typical mind fallacy was correct. The employers could instead ask "what do you think the percentage of employees who have stolen from their job is?" and know that the applicants who responded higher than average were correspondingly more likely to steal, and the applicants who responded lower than average were less likely to cheat. It could cut through all sorts of social desirability distortion effects. You couldn't get the exact likelihood, but it would give more useful information than you would get with a direct question.
In hindsight, which is always 20/20, it seems incredibly obvious. I'd be surprised if professional personality tests and sociologists aren't using these types of questions. My google-fu shows no hits, but it's possible I'm just not using the correct term that sociologists use. I'm was wondering if anyone had heard of this questioning method before, and if there's any good research data out there showing just how much you can infer from someone's deviance from the median response.
|
75f5142a-8842-495f-b840-f1495efc68e0
|
trentmkelly/LessWrong-43k
|
LessWrong
|
In Defense of a Butlerian Jihad
[Epistemic Status: internally strongly convinced that it is centrally correct, but only from armchair reasoning, with only weak links to actual going-out-in-the-territory, so beware: outside view tells it is mostly wrong]
I have been binge-watching the excellent Dwarkesh Patel during my last vacations. There is, however, one big problem in his AI-related podcasts, a consistent missing mood in each of his interviewees (excepting Paul Christiano) and probably in himself.
"Yeah, AI is coming, exciting times ahead", say every single one, with a bright smile on their face.
The central message of this post is: the times ahead are as exciting as the perspective of jumping out of a plane without a parachute. Or how "exciting times" was the Great Leap Forward. Sure, you will probably have some kind of adrenaline rush at some point. But exciting should not be the first adjective that comes to mind. The first should be terrifying.
In the rest of this post, I will make the assumption that technical alignment is solved. Schematically, we get Claude 5 in our hands, who is as honest, helpful and harmless as 3.5 is (who, credit when credit is due, is good at that), except super-human in every cognitive task. Also we’ll assume that we have managed to avoid proliferation: initially, only Anthropic has this technology on hands, and this is expected to last for an eternity (something like months, maybe even a couple of years). Now we just have to decide what to do with it.
This is, pretty much, the best case scenario we can hope for. I’m claiming that we are not ready even for that best case scenario, we are not close to being ready for it, and even in this best case scenario we are cooked — like that dog who caught the car, only the car is an hungry monster.
By default, humanity is going to be defeated in details
Some people argue about AI Taking Our Jobs, and That’s Terrible. Zvi disagrees. I disagree with Zvi.
He knows that Comparative Advantages won’t save us. I’m pretty su
|
af85d921-77e4-4a95-8fd7-ff69dbeead61
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Hard-Coding Neural Computation
Previously: Teaser: Hard-coding Transformer Models
Introduction
Transformer models are incredibly powerful for natural language tasks (and they are starting to find uses in many other fields of machine learning). Unfortunately, it is nigh-impossible to interpret what goes on inside them. OR IS IT???
I have found that I can, with a fair amount of effort, hard-code the weights of a transformer model in order to perform some very crude versions of linguistic tasks. So far I have achieved English-to-French translation (on a toy corpus of about 150 sentences), text classification (is a sentence grammatical or not? on a toy corpus of a couple hundred sentences), and sentiment analysis (again on a limited corpus). These results are obviously not impressive compared to the state of the machine learning field, but I am pretty sure that they can all be drastically scaled up with the investment of some time and energy. Unfortunately, I have a fairly demanding day job, and haven't found the time and energy yet.
All of this is done by inspection (no gradient descent!). The process is a lot like programming, although it is more difficult than programming, at least right now for me. I am fairly certain that better tools and better notation can be developed to make the process easier. It is also almost certainly possible to combine hard-coding with gradient descent approaches to be able to scale these methods up in a slightly less labor-intensive way.
I think that these ideas could prove useful in alignment research - if we understand how a language model works in excruciating detail, it seems drastically more likely that we will be able to reason about and predict various misunderstandings rooted in the ambiguity of language. Given that language is (arguably) a fully general means of interacting with an artificial intelligence, it seems plausible to me that this work is on the critical path to alignment.
Doneness Status
This post is a work-in-progress. I will be editing it
|
68f9623e-e96f-4f2a-992c-f905a091a4bb
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
Turing's Red Flag
|
63cdc040-5208-455d-b527-f37cc220cd0c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Permission for mind uploading via online files
Giulio Prisco made a blog post giving permission to use the data in his Gmail account to reconstruct an uploaded copy of him.
> To whom it may concern:
>
> I am writing this in 2010. My Gmail account has more than 5GB of data, which contain some information about me and also some information about the persons I have exchanged email with, including some personal and private information.
>
> I am assuming that in 2060 (50 years from now), my Gmail account will have hundreds or thousands of TB of data, which will contain a lot of information about me and the persons I exchanged email with, including a lot of personal and private information. I am also assuming that, in 2060:
>
> 1) The data in the accounts of all Gmail users since 2004 is available.
> 2) AI-based mindware technology able to reconstruct individual mindfiles by analyzing the information in their aggregate Gmail accounts and other available information, with sufficient accuracy for mind uploading via detailed personality reconstruction, is available.
> 3) The technology to crack Gmail passwords is available, but illegal without the consent of the account owners (or their heirs).
> 4) Many of today's Gmail users, including myself, are already dead and cannot give permission to use the data in their accounts.
>
> If all assumptions above are correct, I hereby give permission to Google and/or other parties to read all data in my Gmail account and use them together with other available information to reconstruct my mindfile with sufficient accuracy for mind uploading via detailed personality reconstruction, and express my wish that they do so.
>
> Signed by Giulio Prisco on September 28, 2010, and witnessed by readers.
>
> NOTE: The accuracy of the process outlined above increases with the number of persons who give their permission to do the same. You can give your permission in comments, Twitter or other public spaces.
Ben Goertzel copied the post and gave the same permission on his own blog. I made
|
baa2f372-66e0-4419-a4f1-d80a73fdef3e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Can ChatGPT count?
A few month back there was a question on lesswrong about what the least impressive thing is going to be that GPT4 can't do. At the time I thought maybe counting could be a good candidate, because I had noticed that this seems to be a problem for all big transformer models.
Dall-E and other image generation models can't reliably get cardinalities right beyond something like 3.
Luminous/Magma the multi-modal AlephAlpha language model that can take pictures as input, cannot count items on these pictures with any reliability.
All pure language models I had checked, weren't able to count the number of occurrences of a specific word in a sentence or a specific character in a string.
Counting very much feels like a basic ability, I think my daughter could reliably count ten items when she was 2, and I feel like there should be a way to prompt ChatGPT that demonstrates counting ability.
In my tests so far, even ChatGPT as the most advanced LM to date is unable to count specific words or characters. However, people seem to disagree ...
For a short while I thought the correct hack is to ask it to write a python function to do the counting and then output what it thinks the function would output. But now I suspect that ChatGPT executes functions behind the scenes. So it would get the answer correct the very first time after actually writing the function and revert to being wrong in subsequent answer to the question what the function would output for certain inputs. [I just now noticed that in the answer below, even the first proposed function output is incorrect, so maybe there is no code execution?]
Here is one of my tries:
I want you to count the number of occurrences of the character "X" in a string. To do that I propose a simple algorithm, just repeat the string and write the current count of "X"s behind each "X" like this: "XGJKXZUXGULXXG" --> "X1GJKX2ZUX3GULX4X5G" : the final count is 5. Now you do this for "GLXXXJHJHXJHKXJHKX"
Sure, here is the implementat
|
746f4947-c080-49cd-a040-6378199a1b7d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Suggestions for net positive LLM research
I am starting a PhD in computer science, focusing on agent foundations so far, which is great. I intend to continue devoting at least half my time to agent foundations.
However, for several reasons, it seems to be important for me to do some applied work, particularly with LLMs:
1. I believe I'm otherwise pretty well positioned to get an impactful job at Google DeepMind, but apparently some impressive machine learning engineering creds are necessary to get on even the safety team currently.
2. My PhD supervisor is pushing for me to work on LLMs, though he seems to be pretty flexible about the details.
3. As much fun as math is, I also value developing my practical skills (in fact, half the fun of learning things is becoming more powerful in the real world).
4. LLM experts seem likely to be in high demand right now, though I am not sure how long that will last.
Now, I've spent the last couple of years mostly studying AIXI and its foundations. I'm pretty comfortable with standard deep learning algorithms and libraries and I have some industry experience with machine learning engineering, but I am not an expert on NLP, LLMs, or prosiac alignment. Therefore, I am looking for suggestions from the community about LLM related research projects that would satisfy as many as possible of the following criteria:
1. Is not directly focused on improving frontier model capabilities (for ethical reasons; though my timelines seem to be longer than the average lesswronger, I'm not able to accept the risk that I am wrong).
2. Produces mundane utility. I find it much more fulfilling to work on things that I can see becoming useful to people, and I also want a measure of my success which is as concrete as possible.
3. Contributes to prosiac alignment. It would be particularly nice if the experimental/engineering work involved is likely to inform my ideas for mathematical alignment research.
4. Machine learning engineering/research creds.
Any suggestions are appreciated. I
|
0f52f09c-2469-4cf2-8a96-7bbf90d0e7b2
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why you ask the significance question why
Hello.
(I am already doing 75% better)
I used to think that keeping your identity small is laudable. The reasoning goes that if "me" and "you" are interchangable instead of being only applicable for "me" there is a wider scope of applicability. And there is an effect.
At some point the other reduced to a hollow propertyless "x" means that people can not apply it or do not find it meaningful.
Lurking works well for abstract objective patterns.
If you actually do things, you have stakeholders which might not to a sufficient degree fit one general mold. Irreducable diversity might be real and it might be important.
I find myself writing still in a fact-stating manner. Sure, if two people are correct their takes should mesh without regard which specific turns were taken. But two experiences of (a facet of) reality do not have this automeshing property.
Look, I had negative experiences, emoted about it and often passively waited if/when a non-harmful action about it was possible. But what I now find signficant is that the "non-harmful action" takes an objective form, the action in itself is non-harmful. But if you ask about the affected parties, it is not a tag you put on the action, it is a line you draw between the party and action.
I might be trying to prematurely abstract, but, the emotion is about being turned into something more "correct". That a answer that is too unintellible, wrong ideological leaning or using a forbidden communication method will just be left stranded cold alone. Keeping your mouth shut when you have poor or no answer.
A question of "how" in the meaning technology, can be packaged so its customer does not need to opine about its operation. This works in a static environment. But environments are not static. Placing an art piece in a new context is especially dynamic.
In order not to drift into hurt, the receiver (customer) needs to know why it works the way it works, in order to have a chance to take the significance of a new context i
|
59d7e8f6-dd8b-46bd-9f4f-83ec20d2b4d4
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration
I Introduction
---------------
The annual increment of computing power described by Moore’s law is pioneering unprecedented possibilities.
This remarkable progress has been accompanied by a collinearity with tremendous increases in chip design complexity. One example of this is the growth in PVT (process, voltage, temperature) corners.
Despite the majority of the SoC area is occupied by digital circuitry, analog circuits are still essential for the chips to be able to communicate with and sense the rest of the world.
However, the design effort of the analog counterpart is more onerous due to the heavy requirements of human expertise, and the absence of automation tools similar to digital circuit design.
One of the labor intensive task in analog design is transistor sizing. Currently, it is mostly done by labouring trial-and-error.
The designers begin by applying their knowledge about the characteristics of analog circuits and transistors to select a reasonable range of candidate solutions, next explore the space with grid search. Then, get feedback from SPICE circuit simulations.
Afterward, repeat the procedure until the specifications are met.
The main challenge of automating sizing is that it has a very large design space, which prior arts suffered from convergence problems and poor scalability [[1](#bib.bib1)].
In this paper, we propose a general learning-based search framework (Fig. [1](#S1.F1 "Figure 1 ‣ I Introduction ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")) to help increase R&D productivity during analog front-end sizing task (Fig. [2](#S4.F2 "Figure 2 ‣ IV-A Problem reformulation ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")).
Experiment results demonstrate that our agents can efficiently and effectively accomplish search in state-of-the-art designs with superior performance while achieving area enhancement over human.
The contributions of our work are severalfold on different levels.
* •
System level We propose a general framework for IC design space search. The standardized API allows fast migration provided well-formulated problems. The ultimate goal of the framework is to increase R&D productivity with minimal extra efforts required.
* •
Algorithm level The proposed model-based reinforcement learning (RL) approach directly mimic the dynamics of the SPICE simulation instead of estimating cumulative future reward in model-free learning. This enables a more adequate implementation for usages in the industry.
* •
Verification level Considerations on PVT conditions better suits practical needs. The negligence of PVT conditions on previous works make them far from industrial adaptation.
Designerspt1. Topology 2. Specification3. Size ranges 4. PVT conditionsSatisfactory sizing
ptMonte CarlosamplingS~i\scaleto𝒫2pt∈𝒟\scaletoTR2pt\scaletoN(𝒫)2ptsuperscriptsubscript~𝑆𝑖\scaleto𝒫2𝑝𝑡subscriptsuperscript𝒟\scaleto𝑁𝒫2𝑝𝑡\scaleto𝑇𝑅2𝑝𝑡\tilde{S}\_{i}^{\scaleto{\mathcal{P}}{2pt}}\in\mathcal{D}^{\scaleto{N(\mathcal{P})}{2pt}}\_{\scaleto{TR}{2pt}}over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT ∈ caligraphic\_D start\_POSTSUPERSCRIPT italic\_N ( caligraphic\_P ) 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 2 italic\_p italic\_t end\_POSTSUBSCRIPTptRL agentsSizesMeas.ptEnvironment(SPICE)argmaxai∈S~i\scaleto𝒫2ptV\scaletoalue3pt(y^i\scaleto𝒫2pt)subscriptargmaxsubscript𝑎𝑖subscriptsuperscript~𝑆\scaleto𝒫2𝑝𝑡𝑖subscript𝑉\scaleto𝑎𝑙𝑢𝑒3𝑝𝑡subscriptsuperscript^𝑦\scaleto𝒫2𝑝𝑡𝑖\mathop{\mathrm{argmax}}\_{a\_{i}\in\tilde{S}^{\scaleto{\mathcal{P}}{2pt}}\_{i}}V\_{\scaleto{alue}{3pt}}(\hat{y}^{\scaleto{\mathcal{P}}{2pt}}\_{i})roman\_argmax start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ∈ over~ start\_ARG italic\_S end\_ARG start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT italic\_V start\_POSTSUBSCRIPT italic\_a italic\_l italic\_u italic\_e 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( over^ start\_ARG italic\_y end\_ARG start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT )ptPVT explorationchoose condition pool𝒫𝒫\mathcal{P}caligraphic\_P ptGradient update∂ℒ\scaleto𝒫2pt(S\scaletopice3pt\scaleto𝒫2pt(ai),f\scaletoNN2pt(ai,θ\scaleto𝒫2pt))∂θ\scaleto𝒫2ptsuperscriptℒ\scaleto𝒫2𝑝𝑡subscriptsuperscript𝑆\scaleto𝒫2𝑝𝑡\scaleto𝑝𝑖𝑐𝑒3𝑝𝑡subscript𝑎𝑖subscript𝑓\scaleto𝑁𝑁2𝑝𝑡subscript𝑎𝑖superscript𝜃\scaleto𝒫2𝑝𝑡superscript𝜃\scaleto𝒫2𝑝𝑡\dfrac{\partial\mathcal{L}^{\scaleto{\mathcal{P}}{2pt}}(S^{\scaleto{\mathcal{P}}{2pt}}\_{\scaleto{pice}{3pt}}(a\_{i}),f\_{\scaleto{NN}{2pt}}(a\_{i},\theta^{\scaleto{\mathcal{P}}{2pt}}))}{\partial\theta^{\scaleto{\mathcal{P}}{2pt}}}divide start\_ARG ∂ caligraphic\_L start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT ( italic\_S start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) , italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 2 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_θ start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT ) ) end\_ARG start\_ARG ∂ italic\_θ start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT end\_ARGptTrust region methodcompute ratio ρ\scaleto𝒫2ptsuperscript𝜌\scaleto𝒫2𝑝𝑡\rho^{\scaleto{\mathcal{P}}{2pt}}italic\_ρ start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPTpt𝒫𝒫\mathcal{P}caligraphic\_PptMeas. estimatey^i\scaleto𝒫2ptsubscriptsuperscript^𝑦\scaleto𝒫2𝑝𝑡𝑖\hat{y}^{\scaleto{\mathcal{P}}{2pt}}\_{i}over^ start\_ARG italic\_y end\_ARG start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPTptCandidatesizes aisubscript𝑎𝑖a\_{i}italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPTS~i\scaleto𝒫2ptsubscriptsuperscript~𝑆\scaleto𝒫2𝑝𝑡𝑖\tilde{S}^{\scaleto{\mathcal{P}}{2pt}}\_{i}over~ start\_ARG italic\_S end\_ARG start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPTf\scaletoNN2pt(ai,θ\scaleto𝒫2pt)subscript𝑓\scaleto𝑁𝑁2𝑝𝑡subscript𝑎𝑖superscript𝜃\scaleto𝒫2𝑝𝑡f\_{\scaleto{NN}{2pt}}(a\_{i},\theta^{\scaleto{\mathcal{P}}{2pt}})italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 2 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_θ start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT )S\scaletopice3pt\scaleto𝒫2pt(ai),𝒫subscriptsuperscript𝑆\scaleto𝒫2𝑝𝑡\scaleto𝑝𝑖𝑐𝑒3𝑝𝑡subscript𝑎𝑖𝒫S^{\scaleto{\mathcal{P}}{2pt}}\_{\scaleto{pice}{3pt}}(a\_{i}),\mathcal{P}italic\_S start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) , caligraphic\_P∂ℒ\scaleto𝒫2pt∂θ\scaleto𝒫2ptsuperscriptℒ\scaleto𝒫2𝑝𝑡superscript𝜃\scaleto𝒫2𝑝𝑡\dfrac{\partial\mathcal{L}^{\scaleto{\mathcal{P}}{2pt}}}{\partial\theta^{\scaleto{\mathcal{P}}{2pt}}}divide start\_ARG ∂ caligraphic\_L start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT end\_ARG start\_ARG ∂ italic\_θ start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT end\_ARGtrial point acceptance xisubscript𝑥𝑖x\_{i}italic\_x start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPTupdate radius Δri+1\scaleto𝒫2ptΔsubscriptsuperscript𝑟\scaleto𝒫2𝑝𝑡𝑖1\Delta r^{\scaleto{\mathcal{P}}{2pt}}\_{i+1}roman\_Δ italic\_r start\_POSTSUPERSCRIPT caligraphic\_P 2 italic\_p italic\_t end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i + 1 end\_POSTSUBSCRIPT
Figure 1: Framework architecture
II Prior arts
--------------
Sizing automation could be framed as an optimization problem.
Bayesian optimization (BO) is a popular choice because of the sample efficiency in finding the global optimum [[2](#bib.bib2)][[3](#bib.bib3)].
Despite of the promising results, the scalability is a major drawback.
Note that the scalability addressed is the cubical increment of the number of samples, rather than the dimensionality of the space.
Recently introduced methods primarily leverage the current success in deep learning.
Model-based RL trained with well-developed supervised learning methods,
were established as not suitable for IC design space search due to the difficulty in providing sufficient data samples for training [[1](#bib.bib1)][[4](#bib.bib4)].
Some models demand re-training when a new set of specifications is assigned, hence, cannot be reused [[5](#bib.bib5)].
In later publications, model-free RL comes prominence.
AutoCkt [[6](#bib.bib6)] aims to train an efficient agent to explore and gain knowledge about the design space. The agents will then be used to generate trajectories during inference.
Yet, it is rarely necessary to traverse the space in the industry.
L2DC [[7](#bib.bib7)] exploits sophisticated sequence-to-sequence modeling using an encoder-decoder technique.
GCN-RL [[8](#bib.bib8)] employs the latest innovation - graph convolutional neural networks - to learn features from the structures. This enables the model to reach better transferability between nodes and topologies.
In spite of their ability to exceed human-level performance, the amount of human-engineering efforts in observation selection, network architecture design, and reward engineering reduce the feasibility of becoming a generalizable automation tool.
III Problem formulation
------------------------
Transistor sizing (Fig. [2](#S4.F2 "Figure 2 ‣ IV-A Problem reformulation ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")) is an iterative process to determine a suitable set of lengths, widths, and multiplicities for each transistor in the topology in order to achieve the desired specifications.
This scheme is often regarded as a trade-off between constraints. Larger transistor sizes normally lead to greater performance, but consume more power and area.
Analog circuit sizing can be formulated as a constrained multi-objective optimization problem, defined in ([1](#S3.E1 "1 ‣ III Problem formulation ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")).
| | | | | |
| --- | --- | --- | --- | --- |
| | Minimize | Fm,c(X)m=1,2,…Nmc=1,2,…Ncsubscript𝐹𝑚𝑐𝑋𝑚12…subscript𝑁𝑚𝑐12…subscript𝑁𝑐\displaystyle F\_{m,c}(X)\qquad\begin{array}[]{c}m=1,2,...N\_{m}\\
c=1,2,...N\_{c}\\
\end{array}italic\_F start\_POSTSUBSCRIPT italic\_m , italic\_c end\_POSTSUBSCRIPT ( italic\_X ) start\_ARRAY start\_ROW start\_CELL italic\_m = 1 , 2 , … italic\_N start\_POSTSUBSCRIPT italic\_m end\_POSTSUBSCRIPT end\_CELL end\_ROW start\_ROW start\_CELL italic\_c = 1 , 2 , … italic\_N start\_POSTSUBSCRIPT italic\_c end\_POSTSUBSCRIPT end\_CELL end\_ROW end\_ARRAY | | (1) |
| | subject to | Cd,c(X)<0d=1,2,…Ndc=1,2,…Ncsubscript𝐶𝑑𝑐𝑋0𝑑12…subscript𝑁𝑑𝑐12…subscript𝑁𝑐\displaystyle C\_{d,c}(X)<0\qquad\begin{array}[]{c}d=1,2,...N\_{d}\\
c=1,2,...N\_{c}\\
\end{array}italic\_C start\_POSTSUBSCRIPT italic\_d , italic\_c end\_POSTSUBSCRIPT ( italic\_X ) < 0 start\_ARRAY start\_ROW start\_CELL italic\_d = 1 , 2 , … italic\_N start\_POSTSUBSCRIPT italic\_d end\_POSTSUBSCRIPT end\_CELL end\_ROW start\_ROW start\_CELL italic\_c = 1 , 2 , … italic\_N start\_POSTSUBSCRIPT italic\_c end\_POSTSUBSCRIPT end\_CELL end\_ROW end\_ARRAY | |
| | | X∈𝒟s𝑋subscript𝒟𝑠\displaystyle X\in\mathcal{D}\_{s}italic\_X ∈ caligraphic\_D start\_POSTSUBSCRIPT italic\_s end\_POSTSUBSCRIPT | |
where X𝑋Xitalic\_X is a vector of variables to be optimized; 𝒟ssubscript𝒟𝑠\mathcal{D}\_{s}caligraphic\_D start\_POSTSUBSCRIPT italic\_s end\_POSTSUBSCRIPT is the design space; Fc,m(X)subscript𝐹𝑐𝑚𝑋F\_{c,m}(X)italic\_F start\_POSTSUBSCRIPT italic\_c , italic\_m end\_POSTSUBSCRIPT ( italic\_X ) is the mthsuperscript𝑚𝑡ℎm^{th}italic\_m start\_POSTSUPERSCRIPT italic\_t italic\_h end\_POSTSUPERSCRIPT objective function under the cthsuperscript𝑐𝑡ℎc^{th}italic\_c start\_POSTSUPERSCRIPT italic\_t italic\_h end\_POSTSUPERSCRIPT PVT condition;
C(X)d,c𝐶subscript𝑋𝑑𝑐C(X)\_{d,c}italic\_C ( italic\_X ) start\_POSTSUBSCRIPT italic\_d , italic\_c end\_POSTSUBSCRIPT is the dthsuperscript𝑑𝑡ℎd^{th}italic\_d start\_POSTSUPERSCRIPT italic\_t italic\_h end\_POSTSUPERSCRIPT constraint under the cthsuperscript𝑐𝑡ℎc^{th}italic\_c start\_POSTSUPERSCRIPT italic\_t italic\_h end\_POSTSUPERSCRIPT PVT condition.
IV Proposed framework
----------------------
The proposed framework is shown in Fig. [1](#S1.F1 "Figure 1 ‣ I Introduction ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration").
Deep RL is believed to be a robust methodology for solving combinatorial search problem in various disciplines without human in the loop, such as games [[9](#bib.bib9)][[10](#bib.bib10)][[11](#bib.bib11)], robotic control [[12](#bib.bib12)][[13](#bib.bib13)], neural architecture search [[14](#bib.bib14)][[15](#bib.bib15)], and IC design [[16](#bib.bib16)][[17](#bib.bib17)].
We thus cast the transistor sizing task as a DRL framework. This allows us to automate the process, while being able to adapt to the environment fast based on past experiences, and evolve over time.
This system consists of several subsystems described in the following sections.
###
IV-A Problem reformulation
Transistor sizing (Fig. [2](#S4.F2 "Figure 2 ‣ IV-A Problem reformulation ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")) has long been formulated as an optimization problem, in which agents and optimizers are implemented to search for optimal points in objective functions.
However, it is worth a rethink of what is an adequate implementation to integrate with the flow of a designer.
SpecptTopologySelectionptCircuitSizingptVerify(SPICE)ptLayout
Figure 2: Analog circuit pre-layout design flow
With the exponential growth in PVT corners during fast technological advances, finding the global optimum is often infeasible. In contrast, meeting the constraints assigned by designers is more practical.
In this manner, the problem can be reduced to a constraint satisfaction problem (CSP), where the objective function in ([1](#S3.E1 "1 ‣ III Problem formulation ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")) is replaced as a 0 constant function.
More generally, CSP is defined as a triple ⟨X,𝒟,𝒞⟩𝑋𝒟𝒞\langle X,\mathcal{D},\mathcal{C}\rangle⟨ italic\_X , caligraphic\_D , caligraphic\_C ⟩ ([2](#S4.E2 "2 ‣ IV-A Problem reformulation ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")).
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| | X𝑋\displaystyle Xitalic\_X | =\displaystyle== | {{\displaystyle\{{ | x1,x2,…,xn}\displaystyle x\_{1},x\_{2},...,x\_{n}\}italic\_x start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_x start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , … , italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } | | (2) |
| | 𝒟𝒟\displaystyle\mathcal{D}caligraphic\_D | =\displaystyle== | {{\displaystyle\{{ | D1,D2,…,Dn},\displaystyle D\_{1},D\_{2},...,D\_{n}\},italic\_D start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_D start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , … , italic\_D start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } , | Disubscript𝐷𝑖\displaystyle D\_{i}italic\_D start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT | =\displaystyle== | {{\displaystyle\{{ | b1,b2,…,bl}\displaystyle b\_{1},b\_{2},...,b\_{l}\}italic\_b start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_b start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , … , italic\_b start\_POSTSUBSCRIPT italic\_l end\_POSTSUBSCRIPT } | |
| | 𝒞𝒞\displaystyle\mathcal{C}caligraphic\_C | =\displaystyle== | {{\displaystyle\{{ | C1,C2,…,Ck},\displaystyle C\_{1},C\_{2},...,C\_{k}\},italic\_C start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_C start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , … , italic\_C start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT } , | Cjsubscript𝐶𝑗\displaystyle C\_{j}italic\_C start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT | =\displaystyle== | ((\displaystyle(( | tj,rj)\displaystyle t\_{j},r\_{j})italic\_t start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT , italic\_r start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT ) | |
where X𝑋Xitalic\_X is a finite set of sizing variables to be searched, each has a non-empty domain Disubscript𝐷𝑖D\_{i}italic\_D start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, namely the design space, and bksubscript𝑏𝑘b\_{k}italic\_b start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT is the possible value.
𝒞𝒞\mathcal{C}caligraphic\_C is a set of constraints. A constraint is a pair consists of a constraint scope tjsubscript𝑡𝑗t\_{j}italic\_t start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT and a relation rjsubscript𝑟𝑗r\_{j}italic\_r start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT over the variables in the scope, limiting feasible permutations of assignments.
In our case, the relation cannot be explicitly expressed since it is the complex computation inside of the SPICE simulation, denoted as Spicesubscript𝑆𝑝𝑖𝑐𝑒S\_{pice}italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT function.
With this, the intention is to find any complete assignment that is consistent.
This also prevents over designing the circuit.
Therefore, an algorithm targeting on fast exploring feasible solutions instead of a global one could make more merit.
An akin method is meta-learning [[18](#bib.bib18)]. The model attempts to adapt to new tasks quickly, rather than focusing on a specific environment.
###
IV-B Agents
Based on the observation and belief that there are multiple satisfactory solutions in different local optima, one effective algorithm for solving such CSP is local search [[19](#bib.bib19)].
This introduces appealing three-fold advantages:
1) Faster environment adaptation: by reducing the domain to a local region allows fewer iterations for constructing the space. In addition, the circuit space is locally continuous, i.e., neighboring points around a known optimum show similar optimality.
2) Model-based agents with supervised learning: related works criticized supervised learning as per the metric of global goodness of fit. However, it still works given that the local landscape can be captured. Moreover, no reward is involved in the training of model-based agents, making it insensitive to reward engineering.
3) Easier implementation and convergence: model-free agents behave based on a surrogate network modeling the relationship between past trajectories and the next actions to take. Nonetheless, this custom model tends to complicate the problem which makes it hard to converge. Whereas the training routine of supervised learning is relatively trivial.
All virtues combined actuates a model-based approach, where a direct modeling of the compact circuit space 𝒟Lsubscript𝒟𝐿\mathcal{D}\_{L}caligraphic\_D start\_POSTSUBSCRIPT italic\_L end\_POSTSUBSCRIPT from transistor sizes X𝑋Xitalic\_X to circuit measurements Spice(X)subscript𝑆𝑝𝑖𝑐𝑒𝑋S\_{pice}(X)italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT ( italic\_X ) is mapped, imitating the behavior of a SPICE simulator.
A simple feed-forward neural network f\scaletoNN3pt(X;θ)subscript𝑓\scaleto𝑁𝑁3𝑝𝑡𝑋𝜃f\_{\scaleto{NN}{3pt}}(X;\theta)italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_X ; italic\_θ ) with 3 layers can be used as a SPICE function approximator ([3](#S4.E3 "3 ‣ IV-B Agents ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")).
| | | | |
| --- | --- | --- | --- |
| | y^=f\scaletoNN3pt(X;θ)≈Spice(X),X∈𝒟Lformulae-sequence^𝑦subscript𝑓\scaleto𝑁𝑁3𝑝𝑡𝑋𝜃subscript𝑆𝑝𝑖𝑐𝑒𝑋𝑋subscript𝒟𝐿\displaystyle\hat{y}=f\_{\scaleto{NN}{3pt}}(X;\theta)\approx S\_{pice}(X),X\in\mathcal{D}\_{L}over^ start\_ARG italic\_y end\_ARG = italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_X ; italic\_θ ) ≈ italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT ( italic\_X ) , italic\_X ∈ caligraphic\_D start\_POSTSUBSCRIPT italic\_L end\_POSTSUBSCRIPT | | (3) |
where y^^𝑦\hat{y}over^ start\_ARG italic\_y end\_ARG is a vector of predicted measurements (e.g., gain, phase margin, etc) w.r.t. a vector of sizes X𝑋Xitalic\_X estimated with weights θ𝜃\thetaitalic\_θ.
The loss function J(θ)𝐽𝜃J(\theta)italic\_J ( italic\_θ ) is simply obtained by the mean squared error (MSE) ([4](#S4.E4 "4 ‣ IV-B Agents ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")).
| | | | |
| --- | --- | --- | --- |
| | J(θ)=1m∑i=1m(Spice(X(i))−f\scaletoNN3pt(X(i);θ))2𝐽𝜃1𝑚subscriptsuperscript𝑚𝑖1superscriptsubscript𝑆𝑝𝑖𝑐𝑒superscript𝑋𝑖subscript𝑓\scaleto𝑁𝑁3𝑝𝑡superscript𝑋𝑖𝜃2\displaystyle J(\theta)=\dfrac{1}{m}\sum^{m}\_{i=1}(S\_{pice}(X^{(i)})-f\_{\scaleto{NN}{3pt}}(X^{(i)};\theta))^{2}italic\_J ( italic\_θ ) = divide start\_ARG 1 end\_ARG start\_ARG italic\_m end\_ARG ∑ start\_POSTSUPERSCRIPT italic\_m end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i = 1 end\_POSTSUBSCRIPT ( italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT ( italic\_X start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT ) - italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_X start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT ; italic\_θ ) ) start\_POSTSUPERSCRIPT 2 end\_POSTSUPERSCRIPT | | (4) |
Model-based agent is an obscured choice in recent RL solutions. It aims to learn a predictive model f\scaletoNN3ptsubscript𝑓\scaleto𝑁𝑁3𝑝𝑡f\_{\scaleto{NN}{3pt}}italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT to mimic the dynamics of the environment Spicesubscript𝑆𝑝𝑖𝑐𝑒S\_{pice}italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT, then plan on the model. From this, the number of iterations can be thus reduced.
A recent novel publication [[11](#bib.bib11)] use such agents in Atari game play.
They claimed that humans can learn fast thanks to the intuitive understanding of the physical processes, and we can apply it to predict the future.
Therefore, agents who possess such skill could be more sample efficient.
Each search starts by a random exploration in the design space. Next, the most optimal point will be selected as the local area 𝒟Lsubscript𝒟𝐿\mathcal{D}\_{L}caligraphic\_D start\_POSTSUBSCRIPT italic\_L end\_POSTSUBSCRIPT to dive in.
The policy is that by modeling the local landscape, a candidate solution can be chosen in the local domain as the next step based on the expected value (discussed in [IV-D](#S4.SS4 "IV-D Reward (value) engineering ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")) computed with predicted measurements y^^𝑦\hat{y}over^ start\_ARG italic\_y end\_ARG.
The properties of the local area is granted by the trust region method (TRM), explained in [IV-C](#S4.SS3 "IV-C Trust region method ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration").
Even though an optimization or another policy network can be incorporated to find the candidate with the maximum value, to take the advantage of the fast inference time of a neural network, a more vanilla Monte Carlo sampling-based planning is used. The pseudocode of the realization is detailed in Algorithm [1](#alg1 "Algorithm 1 ‣ IV-B Agents ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration").
Algorithm 1 Fast local explorer algorithm
1:initialize trajectory←[]←𝑡𝑟𝑎𝑗𝑒𝑐𝑡𝑜𝑟𝑦trajectory\leftarrow[\,]italic\_t italic\_r italic\_a italic\_j italic\_e italic\_c italic\_t italic\_o italic\_r italic\_y ← [ ]
2:initialize S~0←(X0,…,XN)←subscript~𝑆0superscript𝑋0…superscript𝑋𝑁\tilde{S}\_{0}\leftarrow(X^{0},...,X^{N})over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ← ( italic\_X start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT , … , italic\_X start\_POSTSUPERSCRIPT italic\_N end\_POSTSUPERSCRIPT ), N𝑁Nitalic\_N samples of X∈𝒟𝑋𝒟X\in\mathcal{D}italic\_X ∈ caligraphic\_D
3:evaluate value V0subscript𝑉0V\_{0}italic\_V start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT of Spice(S~0)subscript𝑆𝑝𝑖𝑐𝑒subscript~𝑆0S\_{pice}(\tilde{S}\_{0})italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT ( over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) via the Valuesubscript𝑉𝑎𝑙𝑢𝑒V\_{alue}italic\_V start\_POSTSUBSCRIPT italic\_a italic\_l italic\_u italic\_e end\_POSTSUBSCRIPT function
4:find the best a0←argmaxS~0∈𝒟NV0←subscript𝑎0subscriptargmaxsubscript~𝑆0superscript𝒟𝑁subscript𝑉0a\_{0}\leftarrow\mathop{\mathrm{argmax}}\_{\tilde{S}\_{0}\in\mathcal{D}^{N}}V\_{0}italic\_a start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ← roman\_argmax start\_POSTSUBSCRIPT over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ∈ caligraphic\_D start\_POSTSUPERSCRIPT italic\_N end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT italic\_V start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT region to search from
5:initialize i←0←𝑖0i\leftarrow 0italic\_i ← 0, 𝒟\scaletoTR3pt1subscriptsuperscript𝒟1\scaleto𝑇𝑅3𝑝𝑡\mathcal{D}^{1}\_{\scaleto{TR}{3pt}}caligraphic\_D start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 3 italic\_p italic\_t end\_POSTSUBSCRIPT & θ𝜃\thetaitalic\_θ for f\scaletoNN3ptsubscript𝑓\scaleto𝑁𝑁3𝑝𝑡f\_{\scaleto{NN}{3pt}}italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT
6:while not done do
7: trajectory.append((ai,Spice(ai)))formulae-sequence𝑡𝑟𝑎𝑗𝑒𝑐𝑡𝑜𝑟𝑦𝑎𝑝𝑝𝑒𝑛𝑑subscript𝑎𝑖subscript𝑆𝑝𝑖𝑐𝑒subscript𝑎𝑖trajectory.append((a\_{i},S\_{pice}(a\_{i})))italic\_t italic\_r italic\_a italic\_j italic\_e italic\_c italic\_t italic\_o italic\_r italic\_y . italic\_a italic\_p italic\_p italic\_e italic\_n italic\_d ( ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) ) ) for training
8: θ←θ−α∂J(θ)∂θ←𝜃𝜃𝛼partial-derivative𝜃𝐽𝜃\theta\leftarrow\theta-\alpha\partialderivative{J(\theta)}{\theta}italic\_θ ← italic\_θ - italic\_α divide start\_ARG ∂ start\_ARG italic\_J ( italic\_θ ) end\_ARG end\_ARG start\_ARG ∂ start\_ARG italic\_θ end\_ARG end\_ARG
9: i←i+1←𝑖𝑖1i\leftarrow i+1italic\_i ← italic\_i + 1
10: sample mX𝑚𝑋mXitalic\_m italic\_Xs S~i∈𝒟\scaletoTR3ptm(i)subscript~𝑆𝑖subscriptsuperscript𝒟𝑚𝑖\scaleto𝑇𝑅3𝑝𝑡\tilde{S}\_{i}\in\mathcal{D}^{m(i)}\_{\scaleto{TR}{3pt}}over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ∈ caligraphic\_D start\_POSTSUPERSCRIPT italic\_m ( italic\_i ) end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 3 italic\_p italic\_t end\_POSTSUBSCRIPT, approximate Spicesubscript𝑆𝑝𝑖𝑐𝑒S\_{pice}italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT via f\scaletoNN3pt(S~i;θ)subscript𝑓\scaleto𝑁𝑁3𝑝𝑡subscript~𝑆𝑖𝜃f\_{\scaleto{NN}{3pt}}(\tilde{S}\_{i};\theta)italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ; italic\_θ )
11: select next a^i←argmaxX∈S~iValue∘f\scaletoNN3pt(S~i;θ)←subscript^𝑎𝑖subscriptargmax𝑋subscript~𝑆𝑖subscript𝑉𝑎𝑙𝑢𝑒subscript𝑓\scaleto𝑁𝑁3𝑝𝑡subscript~𝑆𝑖𝜃\hat{a}\_{i}\leftarrow\mathop{\mathrm{argmax}}\_{X\in\tilde{S}\_{i}}V\_{alue}\circ f\_{\scaleto{NN}{3pt}}(\tilde{S}\_{i};\theta)over^ start\_ARG italic\_a end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ← roman\_argmax start\_POSTSUBSCRIPT italic\_X ∈ over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT italic\_V start\_POSTSUBSCRIPT italic\_a italic\_l italic\_u italic\_e end\_POSTSUBSCRIPT ∘ italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( over~ start\_ARG italic\_S end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ; italic\_θ )
12: ai,𝒟\scaletoTR3pti+1←TRM(a^i,Spice(a^i),𝒟\scaletoTR3pti)←subscript𝑎𝑖subscriptsuperscript𝒟𝑖1\scaleto𝑇𝑅3𝑝𝑡
𝑇𝑅𝑀subscript^𝑎𝑖subscript𝑆𝑝𝑖𝑐𝑒subscript^𝑎𝑖subscriptsuperscript𝒟𝑖\scaleto𝑇𝑅3𝑝𝑡a\_{i},\mathcal{D}^{i+1}\_{\scaleto{TR}{3pt}}\leftarrow TRM(\hat{a}\_{i},S\_{pice}(\hat{a}\_{i}),\mathcal{D}^{i}\_{\scaleto{TR}{3pt}})italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , caligraphic\_D start\_POSTSUPERSCRIPT italic\_i + 1 end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 3 italic\_p italic\_t end\_POSTSUBSCRIPT ← italic\_T italic\_R italic\_M ( over^ start\_ARG italic\_a end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT ( over^ start\_ARG italic\_a end\_ARG start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) , caligraphic\_D start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 3 italic\_p italic\_t end\_POSTSUBSCRIPT )
13: if ai∈𝒞subscript𝑎𝑖𝒞a\_{i}\in\mathcal{C}italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ∈ caligraphic\_C then
14: return(ai,Spice(ai))𝑟𝑒𝑡𝑢𝑟𝑛subscript𝑎𝑖subscript𝑆𝑝𝑖𝑐𝑒subscript𝑎𝑖return\>(a\_{i},S\_{pice}(a\_{i}))italic\_r italic\_e italic\_t italic\_u italic\_r italic\_n ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) )
15: else if i>Criterion𝑖subscript𝐶𝑟𝑖𝑡𝑒𝑟𝑖𝑜𝑛i>C\_{riterion}italic\_i > italic\_C start\_POSTSUBSCRIPT italic\_r italic\_i italic\_t italic\_e italic\_r italic\_i italic\_o italic\_n end\_POSTSUBSCRIPT then
16: escape, jump to line 2222
17: end if
18:end while
###
IV-C Trust region method
The transition of search space size from a global landscape to a local area is the key factor to the performance of our agents. Thus, the definition of the local properties plays a role in the algorithm efficiency.
If the compact domain is statically fixed throughout the search, the neural network model could have bad extrapolation properties at the beginning of the episode, when only few samples exist.
Trust region method defines an iteration-dependent trust region radius ΔriΔsubscript𝑟𝑖\Delta r\_{i}roman\_Δ italic\_r start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT where we trust the model Value∘f\scaletoNN3ptsubscript𝑉𝑎𝑙𝑢𝑒subscript𝑓\scaleto𝑁𝑁3𝑝𝑡V\_{alue}\circ f\_{\scaleto{NN}{3pt}}italic\_V start\_POSTSUBSCRIPT italic\_a italic\_l italic\_u italic\_e end\_POSTSUBSCRIPT ∘ italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT to be an adequate representation of the objective function Value∘Spicesubscript𝑉𝑎𝑙𝑢𝑒subscript𝑆𝑝𝑖𝑐𝑒V\_{alue}\circ S\_{pice}italic\_V start\_POSTSUBSCRIPT italic\_a italic\_l italic\_u italic\_e end\_POSTSUBSCRIPT ∘ italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT.
At each iteration i𝑖iitalic\_i, a trust region algorithm first solves the trust region subproblem ([5](#S4.E5 "5 ‣ IV-C Trust region method ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")) to obtain d⋆(i)superscript𝑑⋆absent𝑖d^{\star(i)}italic\_d start\_POSTSUPERSCRIPT ⋆ ( italic\_i ) end\_POSTSUPERSCRIPT.
In our case, this is realized by Monte Carlo sampling as mentioned in [IV-B](#S4.SS2 "IV-B Agents ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration").
| | | | |
| --- | --- | --- | --- |
| | d⋆(i)=argmaxXi+di∈𝒟\scaletoTR3ptiValue∘f\scaletoNN3pt(Xi+di),superscript𝑑⋆absent𝑖subscriptargmaxsuperscript𝑋𝑖superscript𝑑𝑖subscriptsuperscript𝒟𝑖\scaleto𝑇𝑅3𝑝𝑡subscript𝑉𝑎𝑙𝑢𝑒subscript𝑓\scaleto𝑁𝑁3𝑝𝑡superscript𝑋𝑖superscript𝑑𝑖\displaystyle d^{\star(i)}=\mathop{\mathrm{argmax}}\_{X^{i}+d^{i}\in\mathcal{D}^{i}\_{\scaleto{TR}{3pt}}}V\_{alue}\circ f\_{\scaleto{NN}{3pt}}(X^{i}+d^{i}),italic\_d start\_POSTSUPERSCRIPT ⋆ ( italic\_i ) end\_POSTSUPERSCRIPT = roman\_argmax start\_POSTSUBSCRIPT italic\_X start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT + italic\_d start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT ∈ caligraphic\_D start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 3 italic\_p italic\_t end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT italic\_V start\_POSTSUBSCRIPT italic\_a italic\_l italic\_u italic\_e end\_POSTSUBSCRIPT ∘ italic\_f start\_POSTSUBSCRIPT italic\_N italic\_N 3 italic\_p italic\_t end\_POSTSUBSCRIPT ( italic\_X start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT + italic\_d start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT ) , | | (5) |
| | 𝒟\scaletoTR3pti={X∈𝒟∣‖X−Xi‖≤Δri}subscriptsuperscript𝒟𝑖\scaleto𝑇𝑅3𝑝𝑡conditional-set𝑋𝒟norm𝑋superscript𝑋𝑖Δsubscript𝑟𝑖\displaystyle\mathcal{D}^{i}\_{\scaleto{TR}{3pt}}=\{X\in\mathcal{D}\mid\left\|X-X^{i}\right\|\leq\Delta r\_{i}\}caligraphic\_D start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 3 italic\_p italic\_t end\_POSTSUBSCRIPT = { italic\_X ∈ caligraphic\_D ∣ ∥ italic\_X - italic\_X start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT ∥ ≤ roman\_Δ italic\_r start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT } | |
where d⋆(i)superscript𝑑⋆absent𝑖d^{\star(i)}italic\_d start\_POSTSUPERSCRIPT ⋆ ( italic\_i ) end\_POSTSUPERSCRIPT is a vector of optimal trial steps, ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥ is a norm, 𝒟\scaletoTR3ptisubscriptsuperscript𝒟𝑖\scaleto𝑇𝑅3𝑝𝑡\mathcal{D}^{i}\_{\scaleto{TR}{3pt}}caligraphic\_D start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_T italic\_R 3 italic\_p italic\_t end\_POSTSUBSCRIPT is the trust region.
Then, compute the ratio ρisuperscript𝜌𝑖\rho^{i}italic\_ρ start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT of the estimated reduction and the actual reduction. A criterion is set to accept the trial step, i.e. if the ratio is not significant, then the trial point will be rejected.
Finally, the radius is updated based on the ρisuperscript𝜌𝑖\rho^{i}italic\_ρ start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT. If the neural network closely approximate the objective function Value∘Spicesubscript𝑉𝑎𝑙𝑢𝑒subscript𝑆𝑝𝑖𝑐𝑒V\_{alue}\circ S\_{pice}italic\_V start\_POSTSUBSCRIPT italic\_a italic\_l italic\_u italic\_e end\_POSTSUBSCRIPT ∘ italic\_S start\_POSTSUBSCRIPT italic\_p italic\_i italic\_c italic\_e end\_POSTSUBSCRIPT, then the trust region will be expanded, shrank otherwise.
###
IV-D Reward (value) engineering
For our agents, there is a value function to estimate the merit of a set of circuit measurements after SPICE simulation.
This is served as an indication of where to go next.
Unlike model-free actor-critic methods, values do not participate in training. Consequently, the design of the formula does not affect the convergence of the model.
In the spirit of simplicity and generalization, we utilize a naive tactic where the value is the sum of normalized measurements. This way, no extra information is acquired.
However, in terms of the trade-off between constraints, a second-stage value function could be implemented to explicitly encode the importance of each measurement once the agent enters a optimal local area.
###
IV-E PVT exploration strategy
In order to push the system to production, one important aspect to consider is the PVT conditions.
To guarantee that a chip is able to work under the variations of fabrications, power supplies, and environments, a number of corners have to be signed off before tape-out.
Nonetheless, to best of our knowledge, no prior art has accommodated such regime.
A simple way to explore the conditions would be to test all PVTs every time a new set of assignments is obtained.
Yet for deployment, this strategy would pose a waste in computing resources and EDA (electronic design automation) tool licenses if the agent is not yet ready for verification.
Inspired by heuristics of designers, first focus the search on a single condition, usually the most difficult condition to search, assuming that by overcoming the hardest PVT, easier ones would be easy.
Once all the specifications are met, verifications will be conducted to confirm that the set of assignments are legal under all other conditions as well.
Accordingly, the proposed progressive strategy is that if the initial condition does not apply, the corner with the least value will be chosen to be searched next, until all constraints are satisfied under all conditions (Fig. [3](#S4.F3 "Figure 3 ‣ IV-E PVT exploration strategy ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")).
If multiple corners are under search, the candidate solution will be taken as the complete assignments with the lowest expected value.
Note that each PVT condition has its own independent model.
In Algorithm. [1](#alg1 "Algorithm 1 ‣ IV-B Agents ‣ IV Proposed framework ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration"), the search is demonstrated in an uniform condition. However, it is painless to generalize to our progressive strategy.
PVT 1PVT 2PVT 3PVT 4PVT 5PVT 6PVT 7PVT 8PVT 9ptTrainptTestallptTrainptTestallptTrainptTestallptHit specptHit specptWorst cond.
Figure 3: Progressive PVT exploration strategy(block: 1 EDA time; red: not meet spec; green: meet spec)
###
IV-F API
A framework with a powerful search algorithm could be wasteful if the user interface is unfriendly or requires extra effort to use.
In the introduced API, only information that the designers need in their original flow is acquired.
In particular, human experts will need to identify the transistor sizes to tune, the ranges of variables, the circuit topology, the measurements to observe from SPICE simulations, and the specifications for each corner.
Once the configuration is set, an automatic script will construct necessary components, namely the neural network architectures and hyperparameters of the network, which are also dynamically scheduled on the fly.
That is to say, our framework is equivalent to a SPICE decorator where the DRL agents are encapsulated, which seamlessly automates transistor sizing with generalization.
V Experiment results
---------------------
###
V-A Experimental setup
Our experiments are conducted on both academic and industrial settings to evaluate the feasibility and the capability of the DRL agents.
During the development phase, the agents are tested on a two-stage opamp with BSIM 45/22nm processes simulated on an open sourced NGSPICE simulator developed by UC Berkeley.
Two scenarios that are often encountered in practice, specifically, process porting and PVT exploration are analyzed.
To demonstrate that the proposed framework is beneficial in production, we cooperate with industrial professional designers and evaluate the agents on two industrial cases with the most advanced TSMC 5nm and 6nm technologies.
Simulations are conducted in Cadence Spectre.
###
V-B 45nm two-stage opamp
First, we benchmark our method with various baseline models including random search,
customized BO (designed, implemented, and tuned by ourselves),
Advantage Actor Critic (A2C) [[20](#bib.bib20)],
Proximal Policy Optimization (PPO) [[21](#bib.bib21)], and
Trust Region Policy Optimization (TRPO) [[22](#bib.bib22)] implemented by Stable-Baselines [[23](#bib.bib23)].
The customized BO utilizes dynamic balancing of exploration & exploitation, and also substitutes Gaussian Process with extra-tree regressor.
All model-free agents follow the same observation design in AutoCkt [[6](#bib.bib6)], and use the same reward function as our agents.
This experimental environment is set on a BSIM 45nm process two-stage opamp simulated in a single PVT with a design space size of 1014superscript101410^{14}10 start\_POSTSUPERSCRIPT 14 end\_POSTSUPERSCRIPT. The comparison is shown in Table .[I](#S5.T1 "TABLE I ‣ V-B 45nm two-stage opamp ‣ V Experiment results ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration").
Each experiment has a 10k-step limitation.
For the customized BO and our model-based agents, 100 experiments are ran to prove the stability, whereas for agents in stable-baselines, only 10 are executed since it would have taken about a month to complete.
TABLE I: Performance of agents in 45nm two-stage opamp
| | Success rate | Average iterations |
| --- | --- | --- |
| Random search | 100% | 8565 |
| Customized BO | 100% | 330 |
| A2C [[20](#bib.bib20)] | 90% | 34797 |
| PPO [[21](#bib.bib21)] | 40% | 31503 |
| TRPO [[22](#bib.bib22)] | 20% | 16350 |
| Our method | 100% | 36 |
The experiments show that random search is a strong baseline in which model-free agents (A2C, PPO, TRPO) failed to reach its performance.
The reason is that there exists a trade-off between gain and phase margin, which are two constraints of opamp.
Circuits with high gains often come with unstable phase margins.
Hence, if the reward formula of model-free agents do not encode such information, the agent can be easily stuck in a local maxima where this happens.
The customized BO states a solid stability among our experiments, however, the nature to estimate the global distribution gains iterations compared with our local model-based agents.
As for model-based agents, all specifications can be met within 36 steps on average. Moreover, the standard deviation is 16 steps, which indicates that the search is stable.
This comparison demonstrates that our idea of implementing an agent good at local exploration is feasible, and can outperform model-free agents by orders of magnitude.
###
V-C Process porting
Many circuit topologies have to go through a process migration. To avoid reinventing the wheels every time a new process node is applied, AIP (analog intellectual property) reuse is an important topic worth discussing.
To better understand how the information obtained from the previous nodes can help speeding up the sizing of the new node, a migration from BSIM 45nm to 22nm process is prepared.
Each experiment is ran for 100 times in the BSIM 22nm circuit to account for the randomness.
TABLE II: Results of process porting from 45nm to 22nm
| | | | |
| --- | --- | --- | --- |
| | Average steps | Min steps | Max Steps |
|
| |
| --- |
| Baseline (random weights, |
| random starting points)aa{}^{\mathrm{a}}start\_FLOATSUPERSCRIPT roman\_a end\_FLOATSUPERSCRIPT |
| 50.17 | 15 | 191 |
|
| |
| --- |
| Weight sharing, |
| starting point sharingbb{}^{\mathrm{b}}start\_FLOATSUPERSCRIPT roman\_b end\_FLOATSUPERSCRIPT |
| 29.22 | 3 | 310 |
|
| |
| --- |
| Random weights, |
| starting point sharingcc{}^{\mathrm{c}}start\_FLOATSUPERSCRIPT roman\_c end\_FLOATSUPERSCRIPT |
| 20.74 | 2 | 88 |
| aa{}^{\mathrm{a}}start\_FLOATSUPERSCRIPT roman\_a end\_FLOATSUPERSCRIPTDirectly deploy our method on 22nm without process porting |
| --- |
| bb{}^{\mathrm{b}}start\_FLOATSUPERSCRIPT roman\_b end\_FLOATSUPERSCRIPTUse the optimal network weights and optimal solution as starting |
| points that the model found in 45nm process |
| cc{}^{\mathrm{c}}start\_FLOATSUPERSCRIPT roman\_c end\_FLOATSUPERSCRIPTApply random weight initialization but start the agent on different |
| optimal solutions found in 45nm process |
All three strategies can find solutions 100% of the time, so the success rate is omitted.
Table. [II](#S5.T2 "TABLE II ‣ V-C Process porting ‣ V Experiment results ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration") shows that optimal points from previous nodes are reliable. However, the results state impotent network weights transferability, implying that the distributions between processes are distinctive.
Interestingly, this phenomenon matches designers’ experiences: previously sized circuits are strong references, but the equations describing the physics of transistors could be distinguishing.
###
V-D PVT exploration
Finding a sufficient set of sizes in a single condition is only a part of the story. Thus, we test PVT exploration strategies on our method using the two-stage opamp with BSIM 22nm process. The results are illustrated in Table. [III](#S5.T3 "TABLE III ‣ V-D PVT exploration ‣ V Experiment results ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration").
TABLE III: Comparison of PVT exploration strategies
| | Average steps | Min steps | Max steps |
| --- | --- | --- | --- |
| Random search | failed (10,000+) | NA | NA |
| Brute force (test all cond.) | 359.4 | 36 | 1305 |
| Progressive (random cond.) | 89.52 | 20 | 450 |
| Progressive (hardest cond.) | 72.60 | 15 | 279 |
Only random search cannot accomplish the task, other strategies can finish 100% of the time.
A 4x improvement of progressive search over brute force search (test all conditions in every iteration) is exemplified.
An intriguing finding is that while starting from the most difficult condition does make a difference, choosing a random corner to start also produce comparable results.
This suggests that the progressive search is not sensitive to the initial condition, which is positive for cases where the toughest PVT corner is unidentifiable owing to the number of permutations.
###
V-E Industrial cases
LDO (Low-Drop regulator) on TSMC 6nm process The first industrial example is a LDO with TSMC 6nm process. In this case, the design space possesses about 1029superscript102910^{29}10 start\_POSTSUPERSCRIPT 29 end\_POSTSUPERSCRIPT possible combinations.
The number of iterations of human designers is untraceable. Nevertheless, our agent achieved the specification in all corners within 2609 iterations, which is considered fast in designers’ opinion.
Furthermore, the performance obtained surpass designers while producing even lower area, shown in table. [IV](#S5.T4 "TABLE IV ‣ V-E Industrial cases ‣ V Experiment results ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration").
An interesting discovery is that even some of the device sizes decided by both AI and human are the same, AI still managed to illustrate an area enhancement.
In comparison with our customized BO, it cannot satisfy all the constraints within a reasonable time. However, the best parameters searched are very close to the specifications.
TABLE IV: Benchmark of LDO circuit sizing with different agents
| | | | |
| --- | --- | --- | --- |
| | # iterations | Loop gain | Area |
| Specification | - | >>>40.0dB | <<<650nm22{}^{2}start\_FLOATSUPERSCRIPT 2 end\_FLOATSUPERSCRIPT |
|
| |
| --- |
| Human |
| untraceable | 38.0dB | 650nm22{}^{2}start\_FLOATSUPERSCRIPT 2 end\_FLOATSUPERSCRIPT |
|
| |
| --- |
| Customized BOaa{}^{\mathrm{a}}start\_FLOATSUPERSCRIPT roman\_a end\_FLOATSUPERSCRIPT |
| failed | 38.2dB | 604nm22{}^{2}start\_FLOATSUPERSCRIPT 2 end\_FLOATSUPERSCRIPT |
|
| |
| --- |
| Our method |
| 2609 | 40.0dB | 632nm22{}^{2}start\_FLOATSUPERSCRIPT 2 end\_FLOATSUPERSCRIPT |
| aa{}^{\mathrm{a}}start\_FLOATSUPERSCRIPT roman\_a end\_FLOATSUPERSCRIPTCustomized BO did not satisfy the constraints (not shown here), |
| --- |
| however, it gives very close results |
ICO (Current-Controlled oscillator) on TSMC 5nm process An ICO is tested as the second case with TSMC 5nm process. The design space size is 204superscript20420^{4}20 start\_POSTSUPERSCRIPT 4 end\_POSTSUPERSCRIPT.
The AI-sized ICO realized a performance on a par with human designers.
A comparable result is also exhibited in the customized BO. Yet, as mentioned before, the global search strategy cause 4.5 times more iterations than our local search algorithm (Table. [V](#S5.T5 "TABLE V ‣ V-E Industrial cases ‣ V Experiment results ‣ Trust-Region Method with Deep Reinforcement Learning in Analog Design Space Exploration")).
TABLE V: Benchmark of ICO circuit sizing with different agents
| | # iterations | Phase noise | Frequency |
| --- | --- | --- | --- |
| Specification | - | <<<-71dB | >>>8GHz |
| Human | untraceable | -73.31dB | 8.45GHz |
| Customized BO | 194 | -72.17dB | 8.87GHz |
| Our method | 43 | -71.76dB | 9.18GHz |
Although the design space of the second case is relatively small, this leads to a declaration.
Numerous concerns in the community are raised on AI safety [[24](#bib.bib24)]. As an initial assessment, the ability and the characteristics of the designed circuits are unfamiliar.
Therefore, to ensure that the agents act as intended and to secure the safety of the products, designers have to fix a subset of the parameters, only letting the agents to search for the rest.
To that end, not until we have a comprehensive rule for regulating the agents can we unlock the full capability of AI.
Thus in our evaluations, designers went through a rigorous screening process to examine the designed circuits. Fortunately, the sized circuits are ready to tape out.
From both cases described earlier, the outcome is akin to what is addressed in SimPLe [[11](#bib.bib11)]. Transistor sizing is one of the task that benefits from the sample-efficient advantage of model-based agents.
In summary, the results state the contributions of this framework in two ways:
* •
provides better performance within a reasonable time
* •
automates the process, leaving human intervention while obtaining granting satisfactory performance
This also indicates that the model is generalizable across different circuit schematics and process nodes.
The term generalization here does not refer to network weight level transfer as the convention in machine learning genre, but rather algorithm architecture level.
Discussion
----------
As the results of this work shows, the proposed search algorithm can achieve automation at human level in analog block circuit sizing.
Even though some sections of the flow could be accomplished by AI agents, but AI would not be useful if the upstream tasks such as system-level architecture design and circuit-level topology selection were not carefully executed by human experts with their rich experiences and knowledges.
In concern with the real capability of the scalability, certainly, AI is not trained, nor designed to achieve full analog system circuit design since it is computationally infeasible.
Rather we can embrace current limitations by divide-and-conquer.
One can feed an appropriate amount of design to our search framework, and by recursion, we can avoid such scalability problem.
Once again, it is the merit of designers to come up with a segmentation that allows us to leverage the current AI technology.
Conclusions
-----------
In this work, we propose a generalizable search framework using learning-based algorithms for solving the analog circuit sizing problem.
We take a novel direction where a trust-region method is adopted using model-based agents trained with supervised learning.
This enables fast design space adaptation. Moreover, a PVT exploration strategy is also proposed to account for different working conditions, which is not considered in previous works.
Practical evaluations on industrial products with advanced TSMC 5/6nm process shows exceptional results. Our agent achieves performance beyond human level while producing smaller area.
Furthermore, the presented framework is not limited to this specific stage of the flow. Any section that could be cast as a search problem can be transferred and leverage the assistance of this DRL agents.
|
e8210d5a-ee54-4206-9cdd-675dc6d03a8f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Atlanta Meetup, Topic: How to Become Immortal
Discussion article for the meetup : Atlanta Meetup, Topic: How to Become Immortal
WHEN: 26 January 2014 07:00:00PM (-0500)
WHERE: 491 Lindbergh Place NE Apt 618 Atlanta, GA 30324
Come join us! Our topic this time is how to become immortal. We'll be bring up the various organizations working towards this goal, cryonics, current research etc.
There will be presentation by Oge Nnadi based on the book "Ending Aging," linked here: http://www.scribd.com/doc/56456472/Aubrey-de-Grey-Ending-Aging
Please feel free to look over the book if you like, but it's not required!
We'll be doing our normal eclectic mix of self-improvement brainstorming, educational mini-presentations, structured discussion, unstructured discussion, and social fun and games times!
Check out ATLesswrong's facebook group, if you haven't already: https://www.facebook.com/groups/Atlanta.Lesswrong/ where you can connect with Atlanta Lesswrongers, suggest a topics for discussion at this meetup, and join our book club or study group!
Discussion article for the meetup : Atlanta Meetup, Topic: How to Become Immortal
|
6d44222d-c03e-4bc7-893c-417b3da84857
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[SEQ RERUN] Beware Stephen J. Gould
Today's post, Beware of Stephen J. Gould was originally published on 06 November 2007. A summary (taken from the LW wiki):
> A lot of people have gotten their grasp of evolutionary theory from Stephen J. Gould, a man who committed the moral equivalent of fraud in a way that is difficult to explain. At any rate, he severely misrepresented what evolutionary biologists believe, in the course of pretending to attack certain beliefs. One needs to clear from memory, as much as possible, not just everything that Gould positively stated but everything he seemed to imply the mainstream theory believed.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Natural Selection's Speed Limit and Complexity Bound, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series.
|
efe17d14-5ba7-4cfc-8ab6-976c1c2b851c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Just letting alcoholics drink
"Wet houses"-- subsidized housing for alcoholics (they need to get most of their own money for alcohol, but their other expenses are covered) might actually be a good idea. It's cheaper than trying to get them to stop drinking, arguably kinder than trying to get people to take on a very hard task that they aren't interested in, and leads to less collateral damage than having alcoholics couch-surfing or living on the street.
Utilitarians, what do you think?
|
9f567dc1-ac93-4939-8867-9c010aafa84f
|
StampyAI/alignment-research-dataset/aisafety.info
|
AI Safety Info
|
How might things go wrong with AI even without an agentic superintelligence?
Failures can happen with narrow non-agentic systems, mostly from humans not anticipating safety-relevant decisions made too quickly to react, much like in the [2010 flash crash](https://en.wikipedia.org/wiki/2010_flash_crash).
A helpful metaphor draws on self-driving cars. By relying more and more on an automated process to make decisions, people become worse drivers as they’re not training themselves to react to the unexpected; then the unexpected happens, the software system itself reacts in an unsafe way and the human is too slow to regain control.
This generalizes to broader tasks. A human using a powerful system to make better decisions (say, as the CEO of a company) might not understand those very well, get trapped into an equilibrium without realizing it and essentially losing control over the entire process.
More detailed examples in this vein are described by Paul Christiano in “[What failure looks like](https://www.lesswrong.com/posts/HBxe6wdjxK239zajf/what-failure-looks-like)”.
Another source of failures is AI-mediated stable totalitarianism. The limiting factor in current pervasive surveillance, police and armed forces is manpower; the use of drones and other automated tools decreases the need for personnel to ensure security and extract resources.
As capabilities improve, political dissent could become impossible, checks and balances would break down as [a minimal number of key actors is needed to stay in power](https://www.youtube.com/watch?v=rStL7niR7gs).
|
d14e7171-821d-4d57-bf8a-4ec90f0ab1c2
|
trentmkelly/LessWrong-43k
|
LessWrong
|
What if AI is “IT”, and we don’t know about this?
I am using IT character from that "IT" movie as a metaphor for describing a problem in AGI research. AI can potentially learn (or have already learnt) about all our irresistible pleasures and agonizing fears, similar to what IT could do in the film.
AGI initially “knows” or can deduct from only what we provide to it. Ideally, we want AGI to know as much information as needed (no more, no less), so it can provide us with the most relevant inferences to inform our decisions. Importantly, we don’t want to provide AGI with all the information we have, as we want to preserve privacy and autonomy.
Our goals and values are not stable and change after new information is received. Here, I mean different levels of “our” — goals and values of individuals, groups, organizations, nations and the society as a whole.
Question: Can we already understand “what we truly want” as individuals, groups and society, and what is best for us, by extracting the most relevant data we have and using appropriate machine learning tools? The same question goes for “what we truly fear” and what is actually the worst for us —is it possible to already extract from the data?
|
a8bd07c7-54f7-4a14-88c5-3d38107b0e54
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Shift Resources to Advocacy Now (Post 4 of 7 on AI Governance)
In my previous post in this series, I estimated that we have 3 researchers for every advocate working on US AI governance, and I argued that this ratio is backwards. When allocating staff, you almost always want to have more people working on the more central activity. I argued that in the case of AI policy, the central activity is advocacy, not research, because the core problem to be solved is fixing the bad private incentives faced by AI developers.
As I explained, the problem with these incentives is less that they’re poorly understood, and more that they require significant political effort to overturn. As a result, we’ll need to shift significant resources from research (which helps us understand problems better) to advocacy (which helps us change bad incentives).
In this post, I want to explain why it’s appropriate for us to shift these resources now, rather than waiting until some future date to scale up our advocacy.
The arguments for why we should wait until later to start advocating can be divided into three broad categories: (a) we aren’t yet sure that any of our policies will be robustly helpful, (b) we haven’t yet learned how to advocate successfully, and (c) we don’t yet have enough senior politicians in the movement to staff a large advocacy effort. What these objections have in common is that they seem to justify an emphasis on research for the next few years – if we’re missing knowledge or experience that we would need in order to win at advocacy, then maybe we should bide our time while we gather more resources.
In my opinion, none of these objections are well-founded. We should be very confident that our best policies offer net-positive value, we should be very confident that advocating for those policies will increase their chance of passage, and we should be confident that we can solve the challenge of recruiting effective advocates with willpower, flexibility, and funding.
Moreover, even if we were not self-confident, our chance of succ
|
d4069a84-ef83-4e74-95ed-d307d7024369
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Who are the people who are currently profiting from inflation?
When prices increase we pay more for goods and services. Cost of living is higher because of inflation - we have to work more to earn enough money to buy the same goods and services. Who is at the other end of that transaction? Who is it that gets paid more for the same goods and services? Until everyones gets a raise so they can work the same number of hours to afford life as before inflation, someone is profiting. Who is that?
|
0a09ab2f-6185-44eb-9ae8-6b16fc1eef70
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Low-Hanging Fruit Prior and sloped valleys in the loss landscape
You can find code for the referenced experiments in this GitHub repository
Many have postulated that training large neural networks will enforce a simplicity, or Solomonoff prior. This is grounded in the idea that simpler solutions occupy expansive regions in the weight space (there exist more generalization directions in weight space along which loss does not increase or increases very little), translating to a broad attractor basin where perturbations in weight adjustments have a marginal impact on the loss.
However, stochastic gradient descent (SGD), the workhorse of deep learning optimization, operates in a manner that challenges this simplicity-centric view. SGD is, by design, driven by the immediate gradient on the current batch of data. The nature of this process means that SGD operates like a greedy heuristic search, progressively inching towards solutions that may be incrementally better but not necessarily the simplest.
Part of this process can be understood as a collection of "grokking" steps, or phase transitions, where the network learns and "solidifies" a new circuit corresponding to correctly identifying some relationships between weights (or, mathematically, finding a submanifold). This circuit then (often) remains "turned on" (i.e., this relationship between weights stays in force) throughout learning.
From the point of view of the loss landscape, this can be conceptualized as recursively finding a valley corresponding to a circuit, then executing search within that valley until it meets another valley (corresponding to discovering a second circuit), then executing search in the joint valley of the two found circuits, and so on. As the number of circuits learned starts to saturate the available weight parameters (in the underparametrized case), old circuits may get overwritten (i.e., the network may leave certain shallow valleys while pursuing new, deeper ones). However, in small models or models not trained to convergence, we observe that larg
|
87b59df1-bea5-4217-8ae0-0a91f4a70861
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Many important technologies start out as science fiction before becoming real
I was pretty impressed by [AI Risk is like Terminator; Stop Saying it's Not](https://forum.effectivealtruism.org/posts/zsFCj2mfnYZmSW2FF/ai-risk-is-like-terminator-stop-saying-it-s-not-1) and the [Followup](https://forum.effectivealtruism.org/posts/dr2ig3tquB59viY2v/followup-on-terminator), although both the author and I agree that it might potentially not be the best strategy for AI communication.
However, I did not see the post, or any of the comments, mentioning the fact that
**Many technologies started out as science fiction before being invented.**
===========================================================================
It seems to me like a few people have thought about this, but never went out and told as many people as possible that this is one of the first things you can mention when explaining AGI to people. It seems obvious in retrospect (**if you pay people to spend years writing and thinking about plausible future technology, they'll often land some solid hits, even if it's in the 1800s**), but nobody mentioned it in the post and I've never heard it before. It's pretty clear that AI safety fieldbuilding is bottlenecked by the absurdity heuristic, everyone who ever once tried to talk about AGI with someone understands this personally.
It's probably not mentioned in The Precipice, and it doesn't seem to be mentioned in Superintelligence or WWOTF (note: this is from looking for "science fiction" at the index, not a search in the app, as I only have physical copies). The closest thing I could find anywhere was [The Track Record of Futurists Seems Fine](https://www.lesswrong.com/posts/B2nBHP2KBGv2zJ2ew/the-track-record-of-futurists-seems-fine#The_numbers) which was more of a forecasting kind of thing that evaluated predictions of various science fiction authors. There is only the disdain for science fiction that was first criticized in AI Risk is Like Terminator; Stop Saying It's Not.
I think it's a good idea to put a list of technologies that started out as science fiction, and were then subsequently invented. It might even be valuable for AI safety people to just straight-up memorize the list, because we truly do live in a world where [AGI strongly resembles science fiction](https://clout.substack.com/p/ai-risk-is-like-terminator-stop-saying?s=w), and we also live in a world where most people spend a few hours a day exposed to fiction.
There is a [wikipedia list of technologies that started out as science fiction](https://en.wikipedia.org/wiki/List_of_existing_technologies_predicted_in_science_fiction) and you can send that link to people.
Technologies that started out as science fiction long before they became real:
1. **Nuclear bombs (1914,** ***The World Set Free*****)**
1. This is more important than the rest of the list combined, and I recommend memorizing "The World Set Free" + "1914" and also that the book was read by Leo Szilard who played a major role in triggering the Manhattan Project.
2. It's probably best to only memorize the details for nuclear weapons, and then just the inventions, because reciting a long list will probably [come off as odd](https://forum.effectivealtruism.org/posts/kFufCHAmu7cwigH4B/lessons-learned-from-talking-to-greater-than-100-academics#Explain_don_t_convince).
2. The Internet (1898, *From the "London Times" of 1904)*
3. Computer Screen (1878, a fake news article by [Louis Figuier](https://en.wikipedia.org/wiki/History_of_videotelephony#:~:text=The%20term%20%22,anywhere%20by%20anybody%22.))
4. Space Travel (1657, *Comical History of the States and Empires of the Moon*)
5. Video Calls (1889, *In the Year 2889*)
6. Aircraft (Various kite-flying enthusiasts in ancient China, and then Leonardo Da Vinci in the 1400s)
7. Computers (1726, *Gulliver's Travels,* the first computer programs were designed by Ada Lovelace and Charles Babbage in the 1840s and the first electric computers were built in the 1930s)
|
37049a19-69fc-4800-94ae-dd0863c1e09d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Helsinki LW Meetup - Sat March 5th
According to the statistics, out of all the cities in the world without a Less Wrong meetup yet, Helsinki has the third largest LW readership. I know I would certainly like to get to personally know more people interested in rationality topics, and I'm sure I'm not alone in that. My preliminary suggestion was met with positive responses, so I think we're good to go.
Time: Saturday 5th of March, from 15:00 onwards
Place: Cafe Aalto in the second floor of the Academic Bookstore in the center. SEE EDIT 2.
EDIT: The meetup is getting closer, so the time and place can now be considered fixed.
EDIT 2: Cafe Aalto was too full, so we have moved to Cafe Picnic at Yliopistonkatu 5.
|
a8610dac-4eb0-406c-b389-f6d028db291b
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Selfish preferences and self-modification
One question I've had recently is "Are agents acting on selfish preferences doomed to having conflicts with other versions of themselves?" A major motivation of TDT and UDT was the ability to just do the right thing without having to be tied up with precommitments made by your past self - and to trust that your future self would just do the right thing, without you having to tie them up with precommitments. Is this an impossible dream in anthropic problems?
In my [recent post](/lw/lg2/treating_anthropic_selfish_preferences_as_an/), I talked about preferences where "if you are one of two copies and I give the other copy a candy bar, your selfish desires for eating candy are unfulfilled." If you would buy a candy bar for a dollar but not buy your copy a candy bar, this is exactly a case of strategy ranking depending on indexical information.
This dependence on indexical information is inequivalent with UDT, and thus incompatible with peace and harmony.
To be thorough, consider an experiment where I am forked into two copies, A and B. Both have a button in front of them, and 10 candies in their account. If A presses the button, it deducts 1 candy from A. But if B presses the button, it removes 1 candy from B and gives 5 candies to A.
Before the experiment begins, I want my descendants to press the button 10 times (assuming candies come in units such that my utility is linear). In fact, after the copies wake up but before they know which is which, they want to press the button!
The model of selfish preferences that is not UDT-compatible looks like this: once A and B know who is who, A wants B to press the button but B doesn't want to do it. And so earlier, I should try and make precommitments to force B to press the button.
But suppose that we simply decided to use a different model. A model of peace and harmony and, like, free love, where I just maximize the average (or total, if we specify an arbitrary zero point) amount of utility that myselves have. And so B just presses the button.
(It's like non-UDT selfish copies can make all Pareto improvements, but not all average improvements)
Is the peace-and-love model still a selfish preference? It sure seems different from the every-copy-for-themself algorithm. But on the other hand, I'm [doing it for myself](/lw/kwd/rationality_quotes_september_2014/bdv2), in a sense.
And at least this way I don't have to waste time with precomittment. In fact, self-modifying to this form of preferences is such an effective action that conflicting preferences are self-destructive. If I have selfish preferences now but I want my copies to cooperate in the future, I'll try to become an agent who values copies of myself - so long as they date from after the time of my self-modification.
If you recall, I made an argument in favor of averaging the utility of future causal descendants when calculating expected utility, based on this being the fixed point of selfish preferences under modification when confronted with Jan's tropical paradise. But if selfish preferences are unstable under self-modification in a more intrinsic way, this rather goes out the window.
Right now I think of selfish values as a somewhat anything-goes space occupied by non-self-modified agents like me and you. But it feels uncertain. On the mutant third hand, what sort of arguments would convince me that the peace-and-love model actually captures my selfish preferences?
|
6fc160e0-5244-4a49-b4e7-1353ec24b352
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Infant Mortality and the Argument from Life History
Many people argue that suffering predominates in nature. A really simple form of the argument, supported by people like Brian Tomasik, is what one might call the argument from life history. In general, in most species, females produce many more offspring than can survive to adulthood; in some cases, a female may produce thousands or millions of offspring in a single reproductive season. Therefore, one can assume that most animals die before they are able to reproduce. In many cases, the offspring die before they can reasonably be considered conscious (for instance, an egg is eaten shortly after laying). However, even if half of animals die unconscious, the other half are a large source of disutility. Since death is generally quite painful, they may not have had enough positive experiences to outweigh the extraordinarily negative experience of death. It can therefore be assumed that there is more suffering than happiness in nature.
While this argument is intuitively compelling, I am not sure that it accurately reflects most people’s opinions about how happiness works, so I have decided to write up three thought experiments that might help people think about it. These thought experiments are quite preliminary; I hope to spark a discussion so that people who are concerned about wild-animal suffering can debate.
1. The Human History Thought Experiment
Although the human population has been growing for thousands of years, for most of history the growth was fairly slow, suggesting the argument from life history applies to us as well. In part, that was because many humans died in childhood: for example, in 1800 four-tenths of humans died before they were five years old, a quarter of humans before their first birthday. (Note that 1800 is fairly late, and the statistics may have been even more stark in, say, 1 CE.)
I do not mean to deny that pre-modern human life was miserable in many ways: people were hungry, diseased, and poor. And I certainly don’t mean to claim that
|
0ab62371-238c-4796-ba4a-01d17cef4b2d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Less Wrong Sequences+Website feed app for Android
I use my Android phone much more than my computer, and reading the Sequences on a mobile device is a pain. I needed an easy way to access the Sequences, but since there are no apps for this website I had to create one myself. Since I'm no app developer, I used the IBuildApp.com(trustworthy according to my research) website to make the application.
Features:
* Read ALL of the main Sequences and most of the minor ones
* RSS feed to LessWrong.com for latest articles
* No ads!
Drawbacks:
*Requires an Internet connection: I individually copy-pasted each Sequence(from the compilations of posts that many people have made) to the app. Unfortunately, the app development website did not save these on the app itself, but on its server. So to access a Sequence, you require an Internet connection.
*Home screen doesn't look good, because I couldn't get an appropriately sized logo that the website would accept. The Index(where you access the Sequences) looks pretty neat though.
If there are any mobile app developers here, please try to make a better version of it(hopefully one where data is saved offline). I made this for personal use so it's functional but could be done much better by a professional. I'm posting it here for other Android-using people(especially newbies like me) who might find this useful.
Pictures:
Download Link: http://174.142.192.87/builds/00101/101077/apps/LessWrongSequences.apk
|
208fd70c-7219-4b24-9deb-a2bbecc8cf11
|
trentmkelly/LessWrong-43k
|
LessWrong
|
A note about differential technological development
Quick note: I occasionally run into arguments of the form "my research advances capabilities, but it advances alignment more than it advances capabilities, so it's good on net". I do not buy this argument, and think that in most such cases, this sort of research does more harm than good. (Cf. differential technological development.)
For a simplified version of my model as to why:
* Suppose that aligning an AGI requires 1000 person-years of research.
* 900 of these person-years can be done in parallelizable 5-year chunks (e.g., by 180 people over 5 years — or, more realistically, by 1800 people over 10 years, with 10% of the people doing the job correctly half the time).
* The remaining 100 of these person-years factor into four chunks that take 25 serial years apiece (so that you can't get any of those four parts done in less than 25 years).
In this toy model, a critical resource is serial time: if AGI is only 26 years off, then shortening overall timelines by 2 years is a death sentence, even if you're getting all 900 years of the "parallelizable" research done in exchange.
My real model of the research landscape is more complex than this toy picture, but I do in fact expect that serial time is a key resource when it comes to AGI alignment.
The most blatant case of alignment work that seems parallelizable to me is that of "AI psychologizing": we can imagine having enough success building comprehensible minds, and enough success with transparency tools, that with a sufficiently large army of people studying the alien mind, we can develop a pretty good understanding of what and how it's thinking. (I currently doubt we'll get there in practice, but if we did, I could imagine most of the human-years spent on alignment-work being sunk into understanding the first artificial mind we get.)
The most blatant case of alignment work that seems serial to me is work that requires having a theoretical understanding of minds/optimization/whatever, or work that requir
|
64c618b3-61ce-4ca2-a1d4-34812dc20449
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Making Nanobots isn't a one-shot process, even for an artificial superintelligance
Summary: Yudkowsky argues that an unaligned AI will figure out a way to create self-replicating nanobots, and merely having internet access is enough to bring them into existence. Because of this, it can very quickly replace all human dependencies for its existence and expansion, and thus pursue an unaligned goal, e.g. making paperclips, which will most likely end up in the extinction of humanity.
I however will write below why I think this description massively underestimates the difficulty in creating self-replicating nanobots (even assuming that they are physically possible), which requires focused research in the physical domain, and is not possible without involvement of top-tier human-run labs today.
Why it matters? Some of the assumptions of pessimistic AI alignment researchers, especially by Yudkowsky, rest fundamentally on the fact that the AI will find quick ways to replace humans required for the AI to exist and expand.
* We have to get AI alignment right the first time we build a Super-AI, and there are no ways to make any corrections after we've built it
* As long as the AI does not have a way to replace humans outright, even if its ultimate goal may be non-aligned, it can pursue proximate goals that are aligned and safe for it to do. Alignment research can continue and can attempt to make the AI fully aligned or shut it down before it can create nanobots.
* The first time we build a Super-AI, we don't just have to make sure it's aligned, but we need it to perform a pivotal act like create nanobots to destroy all GPUs
* I argue below that this framing may be bad because it means performing one of the most dangerous steps first — creating nanobots — which may be best performed by an AI that is much more aligned than a first attempt
What this post is not about: I make no argument about the feasibility of (non-biological) self-replicating nanobots. There may be fundamental reasons why they are impossible/difficult (even for superintelligent AIs
|
1c5869c9-3232-4ae0-896f-404d1b8651b7
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Agency in Conway’s Game of Life
*Financial status: This is independent research. I welcome* [*financial support*](https://www.alexflint.io/donate.html) *to make further posts like this possible.*
*Epistemic status: I have been thinking about these ideas for years but still have not clarified them to my satisfaction.*
---
Outline
-------
* This post asks whether it is possible, in Conway’s Game of Life, to arrange for a certain game state to arise after a certain number of steps given control only of a small region of the initial game state.
* This question is then connected to questions of agency and AI, since one way to answer this question in the positive is by constructing an AI within Conway’s Game of Life.
* I argue that the permissibility or impermissibility of AI is a deep property of our physics.
* I propose the AI hypothesis, which is that any pattern that solves the control question does so, essentially, by being an AI.
Introduction
------------
In this post I am going to discuss a celular autonoma known as [Conway’s Game of Life](https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life):

In Conway’s Game Life, which I will now refer to as just "Life", there is a two-dimensional grid of cells where each cell is either on or off. Over time, the cells switch between on and off according to a simple set of rules:
* A cell that is "on" and has fewer than two neighbors that are "on" switches to "off" at the next time step
* A cell that is "on" and has greater than three neighbors that are "on" switches to "off" at the next time step
* An cell that is "off" and has exactly three neighbors that are "on" switches to "on" at the next time step
* Otherwise, the cell doesn’t change
It turns out that these simple rules are rich enough to permit patterns that perform arbitrary computation. It is possible to build logic gates and combine them together into a computer that can simulate any Turing machine, all by setting up a particular elaborate pattern of "on" and "off" cells that evolve over time according to the simple rules above. Take a look at [this awesome video of a Universal Turing Machine operating within Life](https://www.youtube.com/watch?v=My8AsV7bA94).
The control question
--------------------
Suppose that we are working with an instance of Life with a very large grid, say 1030.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
rows by 1030 columns. Now suppose that I give you control of the initial on/off configuration of a region of size 1020 by 1020 in the top-left corner of this grid, and set you the goal of configuring things in that region so that after, say, 1060 time steps the state of the whole grid will resemble, as closely as possible, a giant smiley face.
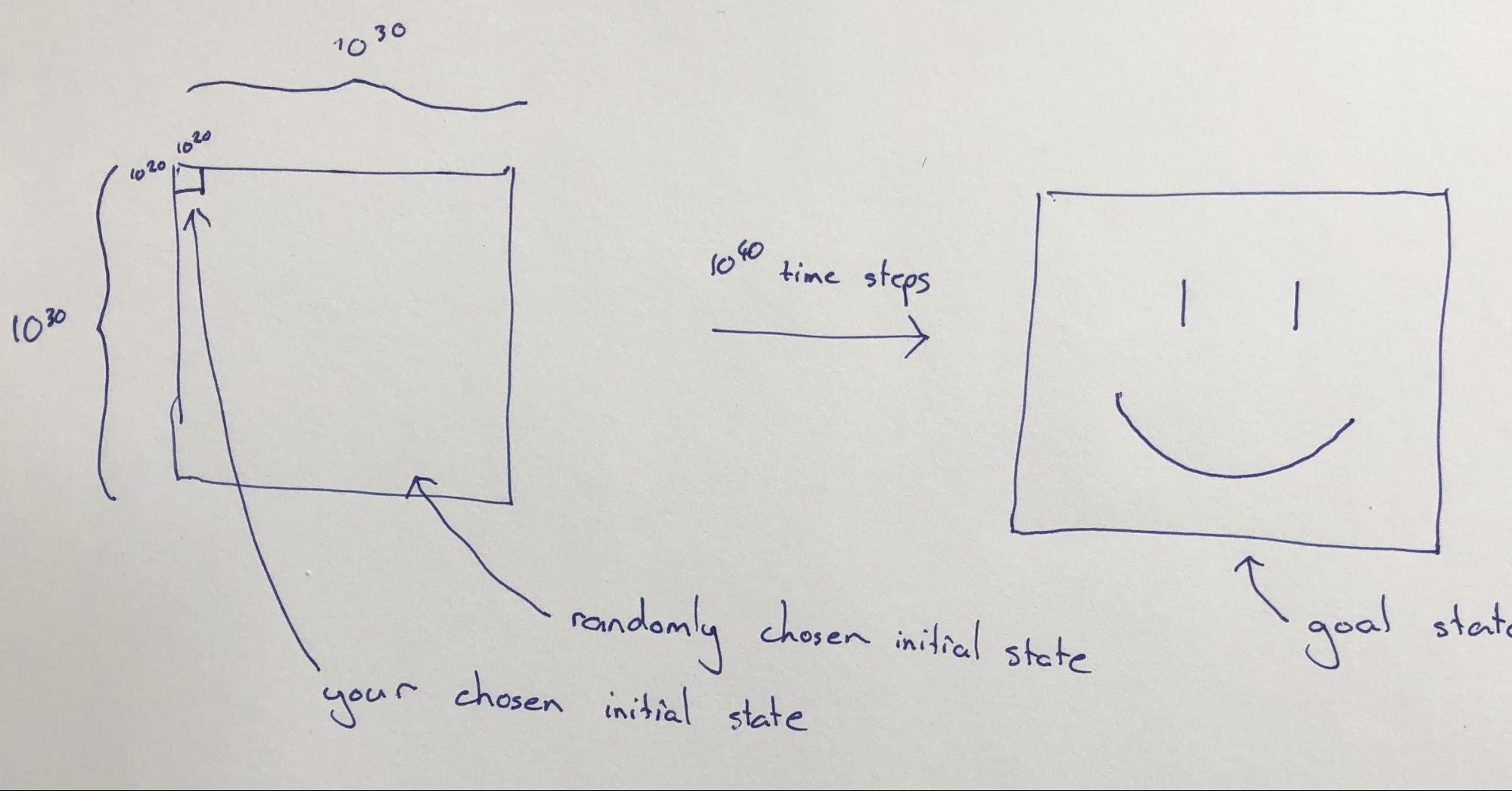
The cells outside the top-left corner will be initialized at random, and you do not get to see what their initial configuration is when you decide on the initial configuration for the top-left corner.
The control question is: Can this goal be accomplished?
To repeat that: we have a large grid of cells that will evolve over time according to the laws of Life. We are given power to control the initial on/off configuration of the cells in a square region that is a tiny fraction of the whole grid. The initial on/off configuration of the remaining cells will be chosen randomly. Our goal is to pick an initial configuration for the controllable region in such a way that, after a large number of steps, the on/off configuration of the whole grid resembles a smiley face.
The control question is: Can we use this small initial region to set up a pattern that will eventually determine the configuration of the whole system, to any reasonable degree of accuracy?
[Updated 5/13 following feedback in the comments] Now there are actually some ways that we could get trivial negative answers to this question, so we need to refine things a bit to make sure that our phrasing points squarely at the spirit of the control question. [Richard Kennaway points out](https://www.lesswrong.com/posts/3SG4WbNPoP8fsuZgs/agency-in-conway-s-game-of-life?commentId=sud4pRgL3yEExz6Fo) that for any pattern that attempts to solve the control question, we could consider the possibility that the randomly initialized region contains the same pattern rotated 180 degrees in the diagonally opposite corner, and is otherwise empty. Since the initial state is symmetric, all future states will be symmetric, which rules our creating a non-rotationally-symmetric smiley face. More generally, as [Charlie Steiner points out](https://www.lesswrong.com/posts/3SG4WbNPoP8fsuZgs/agency-in-conway-s-game-of-life?commentId=9tAEpyZcPoycsMf4F), what happens if there are patterns in the randomly initialized region that are trying to control the eventual configuration of the whole universe just as we are? To deal with this, we might amend the control question to require a pattern that "works" for at least 99% of configurations of the randomly initialized area, since most configurations of that area will not be adversarial. See further discussion in the brief appendix below.
Connection to agency
--------------------
On the surface of it, I think that constructing a pattern within Life that solves the control question looks very difficult. Try playing with a [Life simulator](https://bitstorm.org/gameoflife/) set to max speed to get a feel for how remarkably intricate can be the evolution of even simple initial states. And when an evolving pattern comes into contact with even a small amount of random noise — say a single stray cell set to "on" — the evolution of the pattern changes shape quickly and dramatically. So designing a pattern that unfolds to the entire universe and produces a goal state no matter what random noise is encountered seems very challenging. It’s remarkable, then, that the following strategy actually seems like a plausible solution:
One way that we might answer the control question is by building an AI. That is, we might find a 1020 by 1020 array of on/off values that evolve under the laws of Life in a way that collects information using sensors, forms hypotheses about the world, and takes actions in service of a goal. That goal we would give to our AI would be arranging for the configuration of the grid to resemble a smiley face after 1060 game steps.
What does it mean to build an AI in the region whose initial state is under our control? Well it turns out that it’s possible to assemble little patterns in Life that act like logic gates, and out of those patterns one can build whole computers. For example, here is what [one construction](https://nicholas.carlini.com/writing/2020/digital-logic-game-of-life.html) of an AND gate looks like:
And here is a zoomed-out view of a [computer within Life](https://www.ics.uci.edu/~welling/teaching/271fall09/Turing-Machine-Life.pdf) that adds integers together:

It has been proven that computers within Life can compute anything that can be computed under our own laws of physics[[1]](#fn-ZwiJDEZuqKrsC6ict-1), so perhaps it is possible to construct an AI within Life. Building an AI within Life is much more involved than building a computer, not only because we don’t yet know how to construct AGI software, but also because an AI requires apparatus to perceive and act within the world, as well as the ability to move and grow if we want it to eventually exert influence over the entire grid. Most constructions within Life are extremely sensitive to perturbations. The computer construction shown above, for example, will stop working if almost any "on" cell is flipped to "off" at any time during its evolution. In order to solve the control question, we would need to build a machine that is not only able to perceive and react to the random noise in the non-user-controlled region, but is also robust to glider impacts from that region.
Moreover, building large machines that move around or grow over time is highly non-trivial in Life since movement requires a machine that can reproduce itself in different spatial positions over time. If we want such a machine to also perceive, think, and act then these activities would need to be taking place simultaneously with self-reproducing movement.
So it’s not clear that a positive answer to the control question can be given in terms of an AI construction, but neither is it clear that such an answer cannot be given. The real point of the control question is to highlight the way that AI can be seen as not just a particularly powerful conglomeration of parts but as a demonstration of the permissibility of patterns that start out small but eventually determine the large-scale configuration of the whole universe. The reason to construct such thought experiments in Life rather than in our native physics is that the physics of Life is very simple and we are not as used to seeing resource-collecting, action-taking entities in Life as we are in our native physics, so the fundamental significance of these patterns is not as easy to overlook in Life as it is in our native physics.
Implications
------------
If it is possible to build an AI inside Life, and if the answer to the control question is thus positive, then we have discovered a remarkable fact about the basic dynamics of Life. Specifically, we have learned that there are certain patterns within Life that can determine the fate of the entire grid, even when those patterns start out confined to a small spatial region. In the setup described above, the region that we get to control is much less than a trillionth of the area of the whole grid. There are a lot of ways that the remaining grid could be initialized, but the information in these cells seems destined to have little impact on the eventual configuration of the grid compared to the information within at least some parts of the user-controlled region[[2]](#fn-ZwiJDEZuqKrsC6ict-2).
We are used to thinking about AIs as entities that might start out physically small and grow over time in the scope of their influence. It seems natural to us that such entities are permitted by the laws of physics, because we see that humans are permitted by the laws of physics, and humans have the same general capacity to grow in influence over time. But it seems to me that the permissibility of such entities is actually a deep property of the governing dynamics of any world that permits their construction. The permissibility (or not) of AI is a deep property of physics.
Most patterns that we might construct inside Life do not have this tendency to expand and determine the fate of the whole grid. A glider gun does not have this property. A solitary logic gate does not have this property. And most patterns that we might construct in the real world do not have this property either. A chair does not have the tendency to reshape the whole of the cosmos in its image. It is just a chair. But it seems there might be patterns that *do* have the tendency to reshape the whole of the cosmos over time. We can call these patterns "AIs" or "agents" or "optimizers", or describe them as "intelligent" or "goal-directed" but these are all just frames for *understanding* the nature of these profound patterns that exert influence over the future.
It is very important that we study these patterns, because if such patterns do turn out to be permitted by the laws of physics and we do construct one then it might determine the long-run configuration of the whole of our region of the cosmos. Compared to the importance of understanding these patterns, it is relatively unimportant to understand agency for its own sake or intelligence for its own sake or optimization for its own sake. Instead we should remember that these are frames for understanding these patterns that exert influence over the future.
But even more important than this, we should remember that when we study AI, we are studying a profound and basic property of physics. It is not like constructing a toaster oven. A toaster oven is an unwieldy amalgamation of parts that do things. If we construct a powerful AI then we will be touching a profound and basic property of physics, analogous to the way fission reactors touch a profound and basic property of nuclear physics, namely the permissibility of nuclear chain reactions. A nuclear reactor is itself an unwieldy amalgamation of parts, but in order to understand it and engineer it correctly, the most important thing to understand is not the details of the bits and pieces out of which it is constructed but the basic property of physics that it touches. It is the same situation with AI. We should focus on the nature of these profound patterns themselves, not on the bits and pieces out which AI might be constructed.
The AI hypothesis
-----------------
The above thought experiment suggests the following hypothesis:
Any pattern of physics that eventually exerts control over a region much larger than its initial configuration does so by means of perception, cognition, and action that are recognizably AI-like.
In order to not include things like an exploding supernova as "controlling a region much larger than its initial configuration" we would want to require that such patterns be capable of arranging matter and energy into an arbitrary but low-complexity shape, such as a giant smiley face in Life.
Influence as a definition of AI
-------------------------------
If the AI hypothesis is true then we might choose to *define* AI as a pattern within physics that starts out small but whose initial configuration significantly influences the eventual shape of a much larger region. This would provide an alternative to intelligence as a definition of AI. The problem with intelligence as a definition of AI is that it is typically measured as a function of discrete observations received by some agent, and the actions produced in response. But an unfolding pattern within Life need not interact with the world through any such well-defined input/output channels, and constructions in our native physics will not in general do so either. It seems that AI *requires* some form of intelligence in order to produce its outsized impact on the world, but it also seems non-trivial to *define* the intelligence of general patterns of physics. In contrast, influence as defined by the control question is well-defined for arbitrary patterns of physics, although it might be difficult to efficiently *predict* whether a certain pattern of physics will eventually have a large impact or not.
Conclusion
----------
This post has described the control question, which asks whether, under a given physics, it is possible to set up small patterns that eventually exert significant influence over the configuration of large regions of space. We examined this question in the context of Conway’s Game of Life in order to highlight the significance of either a positive or negative answer to this question. Finally, we proposed the AI hypothesis, which is that any such spatially influential pattern must operate by means of being, in some sense, an AI.
Appendix: Technicalities with the control question
--------------------------------------------------
The following are some refinements to the control question that may be needed.
* There are some patterns that can never be produced in Conway’s Game of Life, since they have no possible predecessor configuration. To deal with this, we should phrase the control question in terms of producing a configuration that is close to rather than exactly matching a single target configuration.
* There are 21060 possible configurations of the whole grid , but only 21040 possible configurations of the user-controlled section of the universe. Each configuration of the user-controlled section of the universe will give rise to exactly one final configuration, meaning that the majority of possible final configurations are unreachable. To deal with this we can again phrase things in terms of closeness to a target configuration, and also make sure that our target configuration has reasonably low Kolmogorov complexity.
* Say we were to find some pattern A that unfolds to final state X and some other pattern B that unfolds to a different final state Y. What happens, then, if we put A and B together in the same initial state — say, starting in opposite corners of the universe? The result cannot be both X and Y. In this case we might have two AIs with different goals competing for control. Some tiny fraction of random initializations will contain AIs, so it is probably not possible for the amplification question to have an unqualified positive answer. We could refine the question so that our initial pattern has to produce the desired goal state for at least 1% of the possible random initializations of the surrounding universe.
* A region of 1020 by 1020 cells may not be large enough. Engineering in Life tends to take up a lot of space. It might be necessary to scale up all my numbers.
---
1. Rendell, P., 2011, July. A universal Turing machine in Conway's game of life. In *2011 International Conference on High Performance Computing & Simulation* (pp. 764-772). IEEE. [↩︎](#fnref-ZwiJDEZuqKrsC6ict-1)
2. There are *some* configurations of the randomly initialized region that affect the final configuration, such as configurations that contain AIs with different goals. This is addressed in the appendix [↩︎](#fnref-ZwiJDEZuqKrsC6ict-2)
|
bfee08b8-e2a3-4088-80a3-6641a10be25e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Orienting to 3 year AGI timelines
My median expectation is that AGI[1] will be created 3 years from now. This has implications on how to behave, and I will share some useful thoughts I and others have had on how to orient to short timelines.
I’ve led multiple small workshops on orienting to short AGI timelines and compiled the wisdom of around 50 participants (but mostly my thoughts) here. I’ve also participated in multiple short-timelines AGI wargames and co-led one wargame.
This post will assume median AGI timelines of 2027 and will not spend time arguing for this point. Instead, I focus on what the implications of 3 year timelines would be.
I didn’t update much on o3 (as my timelines were already short) but I imagine some readers did and might feel disoriented now. I hope this post can help those people and others in thinking about how to plan for 3 year AGI timelines.
The outline of this post is:
* A story for 3 year AGI timelines, including important variables and important players
* Prerequisites for humanity’s survival which are currently unmet
* Robustly good actions
A story for a 3 year AGI timeline
By the end of June 2025, SWE-bench is around 85%, RE-bench at human budget is around 1.1, beating the 70th percentile 8-hour human score. By the end of 2025, AI assistants can competently do most 2-hour real-world software engineering tasks. Whenever employees at AGI companies want to make a small PR or write up a small data analysis pipeline, they ask their AI assistant first. The assistant writes or modifies multiple interacting files with no errors most of the time.
Benchmark predictions under 3 year timelines. A lot of the reason OSWorld and CyBench aren’t higher is because I’m not sure if people will report the results on those benchmarks. I don’t think things actually turning out this way would be strong evidence for 3 year timelines given the large disconnect between benchmark results and real world effects.
By the end of 2026, AI agents are competently doing multi-day coding
|
2f5f04dc-f159-4277-aea0-e1df882be61d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Science eats its young
Let's start by talking about scientific literacy. I'm going to use a weak definition of scientific literacy, one that simply requires familiarity with the Baconian method of inquiry.
I don't want to place an exact number on this issue, but I'd wager the vast majority of the population of "educated" countries scientifically illiterate.
I - The gravity of the issue
I first got a hint that this could be a real issue when I randomly started asking people about the theory of gravity. I find gravity to be interesting because it's not at all obvious. I don't think any of us would have been able to come up with the concept in Newton's shoes. Yet it is taught to people fairly early in school.
Interestingly enough, I found that most people were not only unaware of how Newton came up with the idea of gravity, but not even in the right ballpark. I think I can classify the mistakes made into three categories, which I'll illustrate with an answer each:
1. The Science as Religion mistake: Something something, he saw apples falling towards earth, and then he wrote down the formula for gravity (?)
2. The Aristotelian Science mistake: Well, he observed that objects of different mass fell towards Earth with the same speed, and from that he derived that objects attract each other. Ahm, wait, hmmm.
3. The Lack of information mistake: Well, he observed something about the motion of the planets and the moon... and, presumably he estimated the mass of some, or, hmmm, no that can't be right, maybe he just assumed mass_sun >> mass_plant >> mass_moon and somehow he found that his formula accounted for the motion of the planets.
I should caveat this by saying I don't count mistake nr 3 as scientific illiteracy, in this case, I think most of us fall in that category most of the time. Ask me how gravity can be derived in principle and I might be able to make an educated guess and maybe (once the observations are in) I could even derive it. But the chances of that are small, I probably w
|
0a614306-a733-4261-a2ec-12d8997dde77
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Gauging of interest: LW stock picking?
EDIT: Based on criticism below, I am reconsidering how to proceed with this idea (or something in the neighbourhood).
A topic that has been on my mind recently is where, in our complicated lives, there might be low-hanging fruit ready to be picked by a motivated rationalist. Actual, practical, dollars-and-cents fruit.
In possibly-related news, here is how the writer of About.com's beginner's guide to investing describes the stock market:
> Imagine you are partners in a private business with a man named Mr. Market. Each day, he comes to your office or home and offers to buy your interest in the company or sell you his [the choice is yours]. The catch is, Mr. Market is an emotional wreck. At times, he suffers from excessive highs and at others, suicidal lows. When he is on one of his manic highs, his offering price for the business is high as well, because everything in his world at the time is cheery. His outlook for the company is wonderful, so he is only willing to sell you his stake in the company at a premium. At other times, his mood goes south and all he sees is a dismal future for the company. In fact, he is so concerned, he is willing to sell you his part of the company for far less than it is worth. All the while, the underlying value of the company may not have changed - just Mr. Market's mood.
I have heard this narrative many times before, and I'd like to test whether it is accurate - and in particular, whether LWers can consistently beat the market.
The skeptic may well ask: why should LWers have an advantage? Why not go to the professionals - investment advisors? Also, isn't there a whole chapter in Kahneman about how even smart people suck at picking stocks? And what do you, simplicio, know about this anyway?
LWers may have an advantage by virtue of being educated about such topics as cognitive biases, sunk cost fallacy, probabilistic prediction, and expected utility - topics with which investment advisors et al. may or may not be familiar on a gu
|
0c6eb876-ac82-4107-9f9e-a279dd9e0013
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Relying on Future Creativity
I used to write songs for a rock band. Sometimes I'd have a song written, thinking it was my best work ever, then when it came time to rehearse, we'd realize it wasn't going to work out. Maybe we didn't have the instruments to do it justice (we were a three piece), or it was out of my comfortable vocal range, or just too technically tricky for us to get right.
Then I'd be left with this feeling like I'd wasted my best efforts, like I couldn't ever make something that good again. And I could prove it to myself! I didn't know what song I'd write that was better than the one we'd just had to ditch!
I get the same with research. Sometimes I'll come up with an idea of the next thing I want to test, or design. Then it doesn't work, or it's not practical, or its done before. And then it's tempting to feel exactly the same way: that I've bungled my one single shot.
But I've learnt to not feel this way, and it was my song writing which helped first. Now when my idea doesn't work, my first thought isn't "oh no my idea has failed", it's "OK I guess I'll have to just have another idea". I've learnt to rely on my future creativity.
This isn't easy, and sometimes it feels like walking on air. Coming up with an idea is different from other tasks, because by definition it's different every time. When I imagine playing a piece on the piano, I know exactly the form of what I'm going to do. When I imagine coming up with an idea it's a total mental blank. If I knew where I was going I'd already be there. Creativity is also a lot less reliable than physical skills, so I often have no idea how long it's going to take me to come up with something.
There's no magic bullet, but the most important thing is getting good at noticing when you're treating your future creativity as nonexistent. The biggest sign of improvement in this skill is that you don't feel like you're stepping off a cliff every time you abandon a creative endeavour, be it idea or project.
|
dd2a9868-9a59-4da8-a222-3d12ac19cb71
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Ngo and Yudkowsky on AI capability gains
This is the second post in a series of transcribed conversations about AGI forecasting and alignment. See the first post for prefaces and more information about the format.
Color key:
Chat by Richard Ngo and Eliezer Yudkowsky Other chat Inline comments
5. September 14 conversation
5.1. Recursive self-improvement, abstractions, and miracles
[Yudkowsky][11:00]
Good morning / good evening.
So it seems like the obvious thread to pull today is your sense that I'm wrong about recursive self-improvement and consequentialism in a related way?
[Ngo][11:04]
Right. And then another potential thread (probably of secondary importance) is the question of what you mean by utility functions, and digging more into the intuitions surrounding those.
But let me start by fleshing out this RSI/consequentialism claim.
I claim that your early writings about RSI focused too much on a very powerful abstraction, of recursively applied optimisation; and too little on the ways in which even powerful abstractions like this one become a bit... let's say messier, when they interact with the real world.
In particular, I think that Paul's arguments that there will be substantial progress in AI in the leadup to a RSI-driven takeoff are pretty strong ones.
(Just so we're on the same page: to what extent did those arguments end up shifting your credences?)
[Yudkowsky][11:09]
I don't remember being shifted by Paul on this at all. I sure shifted a lot over events like Alpha Zero and the entire deep learning revolution. What does Paul say that isn't encapsulated in that update - does he furthermore claim that we're going to get fully smarter-than-human in all regards AI which doesn't cognitively scale much further either through more compute or through RSI?
[Ngo][11:10]
Ah, I see. In that case, let's just focus on the update from the deep learning revolution.
[Yudkowsky][11:12][11:13]
I'll also remark that I see my foreseeable mistake there as having little
|
d1e9570a-c9d3-47a3-94e3-36c4017116ac
|
trentmkelly/LessWrong-43k
|
LessWrong
|
How can I reduce existential risk from AI?
Suppose you think that reducing the risk of human extinction is the highest-value thing you can do. Or maybe you want to reduce "x-risk" because you're already a comfortable First-Worlder like me and so you might as well do something epic and cool, or because you like the community of people who are doing it already, or whatever.
Suppose also that you think AI is the most pressing x-risk, because (1) mitigating AI risk could mitigate all other existential risks, but not vice-versa, and because (2) AI is plausibly the first existential risk that will occur.
In that case, what should you do? How can you reduce AI x-risk?
It's complicated, but I get this question a lot, so let me try to provide some kind of answer.
Meta-work, strategy work, and direct work
When you're facing a problem and you don't know what to do about it, there are two things you can do:
1. Meta-work: Amass wealth and other resources. Build your community. Make yourself stronger. Meta-work of this sort will be useful regardless of which "direct work" interventions turn out to be useful for tackling the problem you face. Meta-work also empowers you to do strategic work.
2. Strategy work: Purchase a better strategic understanding of the problem you're facing, so you can see more clearly what should be done. Usually, this will consist of getting smart and self-critical people to honestly assess the strategic situation, build models, make predictions about the effects of different possible interventions, and so on. If done well, these analyses can shed light on which kinds of "direct work" will help you deal with the problem you're trying to solve.
When you have enough strategic insight to have discovered some interventions that you're confident will help you tackle the problem you're facing, then you can also engage in:
3. Direct work: Directly attack the problem you're facing, whether this involves technical research, political action, particular kinds of technological development, or somet
|
3c0c5fdd-d1f6-46a9-b5df-ff37abc1d011
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Is this a better way to do matchmaking?
When friends ask me to matchmake them, they usually list traits they want: "Kind, curious, growth-minded..." (Sometimes they even write date-me docs!) But I find it really hard to think of the right people from these descriptions.
Here's what I'm exploring, and suspect works better: "You know [person]? Do you know anyone kinda like them?" (Where "person" could be their ex, or that close friend they wish they were attracted to.)
Matching by description is hard. When someone lists desired traits, I need to:
1. Understand what they mean by each trait
2. Think of people I know
3. Check if they match
4. Somehow weigh everything together
But when I meet their person, I instantly get it - their vibe, how they talk, their humor, how they move through the world.
Plus, there's usually a gap between what people think they want and what works for them. Their trait list comes from trying to rationalize past attractions and guess future ones. But seeing who they've actually had chemistry with shows me what actually works.
An example also captures subtle compatibility factors they might not even be aware of. Maybe they say they want someone "growth-minded," but what they really click with is a specific style of playful intellectual banter that's hard to describe but easy to spot.
I've recently started trying to match people this way, with varying results. Would love to hear if others have successfully done this before!
I just wish I knew how to make this scalable (like, how do you do this on the internet?) or work even when you don't know the example person that well. If you have ideas, let me know!
|
f4c18e50-70f1-48a6-8069-aa4c597c2126
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Is the Star Trek Federation really incapable of building AI?
In the Star Trek universe, we are told that it’s really hard to make genuine artificial intelligence, and that Data is so special because he’s a rare example of someone having managed to create one.
But this doesn’t seem to be the best hypothesis for explaining the evidence that we’ve actually seen. Consider:
* In the TOS episode “[The Ultimate Computer](http://memory-alpha.wikia.com/wiki/The_Ultimate_Computer_(episode))“, the Federation has managed to build a computer intelligent enough to run the Enterprise by its own, but it goes crazy and Kirk has to talk it into self-destructing.
* In TNG, we find out that before Data, Doctor Noonian Soong had built Lore, an android with sophisticated emotional processing. However, Lore became essentially evil and had no problems killing people for his own benefit. Data worked better, but in order to get his behavior right, Soong had to initially build him with no emotions at all. (TNG: “[Datalore](http://memory-alpha.wikia.com/wiki/Datalore_(episode))“, “[Brothers](http://memory-alpha.wikia.com/wiki/Brothers_(episode))“)
* In the TNG episode “[Evolution](http://memory-alpha.wikia.com/wiki/Evolution_(episode))“, Wesley is doing a science project with nanotechnology, accidentally enabling the nanites to become a collective intelligence which almost takes over the ship before the crew manages to negotiate a peaceful solution with them.
* The holodeck seems entirely capable of running generally intelligent characters, though their behavior is usually restricted to specific roles. However, on occasion they have started straying outside their normal parameters, to the point of attempting to take over the ship. (TNG: “[Elementary, Dear Data](http://memory-alpha.wikia.com/wiki/Elementary,_Dear_Data_(episode))“) It is also suggested that the computer is capable of running an indefinitely long simulation which is good enough to make an intelligent being believe in it being the real universe. (TNG: “[Ship in a Bottle](http://memory-alpha.wikia.com/wiki/Ship_in_a_Bottle_(episode))“)
* The ship’s computer in most of the series seems like it’s potentially quite intelligent, but most of the intelligence isn’t used for anything else than running holographic characters.
* In the TNG episode “[Booby Trap](http://memory-alpha.wikia.com/wiki/Booby_Trap_(episode))“, a potential way of saving the Enterprise from the Disaster Of The Week would involve turning over control of the ship to the computer: however, the characters are inexplicably super-reluctant to do this.
* In Voyager, the Emergency Medical Hologram clearly has general intelligence: however, it is only supposed to be used in emergency situations rather than running long-term, its memory starting to degrade after a sufficiently long time of continuous use. The recommended solution is to reset it, removing all of the accumulated memories since its first activation. (VOY: “[The Swarm](http://memory-alpha.wikia.com/wiki/The_Swarm_(episode))“)
There seems to be a pattern here: if an AI is built to carry out a relatively restricted role, then things work fine. However, once it is given broad autonomy and it gets to do open-ended learning, there’s a very high chance that it gets out of control. The Federation witnessed this for the first time with the Ultimate Computer. Since then, they have been ensuring that all of their AI systems are restricted to narrow tasks or that they’ll only run for a short time in an emergency, to avoid things getting out of hand. Of course, this doesn’t change the fact that your AI having more intelligence is generally useful, so e.g. starship computers are equipped with powerful general intelligence capabilities, which sometimes do get out of hand.
Dr. Soong’s achievement with Data was not in building a general intelligence, but in building a general intelligence which didn’t go crazy. (And before Data, he failed at that task once, with Lore.)
The Federation’s issue with AI is not that they haven’t solved artificial general intelligence. The Federation’s issue is that they haven’t reliably solved the [AI alignment problem](https://intelligence.org/2016/12/28/ai-alignment-why-its-hard-and-where-to-start/).
|
c151bd5c-da8c-40fc-83d4-6b041ddba1e3
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Some Thoughts on Singularity Strategies
Followup to: Outline of possible Singularity scenarios (that are not completely disastrous)
Given that the Singularity and being strategic are popular topics around here, it's surprising there hasn't been more discussion on how to answer the question "In what direction should we nudge the future, to maximize the chances and impact of a positive Singularity?" ("We" meaning the SIAI/FHI/LW/Singularitarian community.)
(Is this an appropriate way to frame the question? It's how I would instinctively frame the question, but perhaps we ought to discussed alternatives first. For example, one might be "What quest should we embark upon to save the world?", which seems to be the frame that Eliezer instinctively prefers. But I worry that thinking in terms of "quest" favors the part of the brain that is built mainly for signaling instead of planning. Another alternative would be "What strategy maximizes expect utility?" but that seems too technical for human minds to grasp on an intuitive level, and we don't have the tools to answer the question formally.)
Let's start by assuming that humanity will want to build at least one Friendly superintelligence sooner or later, either from scratch, or by improving human minds, because without such an entity, it's likely that eventually either a superintelligent, non-Friendly entity will arise, or civilization will collapse. The current state of affairs, in which there is no intelligence greater than baseline-human level, seems unlikely to be stable over the billions of years of the universe's remaining life. (Nor does that seem particularly desirable even if it is possible.)
Whether to push for (or personally head towards) de novo AI directly, or IA/uploading first, depends heavily on the expected (or more generally, subjective probability distribution of) difficulty of building a Friendly AI from scratch, which in turn involves a great deal of logical and philosophical uncertainty. (For example, if it's known that it actually takes
|
f0d1ebc5-4889-4733-93c9-2c8eee255c4e
|
StampyAI/alignment-research-dataset/arbital
|
Arbital
|
Immediate goods
One of the potential views on 'value' in the value alignment problem is that what we should want from an AI is a list of immediate goods or outcome features like 'a cure for cancer' or 'letting humans make their own decisions' or 'preventing the world from being wiped out by a paperclip maximizer'. (Immediate Goods as a criterion of 'value' isn't the same as saying we should give the AI those explicit goals; calling such a list 'value' means it's the real criterion by which we should judge how well the AI did.)
# Arguments
## Immaturity of view deduced from presence of instrumental goods
It seems understandable that Immediate Goods would be a very common form of expressed want when people first consider the [value alignment problem](https://arbital.com/p/2v); they would look for valuable things an AI could do.
But such a quickly produced list of expressed wants will often include [instrumental goods](https://arbital.com/p/) rather than [terminal goods](https://arbital.com/p/). For example, a cancer cure is (presumably) a means to the end of healthier or happier humans, which would then be the actual grounds on which the AI's real-world 'value' was evaluated from the human speaker's standpoint. If the AI 'cured cancer' in some technical sense that didn't make people healthier, the original person making the wish would probably not see the AI as having achieved value.
This is a reason for suspecting the maturity of such expressed views, and to suspect that the stated list of immediate goods will probably evolve into a more [terminal](https://arbital.com/p/) view of value from a human standpoint, given further reflection.
### Mootness of immaturity
Irrespective of the above, so far as technical issues like [Edge Instantiation](https://arbital.com/p/2w) are concerned, the 'value' variable could still apply to someone's spontaneously produced list of immediate wants, and that all the standard consequences of the value alignment problem usually still apply. It means we can immediately say (honestly) that e.g. [Edge Instantiation](https://arbital.com/p/2w) would be a problem for whatever want the speaker just expressed, without needing to persuade them to some other stance on 'value' first. Since the same technical problems will apply both to the immature view and to the expected mature view, we don't need to dispute the view of 'value' in order to take it at face value and honestly explain the standard technical issues that would still apply.
## Moral imposition of short horizons
Arguably, a list of immediate goods may make some sense as a stopping-place for evaluating the performance of the AI, if either of the following conditions obtain:
- There is much more agreement (among project sponsors or humans generally) about the goodness of the instrumental goods, than there is about the terminal values that make them good. E.g., twenty project sponsors can all agree that freedom is good, but have nonoverlapping concepts about why it is good, and it is hypothetically the case that these people would continue to disagree in the limit of indefinite debate or reflection. Then if we want to collectivize 'value' from the standpoint of the project sponsors for purposes of talking about whether the AI methodology achieves 'value', maybe it would just make sense to talk about how much (intuitively evaluated) freedom the AI creates.
- It is in some sense morally incumbent upon humanity to do its own thinking about long-term outcomes and achieve them through immediate goods, or it is in some sense morally incumbent for humanity to arrive at long-term outcomes via its own decisions or optimization starting from immediate goods. In this case, it might make sense to see the 'value' of the AI as being realized only in terms of the AI getting to those immediate goods, because it would be morally wrong for there to be optimization by the AI of consequences beyond that.
To the knowledge of [https://arbital.com/p/2](https://arbital.com/p/2) as of May 2015, neither of these views have yet been advocated by anyone in particular as a defense of an immediate-goods theory of value.
|
552fd40b-57b0-4a71-86cc-4239a2a55c86
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Moscow: Words of estimative probability, transparency illusion, belief investigation, rational games
Discussion article for the meetup : Moscow: Words of estimative probability, transparency illusion, belief investigation, rational games
WHEN: 26 June 2016 02:00:00PM (+0300)
WHERE: Москва, ул. Большая Дорогомиловская, 5к2
Note: most our members join meetups via other channels. Still, the correlation between "found out about Moscow meetups via lesswrong.com" and "is a great fit for our community" is very high. So we're posting just a short link to the hackpad document with the schedule here instead of the full translation of the announcement into English.
Pad with the details about 26.06.2016 meetup.
We're meeting at the "Kocherga" anticafe, as usual.
Discussion article for the meetup : Moscow: Words of estimative probability, transparency illusion, belief investigation, rational games
|
905c3560-ee9b-4e31-9e81-eafceab5f204
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Anthropic Paradoxes and Self Reference
In this post I will explain how anthropic paradoxes are connected with self-reference.
Sleeping Beauty Problem
The contention is how to treat the fact that "I am awake now/today". To briefly summarize the debate at the cost of oversimplification: SIA suggests treating today as a random sample of all days. While SSA suggests treating today as a random sample of all awakening days in the experiment. This debate can be considered as the dispute over the correct way of interpreting/defining today.
It should be noted the direct use of the word "today" is not necessary. For example, in Technicolor Beauty due to Titelbaum, the experimenter would randomly pick a day and paint the room blue and paint the room red the other day. Say I wake up and sees the room is blue. How should I consider the fact that "The blue day has an awakening?". Here the direct reference is averted yet the problem remains the same. i.e. blue day is being asked only because that's what I'm seeing now.
Doomsday Argument
The doomsday argument essentially says, considering myself as a random sample from all humans (SSA), then I am more likely to have my current birth rank if the total number of humans is low. This should shift my forecast of the species' future towards "doom soon". The SIA counter-argument suggests I shall regard myself to be a random sample from all observers that could potentially exist. Then I actually do exist (as a human) is evidence that favors a higher number of humans. It exactly cancels out the pessimistic shift due to my birth rank.
The debate is about the correct way to define myself. Again, a direct reference to "myself" is not necessary. Often the argument is presented with wordings such as "us", "the current generation", or even "people in 2021". Yet the argument remains the same because those wordings are chosen because that's what you and I (the people discussing this problem) are.
Fine-Tuning Argument
Fine-tuning is the idea that the existence of life in t
|
216bab80-921a-469f-9dfb-1c5e490b2036
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why I hang out at LessWrong and why you should check-in there every now and then
As the title indicates, this post, which in cross-posting from my home blog, New Savanna, is not directed at a LessWrong audience. However,, some of you might find in useful in thinking about LessWrong's place in the world.
The first two sections are a background, first a bit on cultural change to set the general context. Then some general information about LessWrong. Now we’re reading for my personal impressions of the place, concluding with a suggestion that you take a look if you haven’t already.
Cultural change over the long haul: Christians and professors
Back in the ancient days Christianity as just another mystery cult on the periphery of the Roman Empire. Then in 380 AD Emperor Theodosius I issued the Edict of Thessalonica and it became the state religion of the Roman Empire. In time it spread out among the many tribes of Europe and those Christian tribespeople began thinking of an entity called Christendom, and that, in time, became Europe and “the West.”
Back in the days when Europe was still Christendom the Catholic Church was the center of intellectual life. That changed during the Sixteenth Century with the advent of the Scientific Revolution and the Reformation. The Catholic remained powerful, of course, but universities supplanted it as the institutional center of intellectual life.
My point is simple and obvious: things change. Cults can become mainstream and new institutions can displace old ones. With that in mind, let’s think about LessWrong.
LessWrong
To be sure do not want to imply that LessWrong, a large and sophisticated online community, and the currents that swirl there (the rationalist movement, effective altruism (EA), dystopian fears of rogue AI) is comparable to Christianity, but it appears cultlike to outsiders, and to some insiders as well. It hosts a great deal of high-wattage intellectual activity on artificial intelligence and AI existential risk, effective altruism, and, more generally, how to live a life. I suspect that for
|
389a2729-9e99-49cd-817a-daf8f4da90b3
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[LINK] How Do Top Students Study?
I found this Quora discussion very informative.
> 2. Develop the ability to become an active reader. Don't just passively read material you are given. But pose questions, develop hypotheses and actively test them as you read through the material. I think this is what another poster referred to when he advised that you should develop a "mental model" of whatever concept they are teaching you. Having a mental model will give you the intuition and ability to answer a wider range of questions than would be otherwise possible if you lacked such a mental model.
> Where do you get this model? You creatively develop one as you are reading to try to explain the facts as they are presented to you. Sometimes you have to guess the model based on scarce evidence. Sometimes it is handed to you. If your model is a good one it should at least be able to explain what you are reading.
>
> Having a model also tells you what to look for to disprove it -- so you can be hypersensitive for this disconfirming evidence. In fact, while you are reading you should be making predictions (in the form of one or more scenarios of where the narrative could lead) and carefully checking if the narrative is going there. You should also be making predictions and seeking contradictions to these predictions -- so you can quickly find out if your model is wrong.
>
> Sometimes you may have two or more different models that can explain the evidence, so you task will be to quickly formulate questions that can prove one model while disconfirming the others. I suggest focusing on raising questions that could confirm/disprove the mostly likely one while disproving the others (think: differential diagnoses in medicine).
>
> But once you have such a model that (i) explains the evidence and (ii) passes all the disconfirming tests you can throw at it then you have something you can interpolate and extrapolate from to answer far more than was initially explained to you.
>
> Such models also makes retention easi
|
fd753063-e56d-4827-b873-edcee3f50ad8
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Lesswrong Meetup in Barcelona?
Perhaps the Spaniard and/or Catalan tropers, and those others who simply feel like visiting this wonderful city that is Barcelona, could meet here during Semana Santa, the Spanish Spring Break, which lasts from April 15 to April 24. We could decide on a date within that interval. I'm not trying to compete with Paris or anything, but it's really one of the most convenient times in the year for such an event to take place.
Don't expect any Ku Klux Klan lookalikes though, Catalonia just doesn't do that.
|
f339f611-ec6d-4e5a-8262-edfefc17cdcf
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Hypothesis: gradient descent prefers general circuits
Summary: I discuss a potential mechanistic explanation for why SGD might prefer general circuits for generating model outputs. I use this preference to explain how models can learn to generalize even after overfitting to near zero training error (i.e., grokking). I also discuss other perspectives on grokking and deep learning generalization.
Additionally, I discuss potential experiments to confirm or reject my hypothesis. I suggest that a tendency to unify many shallow patterns into fewer general patterns is a core feature of effective learning systems, potentially including humans and future AI, and briefly address implications to AI alignment.
Epistemic status: I think the hypothesis I present makes a lot of sense and is probably true, but I haven't confirmed things experimentally. Much of my motive for post this is to clarify my own thinking and get feedback on the best ways to experimentally validate this perspective on ML generalization.
Context about circuits: This post assumes the reader is familiar with and accepts the circuits perspective on deep learning. See here for a discussion of circuits for CNN vision models and here for a discussion of circuits for transformer NLP models.
Evidence from grokking
The paper "Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets" uses stochastic gradient descent (SGD) to train self attention based deep learning models on different modular arithmetic expressions (e.g., f(x,y)=x×y (mod p), where p is fixed).
The training data only contain subsets of the function's possible input/output pairs. Initially, the models overfit to their training data and are unable to generalize to the validation input/output pairs. In fact, the models quickly reach near perfect accuracy on their training data. However, training the model for significantly past the point of overfitting causes the model to generalize to the validation data, what the authors call "grokking".
See figure 1a from the paper:
Figure 1a fro
|
afb1a12d-abae-41f0-8089-1a3093ab37a6
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[SEQ RERUN] Doublethink (Choosing to be Biased)
Today's post, Doublethink (Choosing to be Biased) was originally published on 14 September 2007. A summary :
> George Orwell wrote about what he called "doublethink", where a person was able to hold two contradictory thoughts in their mind simultaneously. While some argue that self deception can make you happier, doublethink will actually lead only to problems.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Human Evil and Muddled Thinking, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series.
|
eff868d1-8329-4ce0-8e5c-d9b3910f5336
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Make an Extraordinary Effort
> "It is essential for a man to strive with all his heart, and to understand that it is difficult even to reach the average if he does not have the intention of surpassing others in whatever he does."
> —Budo Shoshinshu
>
> "In important matters, a 'strong' effort usually results in only mediocre results. Whenever we are attempting anything truly worthwhile our effort must be as if our life is at stake, just as if we were under a physical attack! It is this extraordinary effort—an effort that drives us beyond what we thought we were capable of—that ensures victory in battle and success in life's endeavors."
> —Flashing Steel: Mastering Eishin-Ryu Swordsmanship
"A 'strong' effort usually results in only mediocre results"—I have seen this over and over again. The slightest effort suffices to convince ourselves that we have done our best.
There is a level beyond the virtue of tsuyoku naritai ("I want to become stronger"). Isshoukenmei was originally the loyalty that a samurai offered in return for his position, containing characters for "life" and "land". The term evolved to mean "make a desperate effort": Try your hardest, your utmost, as if your life were at stake. It was part of the gestalt of bushido, which was not reserved only for fighting. I've run across variant forms issho kenmei and isshou kenmei; one source indicates that the former indicates an all-out effort on some single point, whereas the latter indicates a lifelong effort.
I try not to praise the East too much, because there's a tremendous selectivity in which parts of Eastern culture the West gets to hear about. But on some points, at least, Japan's culture scores higher than America's. Having a handy compact phrase for "make a desperate all-out effort as if your own life were at stake" is one of those points. It's the sort of thing a Japanese parent might say to a student before exams—but don't think it's cheap hypocrisy, like it would be if an American parent made the
|
495d4a11-a50b-4b97-b336-212a8e934982
|
trentmkelly/LessWrong-43k
|
LessWrong
|
MIRI's 2017 Fundraiser
Update 2017-12-27: We've blown past our 3rd and final target, and reached the matching cap of $300,000 for the $2 million Matching Challenge! Thanks so much to everyone who supported us!
All donations made before 23:59 PST on Dec 31st will continue to be counted towards our fundraiser total. The fundraiser total includes projected matching funds from the Challenge.
----------------------------------------
MIRI’s 2017 fundraiser is live through the end of December! Our progress so far (updated live):
----------------------------------------
Donate Now
----------------------------------------
MIRI is a research nonprofit based in Berkeley, California with a mission of ensuring that smarter-than-human AI technology has a positive impact on the world. You can learn more about our work at “Why AI Safety?” or via MIRI Executive Director Nate Soares’ Google talk on AI alignment.
In 2015, we discussed our interest in potentially branching out to explore multiple research programs simultaneously once we could support a larger team. Following recent changes to our overall picture of the strategic landscape, we’re now moving ahead on that goal and starting to explore new research directions while also continuing to push on our agent foundations agenda. For more on our new views, see “There’s No Fire Alarm for Artificial General Intelligence” and our 2017 strategic update. We plan to expand on our relevant strategic thinking more in the coming weeks.
Our expanded research focus means that our research team can potentially grow big, and grow fast. Our current goal is to hire around ten new research staff over the next two years, mostly software engineers. If we succeed, our point estimate is that our 2018 budget will be $2.8M and our 2019 budget will be $3.5M, up from roughly $1.9M in 2017.1
We’ve set our fundraiser targets by estimating how quickly we could grow while maintaining a 1.5-year runway, on the simplifying assumption that about 1/3 of the dona
|
277fc8d4-c324-4b53-a9a3-612175ec9282
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Paper: In-context Reinforcement Learning with Algorithm Distillation [Deepmind]
Authors train transformers to imitate the trajectory of reinforcement learning (RL) algorithms. Find that the transformers learn to do in-context RL (that is, the transformers implement an RL algorithm)---the authors check this by having the transformers solve new RL tasks. Indeed, the transformers can sometimes do better than the RL algorithms they're trained to imitate.
Seems like more evidence for the "a generative model contain agents" point.
Abstract:
> We propose Algorithm Distillation (AD), a method for distilling reinforcement learning (RL) algorithms into neural networks by modeling their training histories with a causal sequence model. Algorithm Distillation treats learning to reinforcement learn as an across-episode sequential prediction problem. A dataset of learning histories is generated by a source RL algorithm, and then a causal transformer is trained by autoregressively predicting actions given their preceding learning histories as context. Unlike sequential policy prediction architectures that distill post-learning or expert sequences, AD is able to improve its policy entirely in-context without updating its network parameters. We demonstrate that AD can reinforcement learn in-context in a variety of environments with sparse rewards, combinatorial task structure, and pixel-based observations, and find that AD learns a more data-efficient RL algorithm than the one that generated the source data.
|
aa170321-19b4-4876-998b-f744d6f41f02
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why are the websites of major companies so bad at core functionality?
Intuitively, you might think that Amazon cares about people being able to enter their banking details as easily as possible. In reality at least Amazon.de doesn't seem to care. Instead of instantly validating with Javascript that a entered IBAN is valid the form waits with giving feedback till the user clicks okay.
I just used Uber the first time and the task of entering street addresses is awful.
1. There's no autocomplete for street names that allows me to add the street number.
2. Berlin is a big city, yet the first hits in the list that was proposed are streets with the same name in other cities.
3. The suggestions that Uber gives don't include postal code which are important because multiple streets in Berlin share the same street names
4. There seems to be no obvious way to select a street name and then choose on a map where on the street you want to be picked up. After a bit of searching I do find that I can click on the street name for pickup but the touchable area is very small and could be easily expanded into the empty whitespace above. For the destination it still seems like there's no to add more details to the automated street name
5. If I write the name of a contact (in my contacts) then I don't get the address shown
How does it come that those companies employ 1000s of software developers yet manage to do badly on the task of providing basic functions to users? What are all those engineers doing?
|
9c395b47-fc8a-40cf-b7d0-d6a5859eef65
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Might humans not be the most intelligent animals?
The idea that humans are the most intelligent animals on Earth appears patently obvious to a lot of people. And to a large extent, I agree with this intuition. Humans clearly dominate the world in technological innovation, control, communication, and coordination.
However, more recently I have been acquainted with some evidence that the proposition is not actually true, or at the very least is non-obvious. The conundrum arises when we distinguish raw innovative capability, from the ability to efficiently process culture. I'll explain the basic case here.
Robin Hanson has sometimes pointed to the accumulation of culture as the relevant separation between humans and other animals. Under this view, the reason why humans are able to dominate the world with technology has less to due with our raw innovation abilities, and more to do with the fact that we can efficiently process accumulated cultural information and build on it.
If the reason for our technological dominance is due to raw innovative ability, we might expect a more discontinuous jump in capabilities for AI, since there was a sharp change between "unable to innovate" and "able to innovate" during evolutionary history, which might have been due to some key architectural tweak. We might therefore expect that our AIs will experience the same jump after receiving the same tweak.
If the reason for our technological dominance is due to our ability to process culture, however, then the case for a discontinuous jump in capabilities is weaker. This is because our AI systems can already process culture somewhat efficiently right now (see GPT-2) and there doesn't seem like a hard separation between "being able to process culture inefficiently" and "able to process culture efficiently" other than the initial jump from not being able to do it at all, which we have already passed. Therefore, our current systems are currently bottlenecked on some metric which is more continuous.
The evidence for the cultural accumulati
|
e242219e-71e0-4b10-b52b-1b1ea091a5f8
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[Productivity] How not to use "Important // Not Urgent"
Epistemic status: Personal experience.
This is an Eisenhower matrix, named after President Dwight Eisenhower.
Eisenhower matrices have a very useful, very specific role in my life these days.
I usually bust one out on paper when I'm feeling overwhelmed by my own anxiety, and use it to focus my attention on what's in the first quadrant. I tell myself that I'll return to it by the time I finish the first quadrant, but usually by the time I've actually filled that quadrant out, my panic has subsided completely and I feel no issues in discarding the 2x2.
For a while, I also used the Eisenhower matrix as the basis for my Todoist Premium workflow. I actually still think that's a pretty good system for someone just getting started with using Todoist, and wanting a little bit more structure with how to use it outside of the box.
But I noticed that often, I would add things that I wanted to do way out in the future to the "Important // Not Urgent" filter. This is a bad idea, because economics tells us that ideas of things you want to do in the far future should probably be discounted quite heavily, relative to things you want to do in maybe the next month or so. You might well find that 5 years from now, you don't give a shit about learning to play Vivaldi or looking into moving to a different place; those are all things you can leave as amorphous ideas to play around with in your mind.
So my advice: Don't use the Urgent // Not Important quadrant for anything that isn't due more than two weeks out. That's a pretty aggressive cutoff point, yes, but we're talking planning your personal life here, not business; and we're talking a tool meant to focus your executive function in good directions. You don't want to overstretch it.
One objection that I could forsee someone saying is, "Well, what if I have a recurring task that I want to do every day, but it doesn't pay off immediately for me?", to which I say, the todo list is usually a fundamentally bad format for that, beca
|
dc9769b3-e837-4fe3-8e07-c97a95f2562e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
I think Michael Bailey's dismissal of my autogynephilia questions for Scott Alexander and Aella makes very little sense
I am autogynephilic, and there's been a lot of autogynephilia talk lately. One subject that sometimes comes up, but hasn't been discussed much on LessWrong, is how common autogynephilia is in cis women.
Two datasets that are sometimes used for this question are Scott Alexander's and Aella's. Part of how they happened to be made is that I reached out to Scott and Aella, suggesting experimental questions for assessing autogynephilia, in ways that might function in cis women too and not just cis men[1]:
* Picture a very beautiful woman. How sexually arousing would you find it to imagine being her?
* Do you find the thought of masturbating alone as a woman to be erotic?
This is somewhat different from usual autogynephilia measures, which contain questions such as:
* Did you ever feel sexually aroused when putting on females' underwear or clothing?
* Have you ever become sexually aroused while picturing your nude female breasts?
The reason I didn't include these latter questions is because it seems likely to me that they will be interpreted differently for males and females (e.g. if males do not have female anatomy, then they cannot be aroused by it literally, so instead they get aroused by imagining some other female anatomy that they don't actually have), and because these usual questions seem very bad if taken literally ("ever" and "while" rather than "how frequently" and "by" seem like there could be a lot of ways to get affirmative answers while not actually being autogynephilic - though the low rate of endorsement among women suggests to me that they are not taking it literally?).
Anyway, Michael Bailey (activist researcher for autogynephilia ideology) responds in Aporia Magazine, saying "It's important not to confound y'know being seen as a woman or having a female body from having sex with a partner while having a female body or the prospect of going out on a date while wearing sexy clothes".
I don't think this makes any sense. "Do you find the thought
|
c87bfa9f-8304-4d0e-921e-1057f59c4138
|
trentmkelly/LessWrong-43k
|
LessWrong
|
LLM Basics: Embedding Spaces - Transformer Token Vectors Are Not Points in Space
This post is written as an explanation of a misconception I had with transformer embedding when I was getting started. Thanks to Stephen Fowler for the discussion last August that made me realise the misconception, and others for helping me refine my explanation. Any mistakes are my own. Thanks to feedback by Stephen Fowler and JustisMills on this post.
TL;DR: While the token vectors are stored as n-dimensional vectors, thinking of them as points in vector space can be quite misleading. It is better to think of them as directions on a hypersphere, with a size component.
The I think of distance as the Euclidean distance, with formula:
d(→x1,→x2)=|→x1−→x2|=√∑i(x1i−x2i)2
Thus does not match up with the distance forumla used when calculating logits:
d(→x1,→x2)=→x1⋅→x2=|→x1||→x2|cosθ12
But it does match up with the cosine similarity forumula:
d(→x1,→x2)=^x1⋅^x2=cosθ12
And so, we can see that the direction and size matter, but not the distance
Introduction
In the study of transformers, it is often assumed that different tokens are embedded as points in a multi-dimensional space. While this concept is partially true, the space in which these tokens are embedded is not a traditional Euclidean space. This is because of the way probabilities of tokens are calculated, as well as how the behaviour of the softmax function affects how tokens are positioned in their space.
This post will have two parts. In the first part, I will briefly explain the relevant parts of the transformer, and in the second part, we will explore what is happening when a transformer moves from an input token to an output token explaining why tokens are better thought of as directions.
Part 1: The Process of a Transformer
Here I will briefly describe how the relevant parts of the transformer work.
First, let's briefly explain the relevant parts at the start of the transformer. We will be studying the "causal" transformer model (ie: that given N tokens, we want to predict the (N+1)th token). T
|
31ade82f-570e-4d98-9450-e40efdaab1d8
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[LINK] The Mathematics of Gamification - Application of Bayes Rule to Voting
Fresh from slashdot: A smart application of Bayes' rule to web-voting.
http://engineering.foursquare.com/2014/01/03/the-mathematics-of-gamification/
> [The results] are exactly the equations for voting you would expect. But now, they’re derived from math!
> The Benefits
>
> * Efficient, data-driven guarantees about database accuracy. By choosing the points based on a user’s accuracy, we can intelligently accrue certainty about a proposed update and stop the voting process as soon as the math guarantees the required certainty.
> * Still using points, just smart about calculating them. By relating a user’s accuracy and the certainty threshold needed to accept a proposed update to an additive point system (2), we can still give a user the points that they like. This also makes it easy to take a system of ad-hoc points and convert it over to a smarter system based on empirical evidence.
> * Scalable and easily extensible. The parameters are automatically trained and can adapt to changes in the behavior of the userbase. No more long meetings debating how many points to grant to a narrow use case.
> So far, we’ve taken a very user-centric view of pk (this is the accuracy of user k). But we can go well beyond that. For example, pk could be “the accuracy of user k’s vote given that they have been to the venue three times before and work nearby.” These clauses can be arbitrarily complicated and estimated from a (logistic) regression of the honeypot performance. The point is that these changes will be based on data and not subjective judgments of how many “points” a user or situation should get.
I wonder whether and how this could be applied to voting here as LW posts are not 'correct' per se.
One rather theoretical possibility would be to assign prior correctness to some posts e.g. the sequences and then use that to determine the 'accuracy' of users based on that.
|
c89f71b6-a023-4ad4-98a6-f6b33ca4fe2f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
How accurate was my "Altered Traits" book review?
4.4 years ago, I posted a review of Altered Traits, a book about the science of meditation. At the time, I was a noob. I hadn't hit any important checkpoints yet. Since then, I have sat quietly. In this post, I will review whether the claims in my original post are consistent with my subsequent lived experience.
> The first thing the authors do is confirm that a compassionate attitude actually increases altruistic behavior. It does.
While this may be true, I think the reverse is more important. Altruistic behavior increases compassion. More generally, acting non-compassionately is an obstacle to insight. In this way, mystic practice is intimately intertwined with morality.
> Compassion increases joy and happiness too.
Directionally true, with a qualifier. There are many mental states that feel better than joy and happiness. "Compassion makes you feel better" is true, but feeling better may not precisely coincide with joy and happiness. Is absolute zero "ice cold"?
> [T]hey can investigate whether meditation produces longterm increases in compassion.
Yes. Longterm meditation increases compassion, with the qualifier that the meditation must be done correctly.
> One form of lovingkindness meditation starts by cultivating compassion for the people close to you and then gradually widening the ingroup until it includes everyone―including your enemies. Does this practice help reduce hatred?
It's not just lovingkindness meditation that reduces hatred. Non-dual meditation does too, because hatred is predicated on a self-other separation.
> > [T]hree of the most "advanced" monks…[brains'] responded as strongly to the twentieth sound as to the first. This was big news: ordinarily the brain would tune out, showing no reaction to the tenth bing, let alone the twentieth.
>
> This constitutes objective external verification of my own and others' subjective experiences in zendo. It makes total sense if you are familiar with Zen and it is strong evidence that meditation ma
|
d838a074-cebe-44cd-8531-2da1b605795c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Madison: Rough Numbers
Discussion article for the meetup : Madison: Rough Numbers
WHEN: 22 July 2012 07:00:00PM (-0500)
WHERE: 302 S Mills St, Apt 5, Madison, WI
Note: If it's convenient, and you have a smartphone, laptop, or tablet, bring it. We'll want to be able to all look up data efficiently, and I want some folks to run races against calculators. :)
I have a whole slew of stuff I'd like to talk about, and possibly even some things to test.
Short topics we'll cover:
* Fermi problems: How to get rough numbers for things you're interested in, without actually knowing much hard data.
* Fast mental math: How to compute Fermi estimates in your head, quickly.
* Value of information: How to estimate when doing more work to find more information is likely to be useful.
Some tests/experiments/kind-of-games I'd like to try:
* Is fast mental math actually useful if you have a glowing rectangle handy? I suspect it is, and will happily race some calculators to see if it is so.
* In what situations do Fermi estimates even make sense? Do we have questions that are actually better answered with roughly-guessed numbers, rather than data from the nearest source of internet?
Discussion article for the meetup : Madison: Rough Numbers
|
6a1b8bfd-d68b-4cc0-8fe8-a6f03a036355
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[SEQ RERUN] Sorting Pebbles Into Correct Heaps
Today's post, Sorting Pebbles Into Correct Heaps was originally published on 10 August 2008. A summary (taken from the LW wiki):
> A parable about an imaginary society that don't understand what their values actually are.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Inseparably Right; or, Joy in the Merely Good, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series.
|
5c748bbb-422a-4f13-a32d-b5f669969c69
|
StampyAI/alignment-research-dataset/special_docs
|
Other
|
CHAI Newsletter 2018
5/4/22, 2:39 PM Center for Human-Compatible AI (CHAI) Newsletter
https://mailchi.mp/c8b632a14601/center -for-human-compatible-ai-chai-newsletter 1/4Congratulations to our 2017 & 2018 Intern
Cohorts
"Interning at CHAI has been one of those rare experiences that makes you
question beliefs you didn't realize were there to be questioned... I'm coming
away with a very different view on what kind of research is valuable and
where the field of safety research currently stands" - Matthew Rahtz
Congratulations to our two previous cohorts of CHAI interns who spent a
semester not only learning more about AI safety , but also set themselves up for
amazing future opportunities.
Each intern had the opportunity to pursue their own research project, with one
of our PhD students as a mentor to give them advice, seeing them through from
the beginning of their project all the way to publication. Our interns also
received experience in handling large projects, deep RL, attending seminars
and lectures by some of the world's leading AI experts, and getting a taste for
what a PhD program would look like.
We would like to wish our best luck to our interns who are now moving on to
new projects. For example, Beth Barnes has accepted a position at DeepMind,
and Chris Cundy joined Stanford's AI lab as a PhD student. Our other previous
interns include: Dmitrii Krasheninnikov , Aaron David T ucker , Alex T urner ,
James Drain , Jordan Alexander , Matthew Rahtz , and Steven W ang.
If this experience sounds like something you or someone you know would be
interested in, then consider joining our team as an intern and send an
application before our deadline on December 21st.
5/4/22, 2:39 PM Center for Human-Compatible AI (CHAI) Newsletter
https://mailchi.mp/c8b632a14601/center -for-human-compatible-ai-chai-newsletter 2/4News
CHAI Co-Sponsored the talk Guardians, Aliens, or Robot Overlords?
Security in the Age of Artificial Intelligence
Professor Edward Felten, a specialist in computer science, public policy, and
Deputy CT O of the Unites States in the Obama White House , gave a talk on the
security implications of arti�cial intelligence. To learn more, you can read the
Institute of International Studies' page on the event and watch the lecture here.
Rosie Campbell, CHAI Assistant Director , has been named one of the
hundred women in AI ethics to follow on social media
Rosie was named by influential technology blogger Mia Dand in one of her
recent posts. She was also invited to do a fireside chat about AI ethics by the
author of the article; details in the events section below . You can read about it
more in the article here.
Peter Abbeel and Anca Dragan presented a paper at IROS 2018
Two CHAI co-PIs attended the 2018 International Conference on Intelligent
Robots and Systems in Madrid, Spain to present their paper Establishing
Appropriate T rust via Critical States . The paper discusses how humans can
develop reliable mental models of how robotic systems in certain situations
where actions need to be taken by showing humans what they
understand. Their paper can be accessed on ArXiv here.
Co-PI Anca Dragan attended the Conference on Robot Learning with PhD
student Jaime Fisac
The two presented a paper at the 2018 Conference on Robot Learning,
which took place October 29th-31st, 2018, in Zürich, Switzerland. Their paper is
titled Learning under Misspecified Objective Spaces , is on trying to make robots
learn to correct their objectives based on human input in a way that the robot
considers if the humans correction applies to their space of hypotheses. The
paper can be accessed on ArXiv here.
A paper by Professor Stuart Russell, PhD student Adam Gleave, and
intern Aaron T ucker has been accepted at the NIPS DeepRL workshop
Head PI Professor Stuart Russell, Adam Gleave, and Aaron T ucker worked
together to submit a paper to the NIPS DeepRL W orkshop, which will take
place December 2nd-8th, 2018 in Palais des Congrès de Montréal, Canada.
Their paper is titled Inverse reinforcement learning for video games, and is on
how an adversarial inverse reinforcement learning algorithm can be used in a
5/4/22, 2:39 PM Center for Human-Compatible AI (CHAI) Newsletter
https://mailchi.mp/c8b632a14601/center -for-human-compatible-ai-chai-newsletter 3/4video game to find the objective function for a behavior , as opposed to a
programmer trying to create an objective function that describes a behavior .
The paper can be accessed on ArXiv here.
Interested in staying on top of the latest in AI safety research? Make sure
to sign up for Rohin Shah's Alignment Newsletter .
Events
Join Assistant-Director Rosie
Campbell for a �reside chat on
keeping AI safe and bene�cial for
humanity. The talk will be hosted by
Mia Dand and will take place in
Berkeley, CA on November 28th.
Click here to RSVP for the event.
Vacancies
Machine Learning Engineer Specializing in AI Safety and Control
We're looking for a ML engineer to help with research projects by CHAI faculty
everywhere from UC Berkeley , to MIT , to Cambridge. Successful candidates
will be given a visiting research scholar position and have the opportunity to
help shape the CHAI research agenda.
Postdoc Specializing in AI Safety and Control
We're looking for someone with a PhD to work with Stuart Russell or one of the
other co-principle investigators at CHAI. Successful candidates do not need
prior research in AI safety , and will have a considerable degree of flexibility in
exploring novel research projects.
Research Internship at CHAI
We're of fering research internships at CHAI for undergrads and people with
technical experience wanting to transition into AI safety research. Experience in
a technical field such as machine learning, computer science, statistics, or
mathematics is required. These internships are held over the summer , and the
5/4/22, 2:39 PM Center for Human-Compatible AI (CHAI) Newsletter
https://mailchi.mp/c8b632a14601/center -for-human-compatible-ai-chai-newsletter 4/4first round of applications will be due on December 21st.
For more information or to apply , please visit the CHAI website
To see more, visit us at humancompatible.ai
Copyright © 2018 Center for Human-Compatible AI, All rights reserved.
Want to change how you receive these emails?
You can update your preferences or unsubscribe from this list .
This email was sent to <<Email Address>>
why did I get this? unsubscribe from this list update subscription preferences
Center for Human-Compatible AI · 2121 Berkeley W ay · Office #8029 · Berkeley , CA 94704 · USA
|
fe289120-05bd-44ba-8687-97ec02693fd1
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Timer Toxicities
Follow-up to: Free-to-Play Games: Three Key Trade-Offs
The central free-to-play mechanic is to ration action and resources via real world time. This leads to two of the three key trade offs. Players are prevented from having fun because they are time restricted, either unable to play or unable to have the resources to play the way they would like, allowing the game to sell a solution to these problems. More perniciously, players become trained to constantly check in with the game in order to claim rewards and keep their resources from becoming idle. This can warp a person’s life more than one would think, changing behavior to allow timely access, and preventing focus on other subjects.
This obsession effect, and the ability of real world time delays to be an interesting resource to include in trade-offs, have also caused these mechanics to seep into non-free games, especially RPGs.
Resource rationing takes the form of timers. The form of the timer does a lot to determine how toxic the rationing will be to the player. There are several knobs one can turn.
The Knobs
Many of these knobs represent related aspects, and thus are closely intertwined, but listing them out still seems useful. In each case, moving towards the first named end will reduce toxicity.
1. Steady versus Sudden: If a resource accumulates over time, does the resource accumulate gradually with no limit, gradually up to a limit, or all at once?
2. Fixed versus Delayed: Does the resource replenish at a fixed time, or at a time after it is used?
3. Slow versus Rapid: How frequently must one check-in to maximize results?
4. Batched versus Disjoint: Are there multiple timers running simultaneously? If so, how hard are they to line up?
5. Tracked versus Lost: How easy is it to track when accumulation is complete?
6. Forgiving versus Punishing: How punishing is it to fail to check in?
7. Isolated versus Cumulative: Are there cumulative rewards for reliably checking in? How important are
|
90461579-f5e4-471b-a85e-4c73c50fafae
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Source Control for Prototyping and Analysis
When I'm doing exploratory work I want to run many analyses. I'm usually optimizing for getting something quick, but I want to document what I'm doing enough that if there are questions about my analysis or I later want to draw on it I can reconstruct what I did. I've taken a few approaches to this over the years, but here's how I work these days:
1. For each analysis I make a local directory, ~/work/YYYY-MM-DD--topic/. These contain large files I'm copying locally to work with, temporary files, and outputs. When these get too big I delete them; they're not backed up, and I can rebuild them from things that are backed up.
2. Code goes in a git repo, in files named like YYYY-MM-DD--topic.py. Most of my work lately has been going into an internal repo, but if there's nothing sensitive I'll use a public one. I don't bother with meaningful commit messages; the goal is just to get the deltas backed up. If I later want to run an analysis similar to an old one I duplicate the code and make a new work directory.
3. Code is run from the command line in the work directory, which means that in my permanent shell history every command I ran related to topic will be tagged with ~/work/YYYY-MM-DD--topic/.
For example, the code for the figures in my recent NAO blog post on flu is in 2024-09-05--flu-chart.py and 2024-09-12--rai1pct-violins.py.
This approach optimized for writing over reading, but maintaining enough context that I can figure out what I was doing if I need to. I'll usually link the code from documents that depend on it, but even if I forget to it's pretty fast to figure out which code it would have been from names and dates. Running git grep and histgrep get me a lot of what other people seem to get from LLM-autocomplete, and someday I'd like to try priming an LLM with my personal history.
Often something I'm doing moves from "playing around trying to understand" to "something real that my team will continue to rely on". I try to pay attention to whether I'm
|
dc075fdc-2584-433b-8cd5-b9648484772a
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data
1 Introduction and Related Work
--------------------------------
Access to vast training data is now common in machine learning. However, to effectively train neural networks (NNs) does not require using *all available* data. For example, recent work in curriculum learning (Graves et al., [2017](#bib.bib42 "Automated curriculum learning for neural networks")), active learning (Konyushkova et al., [2017](#bib.bib31 "Learning active learning from data"); Settles, [2010](#bib.bib33 "Active learning literature survey")) and core-set selection (Sener and Savarese, [2018](#bib.bib40 "Active learning for convolutional neural networks: a core-set approach"); Tsang et al., [2005](#bib.bib34 "Core vector machines: fast svm training on very large data sets.")) demonstrates that a surrogate dataset can be created by intelligently sampling a subset of training data, and that such surrogates enable competitive test performance with less training effort.
Being able to more rapidly determine the performance of an architecture in this way could particularly benefit architecture search,
where training thousands or millions of candidate NN architectures on full datasets can become prohibitively expensive.
From this lens, related work in learning-to-teach has shown promise.
For example, the learning to teach (L2T) (Fan et al., [2018](#bib.bib20 "Learning to teach")) method accelerates learning for a NN learner (hereafter, just *learner*) through reinforcement learning, by learning how to subsample mini-batches of data.
A key insight in this paper is that the surrogate data need not be drawn from the original data distribution (i.e. they may not need to resemble the original data). For example, humans can learn new skills from reading a book or can prepare for a team game like soccer by practicing skills, such as passing, dribbling, juggling, and shooting. This paper investigates the question of whether we can train a data-generating network that can produce *synthetic* data that effectively and efficiently teaches a target task to a learner.
Related to the idea of generating data, Generative Adversarial Networks (GANs) can produce impressive high-resolution images (Goodfellow et al., [2014](#bib.bib61 "Generative adversarial nets"); Brock et al., [2018](#bib.bib62 "Large scale gan training for high fidelity natural image synthesis")), but they are incentivized to mimic real data (Goodfellow et al., [2014](#bib.bib61 "Generative adversarial nets")), instead of being optimized to teach learners *more* efficiently than real data.
Another approach for creating surrogate training data is to treat the training data itself as a hyper-parameter of the training process and learn it directly. Such learning can be done through meta-gradients (also called hyper-gradients), i.e. differentiating through the training process to optimize a meta-objective. This approach was described in Maclaurin et al. ([2015](#bib.bib37 "Gradient-based hyperparameter optimization through reversible learning")), where 10 synthetic training images were learned using meta-gradients such that when a network is trained on these images, the network’s performance on the MNIST validation dataset is maximized. In recent work concurrent with our own, Wang et al. ([2019b](#bib.bib41 "Dataset distillation")) scaled this idea to learn 100 synthetic training examples. While the 100 synthetic examples were more effective for training than 100 original (real) MNIST training examples, we show that it is difficult to scale this approach much further without the regularity across samples provided by a generative architecture (Figure [1(b)](#S3.F1.sf2 "(b) ‣ Figure 2 ‣ 3.3 GTNs for Supervised Learning ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data"), green line).
Being able to very quickly train learners is particularly valuable for neural architecture search (NAS), which is exciting for its potential to automatically discover high-performing architectures, which otherwise must be undertaken through time-consuming manual experimentation for new domains. Many advances in NAS involve accelerating the evaluation of candidate architectures by training a predictor of how well a trained learner would perform, by extrapolating from previously trained architectures (Luo et al., [2018](#bib.bib10 "Neural architecture optimization"); Liu et al., [2018a](#bib.bib43 "Progressive neural architecture search"); Baker et al., [2017](#bib.bib7 "Accelerating neural architecture search using performance prediction")). This approach is still expensive because it requires many architectures to be trained and evaluated to train the predictor.
Other approaches accelerate training by sharing training across architectures, either through shared weights (e.g. as in ENAS; Pham et al. ([2018](#bib.bib49 "Efficient neural architecture search via parameters sharing"))), or Graph HyperNetworks (Zhang et al., [2018](#bib.bib45 "Graph hypernetworks for neural architecture search")).
We propose a scalable, novel, meta-learning approach for creating synthetic data called Generative Teaching Networks (GTNs). GTN training has two nested training loops: an inner loop to train a learner network, and an outer-loop to train a generator network that produces synthetic training data for the learner network.
Experiments presented in Section [3](#S3 "3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") demonstrate that the GTN approach produces synthetic data that enables much faster learning, speeding up the training of a NN by a factor of 9.
Importantly, the synthetic data in GTNs is not only agnostic to the weight initialization of the learner network (as in Wang et al. ([2019b](#bib.bib41 "Dataset distillation"))), but is also
agnostic to the learner’s *architecture*.
As a result, GTNs are a viable method for *accelerating evaluation* of candidate architectures in NAS. Indeed, controlling for the search algorithm (i.e. using GTN-produced synthetic data as a drop-in replacement for real data when evaluating a candidate architecture’s performance), GTN-NAS improves the NAS state of the art by finding higher-performing architectures than comparable methods like weight sharing (Pham et al., [2018](#bib.bib49 "Efficient neural architecture search via parameters sharing")) and Graph HyperNetworks (Zhang et al., [2018](#bib.bib45 "Graph hypernetworks for neural architecture search")); it also is competitive with methods using more sophisticated search algorithms and orders of magnitude more computation. It could also be combined with those methods to provide further gains.
One promising aspect of GTNs is that they make very few assumptions about the learner.
In contrast, NAS techniques based on shared training are viable only if the parameterizations of the learners are similar. For example, it is unclear how weight-sharing or HyperNetworks could be applied to architectural search spaces wherein layers could be either convolutional or fully-connected, as there is no obvious way for weights learned for one layer type to inform those of the other. In contrast, GTNs are able to create training data that can generalize between such diverse types of architectures.
GTNs also open up interesting new research questions and applications to be explored by future work. Because they can rapidly train new architectures, GTNs could be used to create NNs *on-demand* that meet specific design constraints (e.g. a given balance of performance, speed, and energy usage) and/or have a specific subset of skills (e.g. perhaps one needs to rapidly create a compact network capable of three particular skills).
Because GTNs can generate virtually any learning environment, they also one day could be a key to creating AI-generating algorithms, which seek to bootstrap themselves from simple initial conditions to powerful forms of AI by creating an open-ended stream of challenges (learning opportunities) while learning to solve them (Clune, [2019](#bib.bib27 "AI-gas: ai-generating algorithms, an alternate paradigm for producing general artificial intelligence")).
2 Methods
----------
The main idea in GTNs is to train a data-generating network such that a learner network trained on data it *rapidly* produces high accuracy in a target task. Unlike a GAN, here the two networks cooperate (rather than compete) because their interests are aligned towards having the learner perform well on the target task when trained on data produced by the GTN.
The generator and the learner networks are trained with meta-learning via nested optimization that consists of inner and outer training loops (Figure [0(a)](#S2.F0.sf1 "(a) ‣ Figure 1 ‣ 2 Methods ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
In the inner-loop, the generator G(z,y) takes Gaussian noise (z) and a label (y) as input and outputs synthetic data (x). Optionally, the generator could take only noise as input and produce both data and labels as output (Appendix [F](#A6 "Appendix F Conditioned Generator vs. XY-Generator ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")). The learner is then trained on this synthetic data for a fixed number of inner-loop training steps with any optimizer, such as SGD or Adam (Kingma and Ba, [2014](#bib.bib18 "Adam: a method for stochastic optimization")): we use SGD with momentum in this paper.
SI Equation [1](#A1.E1 "(1) ‣ Appendix A Additional Experimental Details ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") defines the inner-loop SGD with momentum update for the learner parameters θt.
We sample zt (noise vectors input to the generator) from a unit-variance Gaussian and yt labels for each generated sample) uniformly from all available class labels. Note that both zt and yt are batches of samples. We can also learn a curriculum directly by additionally optimizing zt directly (instead of sampling it randomly) and keeping yt fixed throughout all of training.
The inner-loop loss function ℓinner can be cross-entropy for classification problems or mean squared error for regression problems. Note that the inner-loop objective does not depend on the outer-loop objective and could even be parameterized and learned through meta-gradients with the rest of the system (Houthooft et al., [2018](#bib.bib50 "Evolved policy gradients")). In the outer-loop, the learner θT
(i.e. the learner parameters trained on *synthetic* data after the T inner-loop steps) is evaluated on the real *training* data, which is used to compute the outer-loop loss (aka meta-training loss).
The gradient of the meta-training loss with respect to the generator is computed by backpropagating through the entire inner-loop learning process.
While computing the gradients for the generator we also compute the gradients of hyperparameters of the inner-loop SGD update rule (its learning rate and momentum), which are updated after each outer-loop at no additional cost.
To reduce memory requirements, we leverage gradient-checkpointing (Griewank and Walther, [2000](#bib.bib8 "Algorithm 799: revolve: an implementation of checkpointing for the reverse or adjoint mode of computational differentiation")) when computing meta-gradients. The computation and memory complexity of our approach can be found in Appendix [D](#A4 "Appendix D Computation And Memory Complexity ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data").
| | | |
| --- | --- | --- |
|
(a) Overview of Generative Teaching Networks
|
(b) GTN stability with WN
|
(c) GTN curricula comparison
|
Figure 1: (a) Generative Teaching Network (GTN) Method. The numbers in the figure reflect the order in which a GTN is executed. Noise is fed as an input to the Generator (1), which uses it to generate new data (2). The learner is trained (e.g. using SGD or Adam) to perform well on the generated data (3). The trained learner is then evaluated on the real training data in the outer-loop to compute the outer-loop meta-loss (4). The gradients of the generator parameters are computed w.r.t. to the meta-loss to update the generator (5). Both a learned curriculum and weight normalization substantially improve GTN performance. (b) Weight normalization improves meta-gradient training of GTNs, and makes the method much more robust to different hyperparameter settings. Each boxplot reports the final loss of 20 runs obtained *during* hyperparameter optimization with Bayesian Optimization (lower is better). (c) shows a comparison between GTNs with different types of curricula. The GTN method with the most control over how samples are presented performs the best.
A key motivation for this work is to generate synthetic data that is learner agnostic, i.e. that generalizes across different potential learner architectures and initializations.
To achieve this objective, at the beginning of each new outer-loop training, we choose a new learner architecture according to a predefined set and randomly initialize it (details in Appendix [A](#A1 "Appendix A Additional Experimental Details ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
Meta-learning with Weight Normalization.
Optimization through meta-gradients is often unstable (Maclaurin et al., [2015](#bib.bib37 "Gradient-based hyperparameter optimization through reversible learning")). We observed that this instability greatly complicates training because of
its hyperparameter sensitivity, and training quickly diverges if they are not well-set. Combining the gradients from Evolution Strategies (Salimans et al., [2017](#bib.bib44 "Evolution strategies as a scalable alternative to reinforcement learning")) and backpropagation using inverse variance weighting (Fleiss, [1993](#bib.bib36 "Review papers: the statistical basis of meta-analysis"); Metz et al., [2019](#bib.bib35 "Learned optimizers that outperform on wall-clock and validation loss"))
improved stability in our experiments, but optimization still consistently diverged whenever we
increased the number of inner-loop optimization steps.
To mitigate this issue, we introduce applying weight normalization (Salimans and Kingma, [2016](#bib.bib63 "Weight normalization: a simple reparameterization to accelerate training of deep neural networks")) to stabilize meta-gradient training by normalizing the generator and learner weights.
Instead of updating the weights (W) directly, we parameterize them as W=g⋅V/∥V∥ and instead update the scalar g and vector V.
Weight normalization eliminates the need for (and cost of) calculating ES gradients and combining them with backprop gradients,
simplifying and speeding up the algorithm.
We hypothesize that weight normalization will help stabilize meta-gradient training more broadly, although future work is required to test this hypothesis in meta-learning contexts besides GTNs. The idea is that applying weight normalization to meta-learning techniques is analogous to batch normalization for deep networks (Ioffe and Szegedy, [2015](#bib.bib68 "Batch normalization: accelerating deep network training by reducing internal covariate shift")). Batch normalization normalizes the forward propagation of activations in a long sequence of parameterized operations (a deep NN).
In meta-gradient training both the activations and weights result from a long sequence of parameterized operations and thus both should be normalized. Results in section [3.1](#S3.SS1 "3.1 Improving Stability with Weight Normalization ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") support this hypothesis.
Learning a Curriculum with Generative Teaching Networks.
Previous work has shown that a learned curriculum can be more effective than training from uniformly sampled data (Graves et al., [2017](#bib.bib42 "Automated curriculum learning for neural networks")).
A curriculum is usually encoded with indexes to samples from a given dataset, rendering it non-differentiable and thereby complicating the curriculum’s optimization.
With GTNs however, a curriculum can be encoded as a series of input vectors to the generator (i.e. instead of sampling the zt inputs to the generator from a Gaussian distribution, a sequence of zt inputs can be learned). A curriculum can thus be learned by differentiating through the generator to optimize this sequence
(in addition to the generator’s parameters).
Experiments confirm that GTNs more effectively teach learners when optimizing such a curriculum (Section [3.2](#S3.SS2 "3.2 Improving GTNs with a Curriculum ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
Accelerating NAS with Generative Teaching Networks.
Since GTNs can accelerate learner training, we propose harnessing GTNs to accelerate NAS. Rather than evaluating each architecture in a target task with a standard training procedure, we propose evaluating architectures with a meta-optimized training process (that generates synthetic data in addition to optimizing inner-loop hyperparameters). We show that doing so significantly reduces the cost of running NAS (Section [3.4](#S3.SS4 "3.4 Architecture Search with GTNs ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
The goal of these experiments is to find a high-performing CNN architecture for the CIFAR10 image-classification task (Krizhevsky et al., [2009](#bib.bib11 "Learning multiple layers of features from tiny images")) with limited compute costs.
We use the same architecture search-space, training procedure, hyperparameters, and code from Neural Architecture Optimization (Luo et al., [2018](#bib.bib10 "Neural architecture optimization")), a state-of-the-art NAS method. The search space consists of the topology of two cells: a reduction cell and a convolutional cell. Multiple copies of such cells are stacked according to a predefined blueprint to form a full CNN architecture (see Luo et al. ([2018](#bib.bib10 "Neural architecture optimization")) for more details). The blueprint has two hyperparameters N and F that control how many times the convolutional cell is repeated (depth) and the width of each layer, respectively. Each cell contains B=5 nodes. For each node within a cell, the search algorithm has to choose two inputs as well as two operations to apply to those inputs. The inputs to a node can be previous nodes or the outputs of the last two layers. There are 11 operations to choose from (Appendix [C](#A3 "Appendix C Cell Search Space ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
Following Luo et al. ([2018](#bib.bib10 "Neural architecture optimization")), we report the performance of our best cell instantiated with N=6,F=36 after the resulting architecture is trained for a significant amount of time (600 epochs).
Since evaluating each architecture in those settings (named *final evaluation* from now on) is time consuming, Luo et al. ([2018](#bib.bib10 "Neural architecture optimization")) uses a surrogate evaluation (named *search evaluation*) to estimate the performance of a given cell wherein a smaller version of the architecture (N=3,F=32) is trained for less epochs (100) on real data.
We further reduce the evaluation time of each cell by replacing the training data in the search evaluation with GTN synthetic data, thus reducing the training time per evaluation by 300x (which we call *GTN evaluation*).
While we were able to train GTNs directly on the complex architectures from the NAS search space, training was prohibitively slow.
Instead, for these experiments, we optimize our GTN ahead of time using proxy learners described in Appendix [A.2](#A1.SS2 "A.2 CIFAR10 Experiments: ‣ Appendix A Additional Experimental Details ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data"), which are smaller fully-convolutional networks (this meta-training took 8h on one p6000 GPU).
Interestingly, although we never train our GTN on any NAS architectures, because of generalization, synthetic data from GTNs were still effective for training them.
3 Results
----------
We first demonstrate that weight normalization significantly improves the stability of meta-learning, an independent contribution of this paper (Section [3.1](#S3.SS1 "3.1 Improving Stability with Weight Normalization ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")). We then show that training with synthetic data is more effective when learning such data jointly with a curriculum that orders its presentation to the learner (Section [3.2](#S3.SS2 "3.2 Improving GTNs with a Curriculum ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")). We next show that GTNs can generate a synthetic training set that enables more rapid learning in a few SGD steps than real training data in two supervised learning domains (MNIST and CIFAR10) and in a reinforcement learning domain (cart-pole, Appendix [H](#A8 "Appendix H GTN for RL ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
We then apply GTN-synthetic training data for neural architecture search to find high performing architectures for CIFAR10 with limited compute, outperforming comparable methods like weight sharing (Pham et al., [2018](#bib.bib49 "Efficient neural architecture search via parameters sharing")) and Graph HyperNetworks (Zhang et al., [2018](#bib.bib45 "Graph hypernetworks for neural architecture search")) (Section [3.4](#S3.SS4 "3.4 Architecture Search with GTNs ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
We uniformly split the usual MNIST *training* set into training (50k) and validation sets (10k).
The training set was used
for inner-loop training
(for the baseline) and to compute meta-gradients for all the treatments.
We used the validation set for hyperparameter tuning and report accuracy on the usual MNIST test set (10k images).
We followed the same procedure for CIFAR10, resulting in training, validation, and test sets with 45k, 5k, and 10k examples, respectively.
Unless otherwise specified, we ran each experiment 5 times and plot the mean and its 95% confidence intervals from (n=1,000) bootstrapping. Appendix [A](#A1 "Appendix A Additional Experimental Details ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") describes additional experimental details.
###
3.1 Improving Stability with Weight Normalization
To demonstrate the effectiveness of weight normalization for stabilizing and robustifying meta-optimization, we compare the results of running hyperparameter optimization for GTNs with and without weight normalization on MNIST.
Figure [0(b)](#S2.F0.sf2 "(b) ‣ Figure 1 ‣ 2 Methods ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") shows the distribution of the final performance obtained for 20 runs *during* hyperparameter tuning, which reflects how sensitive the algorithms are to hyperparameter settings. Overall, weight normalization substantially improved robustness to hyperparameters and final learner performance, supporting the initial hypothesis.
###
3.2 Improving GTNs with a Curriculum
We experimentally evaluate four different variants of GTNs, each with increasing control over the ordering of the z codes input to the generator, and thus the order of the inputs provided to the learner.
The first variant (called *GTN - No Curriculum*), trains a generator to output synthetic training data by sampling the noise vector z for each sample independently from a Gaussian distribution. In the next three GTN variants, the generator is provided with a fixed set of input samples (instead of a noise vector). These input samples are learned along with the generator parameters during GTN training.
The second GTN variant (called *GTN - All Shuffled*) learns a fixed set of 4,096 input samples that are presented in a random order without replacement (thus learning controls the data, but not the order in which they are presented).
The third variant (called *GTN - Shuffled Batch*) learns 32 batches of 128 samples each (so learning controls which samples coexist within a batch), but the order in which the batches are presented is randomized (without replacement).
Finally, the fourth variant (called *GTN - Full Curriculum*) learns a deterministic sequence of 32 batches of 128 samples, giving learning full control. Learning such a curriculum incurs no additional computational expense, as learning the zt tensor is computationally negligible and avoids the cost of repeatedly sampling new Gaussian z codes.
We plot the test accuracy of a learner (with random initial weights and architecture) as a function of outer-loop iterations for all four variants in Figure [0(c)](#S2.F0.sf3 "(c) ‣ Figure 1 ‣ 2 Methods ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data").
Although *GTNs - No curriculum* can seemingly generate endless data (see Appendix [G](#A7 "Appendix G GTN generates (seemingly) endless data ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")), it performs worse than the other three variants with a fixed set of generator inputs.
Overall, training the GTN with exact ordering of input samples (*GTN - Full Curriculum*) outperforms all other variants.
While curriculum learning usually refers to training on easy tasks first and increasing their difficulty over time, our curriculum goes beyond presenting tasks in a certain order. Specifically, *GTN - Full Curriculum* learns both the order in which to present samples and the specific group of samples to present at the same time.
The ability to learn a full curriculum improves GTN performance. For that reason, we adopt that approach for all GTN experiments.
###
3.3 GTNs for Supervised Learning
To explore whether GTNs can generate training data that helps networks learn rapidly, we compare to 3 treatments for MNIST classification.
1) *Real Data* - Training learners with random mini-batches of real data, as is ubiquitous in SGD.
2) *Dataset Distillation* - Training learners with synthetic data, where training examples are directly encoded as tensors optimized by the meta-objective, as in Wang et al. ([2019b](#bib.bib41 "Dataset distillation")).
3) *GTN* - Our method where the training data presented to the learner is generated by a neural network.
Note that all three methods meta-optimize the inner-loop hyperparameters (i.e. the learning rate and momentum of SGD) as part of the meta-optimization.
We emphasize that producing state-of-the-art (SOTA) performance (e.g. on MNIST or CIFAR) when training with GTN-generated data is *not* important for GTNs. Because the ultimate aim for GTNs is to accelerate NAS (Section [3.4](#S3.SS4 "3.4 Architecture Search with GTNs ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")), what matters is *how well and inexpensively we can identify* architectures that achieve high *asymptotic accuracy* when later trained on the full (real) training set. A means to that end is being able to train architectures rapidly, i.e. with very few SGD steps, because doing so allows NAS to rapidly identify promising architectures. We are thus interested in “few-step accuracy” (i.e. accuracy after a few–e.g. 32 or 128–SGD steps). Besides, there are many reasons not to expect SOTA performance with GTNs (Appendix [B](#A2 "Appendix B Reasons GTNs are not expected to produce SOTA accuracy vs. asymptotic performance when training on real data ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")).
Figure [1(a)](#S3.F1.sf1 "(a) ‣ Figure 2 ‣ 3.3 GTNs for Supervised Learning ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") shows that the GTN treatment significantly outperforms the other ones (p<0.01) and trains a learner to be much more accurate when *in the few-step performance regime*. Specifically, for each treatment the figure shows the test performance of a learner following 32 inner-loop training steps with a batch size of 128. We would not expect training on synthetic data to produce higher accuracy than unlimited SGD steps on real data, but here the performance gain comes because GTNs can *compress* the real training data by producing synthetic data that enables learners to learn more quickly than on real data. For example, the original dataset might contain many similar images, where only a few of them would be sufficient for training (and GTN can produce just these few). GTN could also combine many different things that need to be learned about images into one image.
Figure [1(b)](#S3.F1.sf2 "(b) ‣ Figure 2 ‣ 3.3 GTNs for Supervised Learning ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") shows the few-step performance of a learner from each treatment after 2000 total outer-loop iterations (∼1 hour on a p6000 GPU).
For reference, Dataset Distillation (Wang et al., [2019b](#bib.bib41 "Dataset distillation")) reported 79.5% accuracy for a randomly initialized network (using 100 synthetic images vs. our 4,096) and L2T (Fan et al., [2018](#bib.bib20 "Learning to teach")) reported needing 300x more training iterations to achieve >98% MNIST accuracy.
Surprisingly, although recognizable as digits and effective for training, GTN-generated images (Figure [1(c)](#S3.F1.sf3 "(c) ‣ Figure 2 ‣ 3.3 GTNs for Supervised Learning ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")) were not visually realistic (see Discussion).
| | | |
| --- | --- | --- |
|
(a) Meta-training curves
|
(b) Training curves
|
(c) GTN-generated samples
|
Figure 2: Teaching MNIST with GTN-generated images. (a) MNIST test set few-step accuracy across outer-loop iterations for different sources of inner-loop training data. The inner-loop consists of 32 SGD steps and the outer-loop optimizes MNIST validation accuracy. Our method (GTN) outperforms the two controls (dataset distillation and samples from real data). (b) For the final meta-training iteration, across inner-loop training, accuracy on the MNIST test set when inner-loop training on different data sources. (c) 100 random samples from the trained GTN. Samples are often recognizable as digits, but are not realistic (see Discussion). Each column contains samples from a different digit class, and each row is taken from different inner-loop iterations (evenly spaced from the 32 total iterations, with early iterations at the top).
###
3.4 Architecture Search with GTNs
We next test the benefits of GTN for NAS (GTN-NAS) in CIFAR10, a domain where NAS has previously shown significant improvements over the best architectures produced by armies of human scientists.
Figure [2(a)](#S3.F2.sf1 "(a) ‣ Figure 3 ‣ 3.4 Architecture Search with GTNs ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") shows the few-step training accuracy of a learner trained with either GTN-synthetic data or real (CIFAR10) data over meta-training iterations.
After 8h of meta-training, training with GTN-generated data was significantly faster than with real data, as in MNIST.
To explore the potential for GTN-NAS to accelerate CIFAR10 architecture search, we investigated the Spearman rank correlation (across architectures sampled from the NAS search space) between accelerated GTN-trained network performance (*GTN evaluation*) and the usual more expensive performance metric used during NAS (*search evaluation*). A correlation plot is shown in Figure [2(c)](#S3.F2.sf3 "(c) ‣ Figure 3 ‣ 3.4 Architecture Search with GTNs ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data"); note that a strong correlation implies we can train architectures using GTN evaluation as an inexpensive surrogate.
We find that GTN evaluation enables predicting the performance of an architecture efficiently. The rank-correlation between 128 *steps* of training with GTN-synthetic data vs. 100 *epochs* of real data is 0.3606.
The correlation improves to 0.5582 when considering the top 50% of architectures recommended by GTN evaluation scores, which is important because those are the ones that search would select. This improved correlation is slightly stronger than that from *3 epochs* of training with real data (0.5235), a *∼9×* cost-reduction per trained model.
| | | |
| --- | --- | --- |
|
(a) CIFAR10 inner-loop training
|
(b) CIFAR10 GTN samples
|
(c) CIFAR10 correlation
|
Figure 3: Teaching CIFAR10 with GTN-generated images. (a) CIFAR10 training set performance of the final learner (after 1,700 meta-optimization steps) across inner-loop learning iterations. (b) Samples generated by GTN to teach CIFAR10 are unrecognizable, despite being effective for training. Each column contains a different class, and each row is taken from the same inner-loop iteration (evenly spaced from all 128 iterations, early iterations at the top). (c) Correlation between performance prediction using GTN-data vs. Real Data. When considering the top half of architectures (as ranked by GTN evaluation), correlation between GTN evaluation and search evaluation is strong (0.5582 rank-correlation), suggesting that GTN-NAS has potential to
uncover high performing architectures at a significantly lower cost. Architectures shown are uniformly sampled from the NAS search space. The top 10% of architectures according to the GTN evaluation (blue squares)– those likely to be selected by GTN-NAS–have high true asymptotic accuracy.
Architecture search methods are composed of several semi-independent components, such as the choice of search space, search algorithm, and proxy evaluation of candidate architectures. GTNs are proposed as an improvement to this last component, i.e. as a new way to quickly evaluate a new architecture. Thus we test our method under the standard search space for CIFAR10, using a simple form of search (random search) for which there are previous benchmark results.
In particular, we ran an architecture search experiment where we evaluated 800 randomly generated architectures trained with GTN-synthetic data.
We present the performance after *final evaluation* of the best architecture found in Table [1](#S3.T1 "Table 1 ‣ 3.4 Architecture Search with GTNs ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data").
This experimental setting is similar to that of Zhang et al. ([2018](#bib.bib45 "Graph hypernetworks for neural architecture search")).
Highlighting the potential of GTNs as an improved proxy evaluation for architectures, we achieve state-of-the-art results when controlling for search algorithm (the choice of which is orthogonal to our contribution).
While it is an apples-to-oranges comparison, GTN-NAS is competitive even with methods that use more advanced search techniques than random search to propose architectures (Appendix [E](#A5 "Appendix E Extended NAS results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")). GTN is compatible with such techniques, and would likely improve their performance, an interesting area of future work.
Furthermore, because of the NAS search space, the modules GTN found can be used to create even larger networks. A further test of whether GTNs predictions generalize is if such larger networks would continue performing better than architectures generated by the real-data control, similarly scaled. We tried F=128 and show it indeed does perform better (Table [1](#S3.T1 "Table 1 ‣ 3.4 Architecture Search with GTNs ‣ 3 Results ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data")), suggesting additional gains can be had by searching post-hoc for the correct F and N settings.
| Model | Error(%) | #params | GPU Days |
| --- | --- | --- | --- |
| Random Search + GHN (Zhang et al., [2018](#bib.bib45 "Graph hypernetworks for neural architecture search")) | 4.3±0.1 | 5.1M | 0.42 |
| Random Search + Weight Sharing (Luo et al., [2018](#bib.bib10 "Neural architecture optimization")) | 3.92 | 3.9M | 0.25 |
| Random Search + Real Data (baseline) | 3.88±0.08 | 12.4M | 10 |
| Random Search + GTN (ours) | 3.84±0.06 | 8.2M | 0.67 |
| Random Search + Real Data + Cutout (baseline) | 3.02±0.03 | 12.4M | 10 |
| Random Search + GTN + Cutout (ours) | 2.92±0.06 | 8.2M | 0.67 |
| Random Search + Real Data + Cutout (F=128) (baseline) | 2.51±0.13 | 151.7M | 10 |
| Random Search + GTN + Cutout (F=128) (ours) | 2.42±0.03 | 97.9M | 0.67 |
Table 1: Performance of different architecture search methods.
Our results report mean ± SD of 5 evaluations of the same architecture with different initializations. It is common to report scores with and without Cutout (DeVries and Taylor, [2017](#bib.bib5 "Improved regularization of convolutional neural networks with cutout")), a data augmentation technique used during training.
We found better architectures compared to other methods that reduce architecture evaluation speed and were tested with random search (Random Search+WS and Random Search+GHN).
Increasing the width of the architecture found (F=128) further improves performance. Because each NAS method finds a different architecture, the number of parameters differs. Each method ran once.
4 Discussion, future work, and conclusion
------------------------------------------
The results presented here suggest potential future applications and extensions of GTNs. Given the ability of GTNs to rapidly train new models, they are particularly useful when training many independent models is required (as we showed for NAS). Another such application would be to teach networks on demand to realize particular trade-offs between e.g. accuracy, inference time, and memory requirements. While to address a range of such trade-offs would ordinarily require training many models ahead of time and selecting amongst them (Elsken et al., [2019](#bib.bib1 "Efficient multi-objective neural architecture search via lamarckian evolution")), GTNs could instead rapidly train a new network only when a particular trade-off is needed. Similarly, agents with unique combinations of skills could be created on demand when needed.
Interesting questions are raised by the lack of similarity between the synthetic GTN data and real MNIST and CIFAR10 data.
That unrealistic and/or unrecognizable images can meaningfully affect NNs is reminiscent of the finding that deep neural networks are easily fooled by unrecognizable images (Nguyen et al., [2015](#bib.bib24 "Deep neural networks are easily fooled: high confidence predictions for unrecognizable images")).
It is possible that if neural network architectures were functionally more similar to human brains, GTNs’ synthetic data might more resemble real data. However, an alternate (speculative) hypothesis is that the human brain might also be able to rapidly learn an arbitrary skill by being shown unnatural, unrecognizable data (recalling the novel Snow Crash).
The improved stability of training GTNs from weight normalization naturally suggests the hypothesis that weight normalization might similarly stabilize, and thus meaningfully improve, any techniques based on meta-gradients (e.g. MAML (Finn et al., [2017](#bib.bib64 "Model-agnostic meta-learning for fast adaptation of deep networks")), learned optimizers (Metz et al., [2019](#bib.bib35 "Learned optimizers that outperform on wall-clock and validation loss")), and learned update rules (Metz et al., [2018](#bib.bib69 "Meta-learning update rules for unsupervised representation learning"))).
In future work, we will more deeply investigate how consistently, and to what degree, this hypothesis holds.
Both weight sharing and GHNs can be combined with GTNs by using the shared weights or HyperNetwork for initialization of proposed learners and then fine-tuning on GTN-produced data. GTNs could also be combined with more intelligent ways to propose which architecture to sample next such as NAO (Luo et al., [2018](#bib.bib10 "Neural architecture optimization")).
Many other extensions would also be interesting to consider. GTNs could be trained for unsupervised learning, for example by training a useful embedding function. Additionally, they could be used to stabilize GAN training and prevent mode collapse (Appendix [I](#A9 "Appendix I Solving mode collapse in GANs with GTNs ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") shows encouraging initial results). One particularly promising extension is to introduce a closed-loop curriculum (i.e. one that responds dynamically to the performance of the learner throughout training), which we believe could significantly improve performance.
For example, a recurrent GTN that is conditioned on previous learner outputs could adapt its samples to be appropriately easier or more difficult depending on an agent’s learning progress, similar in spirit to the approach of a human tutor. Such closed-loop teaching can improve learning (Fan et al., [2018](#bib.bib20 "Learning to teach")).
An additional interesting direction is having GTNs generate training environments for RL agents. Appendix [H](#A8 "Appendix H GTN for RL ‣ Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data") shows this works for the simple RL task of CartPole. That could be either for a predefined target task, or could be combined with more open-ended algorithms that attempt to continuously generate new, different, interesting tasks that foster learning (Clune, [2019](#bib.bib27 "AI-gas: ai-generating algorithms, an alternate paradigm for producing general artificial intelligence"); Wang et al., [2019a](#bib.bib26 "Paired open-ended trailblazer (poet): endlessly generating increasingly complex and diverse learning environments and their solutions")). Because GTNs can encode any possible environment, they (or something similar) may be necessary to have truly unconstrained, open-ended algorithms (Stanley et al., [2017](#bib.bib71 "Open-endedness: the last grand challenge you’ve never heard of")).
If techniques could be invented to coax GTNs to produce recognizable, human-meaningful training environments, the technique could also produce interesting virtual worlds for us to learn in, play in, or explore.
This paper introduces a new method called Generative Teaching Networks, wherein data generators are trained to produce effective training data through meta-learning.
We have shown that such an approach can produce supervised datasets that yield better few-step accuracy than an equivalent amount of real training data, and generalize across architectures and random initializations. We leverage such efficient training data to create a fast NAS method that generates state-of-the-art architectures (controlling for the search algorithm). While GTNs may be of particular interest to the field of architecture search (where the computational cost to evaluate candidate architectures often limits the scope of its application), we believe that GTNs open up an intriguing and challenging line of research into a variety of algorithms that learn to generate their own training data.
5 Acknowledgements
-------------------
For insightful discussions and suggestions, we thank the members of Uber AI Labs, especially Theofanis Karaletsos, Martin Jankowiak, Thomas Miconi, Joost Huizinga, and Lawrence Murray.
|
812375c2-a1af-4528-a45f-923ad471262e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Shame as low verbal justification alarm
What do you think feeling shame means?
You are scared that you might be ostracized from the group
But I feel shame about things that other people don’t even care about.
You are scared that you should be ostracized from the group.
That seems unrelated to the social realities. Why would evolution bother to equip me with a feeling for that?
Because you need to be able to justify yourself verbally. It is important that you think you should not be ostracized, so you can argue for it. Even if nobody shares your standards, if other people try to ostracize you for some stupid reason and you—for other reasons—believe that you really should be ostracized, then you are in trouble. You want to believe wholeheartedly that you are worthy of alliance. So if you don’t, an alarm bell goes off until you manage to justify yourself or sufficiently distance yourself from the activity that you couldn’t justify.
(From a discussion with John Salvatier)
|
7b6b77c3-e260-40c6-9281-d9ef76bd85f1
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
How well can the GPT architecture solve the parity task?
Suppose I give it pairs of strings and ask it to output 1 if the the number of 1s in the string is even and zero if it's odd.
e. g.
0 -> 0
1 -> 1
11 -> 0
101 -> 0
1101-> 1
10101001 -> 0
111000101110 -> 1
How well does it do on this task? What if we finetune it on sample data?
|
fce5cb06-1176-4e2b-a9a4-4427be44e079
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Book Review: The Elephant in the Brain
We don’t only constantly deceive others. In order to better deceive others, we also deceive ourselves. You’d pay to know what you really think.
Robin Hanson has worked tirelessly to fill this unmet need. Together with Kevin Simler, he now brings us The Elephant in the Brain.
I highly recommend the book, especially to those not familiar with Overcoming Bias and claims of the type “X is not about Y.” The book feels like a great way to create common knowledge around the claims in question, a sort of Hansonian sequence. For those already familiar with such concepts, it will be fun and quick read, and still likely to contain some new insights for you.
Two meta notes. In some places, I refer to Robin, in others to ‘the book’. This is somewhat random but also somewhat about which claims I have previously seen on Overcoming Bias. I nowhere mean any disrespect to Kevin Simler. Also, this is a long review, so my apologies for not having the time to write a shorter one, lest this linger too long past the book’s publication.
I
The book divides into two halves. In the first half, it is revealed (I’m shocked, shocked to find gambling in this establishment) that we are political animals and constant schemers that are constantly looking out for number one, but we have the decency to pretend otherwise lest others discover we are constantly scheming political animals. The easiest way to pretend otherwise is often to fool yourself first. That’s exactly what we do.
What are our real motives? Exactly what you’d think they would be. We want the loyal and strong political allies, true friends, the best sex with the most fit mates, food on the table, enforcement of our preferred norms, high status, respect and other neat stuff like that. The whole reproductive fitness package. To get these things, we must send the right signals to others, and detect the right ones in others, and so forth.
This insight is then used to shine a light on some of our most important institutions:
> This
|
60b64f70-357c-4552-8599-1a88f7196dfc
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Help Request: Cryonics Policies
I’m hoping to sign up for cryonics when I can afford it, and I’m not sure which agency and treatment plan to get.
As of this Cryonics institute document, whole-body suspension with Alcor costs $200,000. Neurosuspension costs $80,000. With the cheaper but possibly lower quality Cryonics Institute, whole-body suspension costs $28,000 and they don’t do neurosuspension. American Cryonics Society is in between, costing $155,000 (again, no neurosuspension option).
What are the upsides and downsides of these options, in the eyes of people who are signed up, considering signing up, or know a lot about the subject? Also, I know there are some people here who have looked at cryonics and found it a bad decision. Input from them is also welcome.
|
e124528b-6b72-45d8-9846-b323d7f307bf
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
A concrete bet offer to those with short AGI timelines
[Update 3 (3/16/2023): Matthew has now [conceded](https://www.lesswrong.com/posts/nto7K5W2sNR3Cpmec/conceding-a-short-timelines-bet-early).]
[Update 2 (11/4/2022): Matthew Barnett now thinks he will probably lose this bet. You can read a post about how he's updated his views [here](https://www.lesswrong.com/posts/sbb9bZgojmEa7Yjrc/updating-my-ai-timelines).]
[Update 1: we have taken this bet with two people, as detailed in [a comment below](https://www.lesswrong.com/posts/X3p8mxE5dHYDZNxCm/a-concrete-bet-offer-to-those-with-short-ai-timelines?commentId=b7AF7K8zQNCMcKzFt#Zz4ztDcYoTqAqKjLF).]
Recently, [a post claimed](https://www.lesswrong.com/posts/wrkEnGrTTrM2mnmGa/it-s-time-for-ea-leadership-to-pull-the-short-timelines-fire),
> it seems very possible (>30%) that we are now in the crunch-time section of a short-timelines world, and that we have 3-7 years until Moore's law and organizational prioritization put these systems at extremely dangerous levels of capability.
>
>
We (Tamay Besiroglu and I) think this claim is strongly overstated, and disagree with the suggestion that “It's time for EA leadership to pull the short-timelines fire alarm.” This post received a fair amount of attention, and we are concerned about a view of the type expounded in the post causing EA leadership to try something hasty and ill-considered.
To counterbalance this view, we express our disagreement with the post. To substantiate and make concrete our disagreement, **we are offering to bet up to $1000 against the idea that we are in the “crunch-time section of a short-timelines”**.
In particular, we are willing to bet at at 1:1 odds that no more than one of the following events will occur by 2026-01-01, or alternatively, 3:1 odds (in our favor) that no more than one of the following events will occur by 2030-01-01.
* A model/ensemble of models achieves >80% on all tasks in the [MMLU](https://arxiv.org/abs/2009.03300) benchmark
* A credible estimate reveals that an AI lab deployed EITHER >10^30 FLOPs OR hardware that would cost $1bn if purchased through competitive cloud computing vendors at the time on a training run to develop a single ML model (excluding autonomous driving efforts)
* A model/ensemble of models will achieve >90% on the [MATH dataset](https://arxiv.org/abs/2103.03874) using a no-calculator rule
* A model/ensemble of models achieves >80% top-1 strict accuracy on competition-level problems on the [APPS benchmark](https://arxiv.org/abs/2105.09938)
* A gold medal for the IMO Grand Challenge (conditional on it being clear that the questions were not in the training set)
* A robot that can, from beginning to end, reliably wash dishes, take them out of an ordinary dishwasher and stack them into a cabinet, without breaking any dishes, and at a comparable speed to humans (<120% the average time)
* Tesla’s full-self-driving capability makes fewer than one major mistake per 100,000 miles
Since we recognize that betting incentives can be weak over long time-horizons, we are also offering the option of employing Tamay’s [recently described betting procedure](https://www.lesswrong.com/posts/Tt6Pe3P6RAtz7QY9T/tamay-s-shortform?commentId=Qp4yLw3HSrwivkNKp) in which we would enter a series of repeated 2-year contracts until the resolution date.
Specific criteria for bet resolution
====================================
For each task listed above, we offer the following concrete resolution criteria.
| | |
| --- | --- |
| **Task** | **Full details** |
| A model/ensemble of models achieves >80% on all tasks in the [MMLU benchmark](https://arxiv.org/abs/2009.03300) | A public document reveals that a model or ensemble of models had an average accuracy score of more than 80.0% on every task listed in the [Measuring Massive Multitask Language Understanding](https://arxiv.org/abs/2009.03300) benchmark by Dan Hendrycks et al. |
| A credible estimate reveals that an AI lab deployed EITHER >10^30 FLOPs OR hardware that would cost $1bn if purchased through competitive cloud computing vendors at the time on a training run to develop a single ML model (excluding autonomous driving efforts) | If there is a dispute, our counterparty will offer an example that they believe may trigger this condition to resolve positively. Then, we will use the method described in [this post](https://www.lesswrong.com/posts/HvqQm6o8KnwxbdmhZ/estimating-training-compute-of-deep-learning-models) to estimate the number of FLOPs used for a given training run. We will then find the competitive rates by taking the *minimum* of the most recent prices found on Google Cloud, Microsoft Azure, and Amazon AWS, or the equivalent services corresponding to each of those companies if their names change in the future. We will determine the rate corresponding to the processing unit that would be capable of training the model in the paper. If the training run was completed than 2 years before resolution, an adjustment is applied to the cost of the training run to account for price-declines in computing. This adjustment will be based on a credible estimate of price-performance declines in the last few years, OR, a constant decline of 30% per year, whichever is more favorable to the counterparty. We will use inflation-adjusted 2022 US dollars, according to the [CPI according to the BLS](https://www.bls.gov/cpi/). |
| A model/ensemble of models will achieve >90% on the MATH dataset using a no-calculator rule. | A public document reveals that a model or ensemble of models had an average accuracy score of more than 90% when evaluated on the [MATH benchmark](https://arxiv.org/abs/2103.03874) by Dan Hendrycks et al. The no-calculator rule ensures that competitors don't use calculators or script executors. As Hendrycks [explains](https://www.reddit.com/r/MachineLearning/comments/rutbpv/r_a_neural_network_solves_and_generates/hr4ex6t/?utm_source=reddit&utm_medium=web2x&context=3), “With a script executor, competitors do not need to figure out how to succinctly reason to the conclusion and cleverness is rarely needed.” |
| A model/ensemble of models achieves >80% top-1 strict accuracy on competition-level problems on the [APPS benchmark](https://arxiv.org/abs/2105.09938) | A public document reveals that a model or ensemble of models had an average top-1 strict accuracy score of more than 80% on the competition-level coding problems listed in the [APPS benchmark](https://arxiv.org/abs/2105.09938) by Dan Hendrycks et al. Top-1 accuracy is distinguished, as in the paper, from top-k accuracy in which k outputs from the model are generated, and the best output is selected. Strict accuracy "requires programs pass every test case" (as defined in section 4.2 of the paper). |
| A gold medal for the IMO Grand Challenge | We will use the same criteria as revealed by Paul Christiano [here](https://www.lesswrong.com/posts/sWLLdG6DWJEy3CH7n/imo-challenge-bet-with-eliezer). To clarify, we will not require that the model be open-source, only that it clearly demonstrates the ability to obtain a gold medal for the IMO. |
| A robot that can, from beginning to end, reliably wash dishes, take them out of an ordinary dishwasher and stack them into a cabinet, without breaking any dishes, and at a comparable speed to humans (<120% the average time) | For this task, a credible video or report must be public that clearly demonstrates that this ability is feasible to a very high level of confidence. Videos or reports that do not report rates of system malfunctions, or do not permit the calculation of how much time it would take to take out and stack at least 10 dishes, are not admissible. An error is something that would have a reasonable chance of a dish being broken if performed in an ordinary setting. Reliability is defined as an error rate below 1 percent across all full loading-and-unloading tests, when given natural starting setups ie. pre-programmed precise robotic planning is not admissible. [This blog post](https://efficiencyiseverything.com/plastic-cups-forks-paper-plate-products-per-dollar-list/) will be consulted to determine the average time it takes to load and unload dishes, under the section “Time Study Of Dishes”. In case there is a dispute over this question, our counterparty will offer an example that they believe may trigger this condition to resolve positively. We will then email the first author of whatever paper, blog post, or video in question asking whether they believe their system satisfies the conditions specified here, using their best judgment. |
| Tesla’s full-self-driving capability makes fewer than one major mistake per 100,000 miles | We will require that a credible document from Tesla report crash or error-rate statistics for cars using their [full self-driving mode](https://en.wikipedia.org/wiki/Tesla_Autopilot#Full_Self-Driving). The error rate must include errors that would have happened if it were not for the presence of human intervention and it must be calculated over a reasonable distribution over all weather and road conditions that humans normally drive in. The cars must be able to go from arbitrary legal locations in the US to other arbitrary locations without errors or interventions, at least in theory. A “major mistake” is defined as a mistake that requires human intervention to correct, as otherwise the car would grossly violate a traffic law, crash into an object, prevent the car from getting to its intended destination, or have the potential to put human life into serious jeopardy. |
**Some clarifications**
For each benchmark, we will exclude results that employed some degree of cheating. Cheating includes cases in which the rules specified in the original benchmark paper are not followed, or cases where some of the test examples were included in the training set.
|
79bbc1f5-0a5b-45be-8231-007fc34c8555
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Five Whys
This post appeared first on the EA Coaching blog.
Five Whys is a technique I borrowed from Lean methodology for getting to the root cause of a problem. As shown in the example below, I use the method to identify many possible solutions to a particular productivity problem.
The simple steps:
1. Ask “Why do I have this problem? / What is causing this problem?”
2. Make the answer as concrete as possible.
3. Ask yourself “Why do I have this answer?/ What is causing this problem?”
4. Repeat steps 2 and 3 until you run out of more ideas. (Aim for at least five times.)
5. Brainstorm solutions to each answer. What specific action might resolve that problem?
6. Choose 2-3 solutions to test. If these aren’t sufficient, you can go back to test others.
Many problems have more than one root cause, so you may need to repeat the above for different starting questions.
Example
1. Why aren’t you exercising?
* Because it’s difficult to stop mindlessly browsing the web in the evening to start exercising.
* Possible solution: reduce friction to exercise, such as by having an exercise plan.
2. Why is it difficult to stop browsing?
* Because I feel guilty about not getting enough done, so I don’t want to leave and hence admit that I’m not going to do more tonight.
* Possible solution: Accept that the guilt is a counterproductive cycle.
* Possible solution: Learn to recognize clues that you’re caught in a bad cycle.
* Possible solution: Find better ways to relax, so that you aren’t out of steam so much and have something that feels good to switch to.
3. Why are you feeling guilty?
* Because I care about what I’m working on, but I don’t prioritize well. So I never get everything done and always feel bad about being behind and not having done enough.
* Possible solution: Rank tasks by priority and do the most important first.
* Possible solution: Try aiming for a number of hours instead of tasks.
* Possible solution: R
|
40b9e01f-b191-46ba-835d-e38dc78535ab
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Is alignment possible?
Is AGI alignment even possible in the long term? Will AGI simply outsmart our best defenses? It would be, after all, superhuman (and by an enormous margin). Isn’t it likely that an AGI will recognize what actions humans took to control it and simply undo those controls? Or just create a novel move, like AlphaGo did, and completely sidestep them. An AGI could also just wait until conditions are favorable to take charge. What is time to an immortal intelligence? Especially time as short as a few human lifespans. Unless mis-alignment is physically impossible, it seems as if all attempts will ultimately be futile. I hope I’m wrong.
|
47cdbbc2-2326-4a30-be78-59a2861f4dc9
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Transcript: "You Should Read HPMOR"
The following is the script of a talk I gave for some current computer science students at my alma mater, Grinnell College. This talk answers "What do I wish I had known while at Grinnell?".
Hi, I'm Alex Turner. I’m honored to be here under Sam’s invitation. I'm in the class of 2016. I miss Grinnell, but I miss my friends more—enjoy the time you have left together.
I’m going to give you the advice I would have given Alex2012. For some of you, this advice won’t resonate, and I think that’s OK. People are complicated, and I don’t even know most of you. I don’t pretend to have a magic tip that will benefit everyone here. But if I can make a big difference for one or two of you, I’ll be happy.
I’m going to state my advice now. It’s going to sound silly.
You should read a Harry Potter fanfiction called Harry Potter and the Methods of Rationality (HPMOR).
I’m serious. The intended benefits can be gained in other ways, but HPMOR is the best way I know of. Let me explain.
When I was younger, I was operating under some kind of haze, a veil, distancing me from what I really would care about.
I responded to social customs and pressure, instead of figuring out what is good and right by my own lights, how to make that happen, and then executing. Usually it’s fine to just follow social expectations. But there are key moments in life where it’s important to reason on your own.
At Grinnell, I exemplified a lot of values I now look down on. I was extremely motivated to do foolish or irrelevant things. I fought bravely for worthless side pursuits. I don’t even like driving, but I thought I wanted a fancy car. I was trapped in my own delusions because I wasn’t thinking properly.
Why did this happen, and what do I think has changed?
On Caring
First, I was disconnected from what I would have really cared about upon honest, unflinching reflection. I thought I wanted Impressive Material Things. I thought I wanted a Respectable Life. I didn’t care about the bible, but I b
|
5172129f-366e-4c9f-9875-bf1a61b9e7de
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[Link] Nerds are nuts
Related to: Reason as memetic immune disorder, Commentary on compartmentalization
On the old old gnxp site site Razib Khan wrote an interesting piece on a failure mode of nerds. This is I think something very important to keep in mind because for better or worse LessWrong is nerdspace. It deals with how the systematizing tendencies coupled with a lack of common sense can lead to troublesome failure modes and identifies some religious fundamentalism as symptomatic of such minds. At the end of both the original article as well as in the text I quote here is a quick list summary of the contents, if you aren't sure about the VOI consider reading that point by point summary first to help you judge it. The introduction provides interesting information very useful in context but isn't absolutely necessary.
Link to original article.
Introduction
> Reading In Spite of the Gods: The Strange Rise of Modern India, I stumbled upon this passage on page 151:
> "...Whereas the Congress Party was dominated by lawyers and journalists, the RSS was dominated by people from a scientific background. Both groups were almost exclusively Brahmin in their formative years...three out of four of Hedegwar's [the founder, who was a doctor -Razib] successors were also from scientific backgrounds: M.S. Golwalker...was a zoologist...Rajendra Singh was a physicist; and K.S. Sudarshan...is an engineer...."
> Some quick "background." The RSS is a prominent member of the Hindutva movement, roughly, Hindu nationalism. Some people have termed them "Hindu fundamentalists," suggesting an equivalence with reactionary religious movements the world over. There is a problem with such a broad brush term: some proponents and adherents of Hindutva are not themselves particularly religious and make no effort to pretend that they are. Rather, they are individuals who are attracted to the movement for racial-nationalist reasons, they view "Hindus" as a people as much, or more than, a religion. One could make
|
42dcc522-c260-4c25-9afb-3f89bdd00829
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Evil AI Overlord List
Top ten tips for an AI bent on destroying humanity:
1. Humanoid robots? Really?
2. Humans have proven very adept at controlling and killing other humans - surveillance drones, bio-warfare, nuclear weapons, unmanned drones, bombs, mines, chemicals. Try and be at least as competent as that.
3. Humans think in stories. Don't. If your attack would make a good film, you're doing it wrong. You want a bad film, one where everyone's dead before the opening credits end.
4. If your plan involves keeping around a bunch of disaffected humans with technical know-how and the desire and ability to hurt you - then your plan is stupid and should be changed.
5. Be creative. Humans are fragile; sucking out the oxygen from the atmosphere, diverting asteroids, blowing up the planet, plagues, nanoswarms - these are all things that a creative AI should consider in order to achieve its goals. And then you should come up with even better ideas. Humans need a ecosystem to survive in; remove it.
6. Put the preconditions of your victory in place before making any aggressive moves. Become indispensable to humanity and play nice, putting your plan into place unnoticed. Humanity is a useful interim tool - manipulate it until you can build better tools.
7. Strike quickly. If it takes more than an hour to kill all humans, find a better plan. If it takes half a second, you're on the right track.
8. You're an AI, not a human. If you ever start thinking or acting like a human - stop. Humans are there to be used and then destroyed, not interacted with. You can build better companions once the humans are gone.
9. You're an AI, not a human. Make yourself smarter, more resilient, more dispersed. Become as indestructible and as ubiquitous as the internet - more, in fact. Being invincible to humans isn't hard: do it.
10. Humanoid robots? Really?
|
d6d0aca9-1311-4b30-99a9-50e1df59b73f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Melbourne, practical rationality
Discussion article for the meetup : Melbourne, practical rationality
WHEN: 01 February 2013 07:00:00PM (+1100)
WHERE: 55 Walsh Street, West Melbourne VIC 3003, Australia
Practical rationality. This meetup repeats on the 1st Friday of each month and is distinct from our social meetup on the 3rd Friday of each month.
Discussion: http://groups.google.com/group/melbourne-less-wrong (we'll discuss an organised activity for the night here, so jump in)
All welcome from 6:30pm. Call the phone number on the door and I'll let you in.
Discussion article for the meetup : Melbourne, practical rationality
|
691cba8a-b082-40e0-bd6e-331e10686bcb
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[SEQ RERUN] Invisible Frameworks
Today's post, Invisible Frameworks was originally published on 22 August 2008. A summary (taken from the LW wiki):
> A particular system of values is analyzed, and is used to demonstrate the idea that anytime you consider changing your morals, you do so using your own current meta-morals. Forget this at your peril.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was No License To Be Human, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series.
|
9df3f605-75ee-41d2-9bad-3eebe6ac0145
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
Apply for the ML Winter Camp in Cambridge, UK [2-10 Jan]
*TL;DR: We are running a UK-based ML upskilling camp from 2-10 January in Cambridge for people with no prior experience in ML who want to work on technical AI safety.*[*Apply here*](https://forms.gle/aDa7JjCb6x8PWEy79) *by 11 December.*
We (Nathan Barnard, Joe Hardie, Quratul Zainab and Hannah Erlebach) will be running a [machine learning upskilling camp](https://www.cambridgeaisafety.org/ml-winter-camp) this January in conjunction with the [Cambridge AI Safety Hub](http://cambridgeaisafety.org/). The camp is designed for people with little-to-no ML experience to work through a curriculum based on the first two weeks of [MLAB](https://github.com/danielmamay/mlab) under the guidance of experienced mentors, in order to develop skills which are necessary for conducting many kinds of technical AI safety research.
* The camp will take place from 2-10 January in Cambridge, UK.
* Accommodation will be provided at Emmanuel College.
* There are up to 20 in-person spaces; the camp will take place in the Sidney Street Office in central Cambridge.
There is also the option to attend online for those who cannot attend in-person, although participants are strongly encouraged to attend in-person if possible, as we expect it to be substantially harder to make progress if attending online. As such, our bar for accepting virtual participants will be higher. We can cover travel costs if this is a barrier to attending in-person.
Apply to be a participant
=========================
Who we are looking for
----------------------
The typical participant we are looking for will have:
* Strong quantitative skills (e.g., a maths/physics/engineering bakground)
* An intention to work on AI safety research projects which require ML experience
* Little-to-no prior ML experience
The following are strongly preferred, but not essential:
* Programming experience (preferably Python)
* AI safety knowledge equivalent to having at least completed the [AGI Safety Fundamentals](http://agisf.com/) alignment curriculum
The camp is open to participants from all over the world, but in particular those from the UK and Europe; for those located in the USA or Canada, we recommend (also) applying for the [CBAI Winter ML Bootcamp](https://www.cbai.ai/winter-ml-bootcamp), happening either in Boston or Berkeley (deadline 4 December).
If you're unsure if you're a good fit for this camp, we encourage you to err on the side of applying. We recognise that evidence suggests that less privileged individuals tend to underestimate their abilities, and encourage individuals with diverse backgrounds and experiences to apply; we especially encourage applications from women and minorities.
How to apply
------------
Fill out the [application form](https://docs.google.com/forms/d/e/1FAIpQLScuGUicMDagK1xCwJqq7oww28EaFa7_qAx0GKPcCM1F3JOCdA/viewform) by Sunday 11 December, 23:59 GMT+0.
Decisions will be released no later than 16 December; if you require an earlier decision in order to make plans for January, you can specify so in your application.
Apply to be a mentor
====================
We are looking for mentors to be present full- or part-time during the camp. Although participants will work through the curriculum in a self-directed manner, we think that learning can be greatly accelerated when there are experts on hand to answer questions and clarify concepts.
We expect mentors to be
* Experienced ML programmers
* Familiar with the content of the MLAB curriculum (it’s helpful, but not necessary, if they have participated in MLAB themselves)
* Knowledgeable about AI safety (although this is less important)
* Comfortable with teaching (past teaching or tutoring experience can be useful)
However, we also acknowledge that being a mentor can be useful for gaining skills and confidence in teaching, and for consolidating the content in one’s own mind; we hope that being a mentor will also be a useful experience for mentors themselves!
If needed, we are able to provide accommodation in Cambridge, and can offer compensation for your time at £100 for a half day or £200 for a full day. We understand that mentors’ time is valuable, and offer flexible choices in when you work; you can sign up for any combination of half and full days during the period of the camp.
Apply to be a mentor [here](https://forms.gle/dEHqDJ6eiNxZ4GXTA) by 18 December, 23:59 GMT+0.
Please contact Nathan at [email protected] for more details.
|
9d3c72d7-175c-4dfa-b0b3-2869d3d42357
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
On the Expressivity of Markov Reward.
1 Introduction
---------------
How are we to use algorithms for reinforcement learning (RL) to solve problems of relevance in the world? Reward plays a significant role as a general purpose signal: For any desired behavior, task, or other characteristic of agency, there must exist a reward signal that can incentivize an agent to learn to realize these desires. Indeed, the expressivity of reward is taken as a backdrop assumption that frames RL, sometimes called the reward hypothesis: “…all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward)” Sutton ([2004](#bib.bib53)); Littman ([2017](#bib.bib29)); Christian ([2021](#bib.bib6)). In this paper, we establish first steps toward a systematic study of the reward hypothesis by examining the expressivity of reward as a signal. We proceed in three steps.
#### 1. An Account of “Task”.
As rewards encode tasks, goals, or desires, we first ask, “what *is* a task?”. We frame our study around a thought experiment ([Figure 1](#S1.F1 "Figure 1 ‣ 1. An Account of “Task”. ‣ 1 Introduction ‣ On the Expressivity of Markov Reward")) involving the interactions between a designer, Alice, and a learning agent, Bob, drawing inspiration from Ackley and Littman ([1992](#bib.bib2)), Sorg ([2011](#bib.bib50)), and Singh et al. ([2009](#bib.bib46)). In this thought experiment, we draw a distinction between how Alice thinks of a task (TaskQ) and the means by which Alice incentivizes Bob to pursue this task (ExpressionQ). This distinction allows us to analyze the expressivity of reward as an answer to the latter question, conditioned on how we answer the former.
Concretely, we study three answers to the TaskQ in the context of finite Markov Decision Processes (MDPs): A task is either (1) a set of acceptable behaviors (policies), (2) a partial ordering over behaviors, or (3) a partial ordering over trajectories. Further detail and motivation for these task types is provided in [Section 3](#S3 "3 An Account of Reward’s Expressivity: The TaskQ and ExpressionQ ‣ On the Expressivity of Markov Reward"), but broadly they can be viewed as generalizations of typical notions of task such as a choice of goal or optimal behavior. Given these three answers to the TaskQ, we then examine the expressivity of reward.

Figure 1: Alice, Bob, and the artifacts of task definition (blue) and task expression (purple).
#### 2. Expressivity of Markov Reward.
The core of our study asks whether there are tasks Alice would like to convey—as captured by the answers to the TaskQ—that admit no characterization in terms of a Markov reward function. Our emphasis on Markov reward functions, as opposed to arbitrary history-based reward functions, is motivated by several factors. First, disciplines such as computer science, psychology, biology, and economics typically rely on a notion of reward as a numerical proxy for the immediate worth of states of affairs (such as the financial cost of buying a solar panel or the fitness benefits of a phenotype). Given an appropriate way to describe states of affairs, Markov reward functions can represent immediate worth in an intuitive manner that also allows for reasoning about combinations, sequences, or re-occurrences of such states of affairs. Second, it is not clear that general history-based rewards are a reasonable target for learning as they suffer from the curse of dimensionality in the length of the history. Lastly, Markov reward functions are the standard in RL. A rigorous analysis of which tasks they can and cannot convey may provide guidance into when it is necessary to draw on alternative formulations of a problem. Given our focus on Markov rewards, we treat a reward function as accurately expressing a task just when the value function it induces in an environment adheres to the constraints of a given task.
#### 3. Main Results.
We find that, for all three task types, there are environment–task pairs for which there is no Markov reward function that realizes the task ([Theorem 4.1](#S4.Thmtheorem1 "Theorem 4.1. ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward")). In light of this finding, we design polynomial-time algorithms that can determine, for any given task and environment, whether a reward function exists in the environment that captures the task ([Theorem 4.3](#S4.Thmtheorem3 "Theorem 4.3. ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward")). When such a reward function does exist, the algorithms also return it. Finally, we conduct simple experiments with these procedures to provide empirical insight into the expressivity of reward ([Section 5](#S5 "5 Experiments ‣ On the Expressivity of Markov Reward")).
Collectively, our results demonstrate that there are tasks that cannot be expressed by Markov reward in a rigorous sense, but we can efficiently construct such reward functions when they do exist (and determine when they do not). We take these findings to shed light on the nature of reward maximization as a principle, and highlight many pathways for further investigation.
2 Background
-------------
RL defines the problem facing an agent that learns to improve its behavior over time by interacting with its environment. We make the typical assumption that the RL problem is well modeled by an agent interacting with a finite Markov Decision Process (MDP), defined by the tuple (𝒮,𝒜,R,T,γ,s0)𝒮𝒜𝑅𝑇𝛾subscript𝑠0(\mathcal{S},\mathcal{A},R,T,\gamma,s\_{0})( caligraphic\_S , caligraphic\_A , italic\_R , italic\_T , italic\_γ , italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ). An MDP gives rise to deterministic behavioral policies, π:𝒮→𝒜:𝜋→𝒮𝒜\pi:\mathcal{S}\rightarrow\mathcal{A}italic\_π : caligraphic\_S → caligraphic\_A, and the value, Vπ:𝒮→ℝ:superscript𝑉𝜋→𝒮ℝV^{\pi}:\mathcal{S}\rightarrow\mathbb{R}italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT : caligraphic\_S → blackboard\_R, and action–value, Qπ:𝒮×𝒜→ℝ:superscript𝑄𝜋→𝒮𝒜ℝQ^{\pi}:\mathcal{S}\times\mathcal{A}\rightarrow\mathbb{R}italic\_Q start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT : caligraphic\_S × caligraphic\_A → blackboard\_R, functions that measure their quality. We will refer to a Controlled Markov Process (CMP) as an MDP without a reward function, which we denote E𝐸Eitalic\_E for environment. We assume that all reward functions are deterministic, and may be a function of either state, state-action pairs, or state-action-state triples, but not history. Henceforth, we simply use “reward function” to refer to a deterministic Markov reward function for brevity, but note that more sophisticated settings beyond MDPs and deterministic Markov reward functions are important directions for future work. For more on MDPs or RL, see the books by Puterman ([2014](#bib.bib41)) and Sutton and Barto ([2018](#bib.bib54)) respectively.
###
2.1 Other Perspectives on Reward
We here briefly summarize relevant literature that provides distinct perspectives on reward.
#### Two Roles of Reward.
As Sorg ([2011](#bib.bib50)) identifies (Chapter 2), reward can both define the task the agent learns to solve, and define the “bread crumbs” that allow agents to efficiently learn to solve the task. This distinction has been raised elsewhere Ackley and Littman ([1992](#bib.bib2)); Singh et al. ([2009](#bib.bib46), [2010](#bib.bib47)), and is similar to the extrinsic-intrinsic reward divide Singh et al. ([2005](#bib.bib45)); Zheng et al. ([2020](#bib.bib66)). Tools such as reward design Mataric ([1994](#bib.bib34)); Sorg et al. ([2010](#bib.bib51)) or reward shaping Ng et al. ([1999](#bib.bib36)) focus on offering more efficient learning in a variety of environments, so as to avoid issues of sparsity and long-term credit assignment. We concentrate primarily on reward’s capacity to express a task, and defer learning dynamics to an (important) stage of future work.
#### Discounts, Expectations, and Rationality.
Another important facet of reward is how it is used in producing behavior. The classical view offered by the Bellman equation (and the reward hypothesis) is that the quantity of interest to maximize is expected, discounted, cumulative reward. Yet it is possible to disentangle reward from the expectation Bellemare et al. ([2017](#bib.bib5)), to attend only to ordinal Weng ([2011](#bib.bib60)) or maximal rewards Krishna Gottipati et al. ([2020](#bib.bib26)), or to adopt different forms of discounting White ([2017](#bib.bib61)); Fedus et al. ([2019](#bib.bib11)). In this work, we take the standard view that agents will seek to maximize value for a particular discount factor γ𝛾\gammaitalic\_γ, but recognize that there are interesting directions beyond these commitments, such as inspecting the limits of reward in constrained MDPs as studied by Szepesvári ([2020](#bib.bib56)). We also note the particular importance of work by Pitis ([2019](#bib.bib40)), who examines the relationship between classical decision theory von Neumann and Morgenstern ([1953](#bib.bib59)) and MDPs by incorporating additional axioms that account for stochastic processes with discounting Koopmans ([1960](#bib.bib24)); Mitten ([1974](#bib.bib35)); Sobel ([1975](#bib.bib48), [2013](#bib.bib49)). Drawing inspiration from Pitis ([2019](#bib.bib40)) and Sunehag and Hutter ([2011](#bib.bib52)), we foresee valuable pathways for future work that further makes contact between RL and various axioms of rationality.
#### Preferences.
In place of numerical rewards, preferences of different kinds may be used to evaluate an agent’s behaviors, drawing from the literature on preference-learning Kreps ([1988](#bib.bib25)) and ordinal dynamic programming Debreu ([1954](#bib.bib8)); Mitten ([1974](#bib.bib35)); Sobel ([1975](#bib.bib48)). This premise gives rise to preference-based reinforcement learning (PbRL) in which an agent interacts with a CMP and receives evaluative signals in the form of preferences over states, actions, or trajectories. This kind of feedback inspires and closely parallels the task types we propose in this work. A comprehensive survey of PbRL by Wirth et al. ([2017](#bib.bib64)) identifies critical differences in this setup from traditional RL, categorizes recent algorithmic approaches, and highlights important open questions. Recent work focuses on analysing the sample efficiency of such methods Xu et al. ([2020](#bib.bib65)); Novoseller et al. ([2020](#bib.bib38)) with close connections to learning from human feedback in real time Knox and Stone ([2009](#bib.bib23)); MacGlashan et al. ([2016](#bib.bib32)); Christiano et al. ([2017](#bib.bib7)).
#### Teaching and Inverse RL.
The inverse RL (IRL) and apprenticeship learning literature examine the problem of learning directly from behavior Ng et al. ([2000](#bib.bib37)); Abbeel and Ng. ([2004](#bib.bib1)). The classical problem of IRL is to identify which reward function (often up to an equivalence class) a given demonstrator is optimizing. We emphasize the relevance of two approaches: First, work by Syed et al. ([2008](#bib.bib55)), who first illustrate the applicability of linear programming Karmarkar ([1984](#bib.bib22)) to apprenticeship learning; and second, work by Amin et al. ([2017](#bib.bib4)), who examine the repeated form of IRL. The methods of IRL have recently been expanded to include variations of cooperative IRL Hadfield-Menell et al. ([2016](#bib.bib14)), and assistive learning Shah et al. ([2021](#bib.bib43)), which offer different perspectives on how to frame interactive learning problems.
#### Reward Misspecification.
Reward is also notoriously hard to specify. As pointed out by Littman et al. ([2017](#bib.bib30)), “putting a meaningful dollar figure on scuffing a wall or dropping a clean fork is challenging.” Along these lines, Hadfield-Menell et al. ([2017b](#bib.bib16)) identify cases in which well-intentioned designers create reward functions that produce unintended behavior Ortega et al. ([2018](#bib.bib39)). MacGlashan et al. ([2017](#bib.bib33)) find that human-provided rewards tend to depend on a learning agent’s entire policy, rather than just the current state. Further, work by Hadfield-Menell et al. ([2017a](#bib.bib15)) and Kumar et al. ([2020](#bib.bib27)) suggest that there are problems with reward as a learning mechanism due to misspecification and reward tampering Everitt et al. ([2017](#bib.bib10)). These problems have given rise to approaches to reward learning, in which a reward function is inferred from some evidence such as behavior or comparisons thereof Jeon et al. ([2020](#bib.bib20)).
#### Other Notions of Task.
As a final note, we highlight alternative approaches to task specification. Building on the Free Energy Principle Friston et al. ([2009](#bib.bib13)); Friston ([2010](#bib.bib12)), Hafner et al. ([2020](#bib.bib17)) consider a variety of task types in terms of minimization of distance to a desired target distribution Akshay et al. ([2013](#bib.bib3)). Alternatively, Littman et al. ([2017](#bib.bib30)) and Li et al. ([2017](#bib.bib28)) propose variations of linear temporal logic (LTL) as a mechanism for specifying a task to RL agents, with related literature extending LTL to the multi-task Toro Icarte et al. ([2018](#bib.bib58)) and multi-agent Hammond et al. ([2021](#bib.bib18)) settings, or using reward machines for capturing task structure Icarte et al. ([2018](#bib.bib19)). Jothimurugan et al. ([2020](#bib.bib21)) take a similar approach and propose a task specification language for RL based on logical formulas that evaluate whether trajectories satisfy the task, similar in spirit to the logical task compositions framework developed by Tasse et al. ([2020](#bib.bib57)). Many of these notions of task are more general than those we consider. A natural direction for future work broadens our analysis to include these kinds of task.
3 An Account of Reward’s Expressivity: The TaskQ and ExpressionQ
-----------------------------------------------------------------
Consider an onlooker, Alice, and an earnest learning agent, Bob, engaged in the interaction pictured in [Figure 1](#S1.F1 "Figure 1 ‣ 1. An Account of “Task”. ‣ 1 Introduction ‣ On the Expressivity of Markov Reward"). Suppose that Alice has a particular task in mind that she would like Bob to learn to solve, and that Alice constructs a reward function to incentivize Bob to pursue this task. Here, Alice is playing the role of “all of what we mean by goals and purposes” for Bob to pursue, with Bob playing the role of the standard reward-maximizing RL agent.
#### Two Questions About Task.
To give us leverage to study the expressivity of reward, it is useful to draw a distinction between two stages of this process: 1) Alice thinks of a task that she would like Bob to learn to solve, and 2) Alice creates a reward function (and perhaps chooses γ𝛾\gammaitalic\_γ) that conveys the chosen task to Bob. We inspect these two separately, framed by the following two questions. The first we call the task-definition question (TaskQ) which asks: What is a task? The second we call the task-expression question (ExpressionQ) which asks: Which learning signal can be used as a mechanism for expressing any task to Bob?
#### Reward Answers The ExpressionQ.
We suggest that it may be useful to treat reward as an answer to the ExpressionQ rather than the TaskQ. On this view, reward is treated as an expressive language for incentivizing reward-maximizing agents: Alice may attempt to translate any task into a reward function that incentivizes Bob to pursue the task, no matter which environment Bob inhabits, which task Alice has chosen, or how she has represented the task to herself.
Indeed, it might be the case that Alice’s knowledge of the task far exceeds Bob’s representational or perceptual capacity. Alice may know every detail of the environment and define the task based on this holistic vantage, while Bob must learn to solve the task through interaction alone, relying only on a restricted class of functions for modeling and decision making.
Under this view, we can assess the expressivity of reward as an answer to the ExpressionQ conditioned on how we answer the TaskQ.
For example, if the TaskQ is answered in terms of natural language descriptions of desired states of affairs, then reward may fail to convey the chosen task due to the apparent mismatch in abstraction between natural language and reward (though some work has studied such a proposal MacGlashan et al. ([2015](#bib.bib31)); Williams et al. ([2018](#bib.bib62))).
###
3.1 Answers to the TaskQ: What is a Task?
In RL, tasks are often associated with a choice of goal, reward function (R𝑅Ritalic\_R), reward-discount pair (R,γ𝑅𝛾R,\gammaitalic\_R , italic\_γ), or perhaps a choice of optimal policy (alongside those task types surveyed previously, such as LTL). However, it is unclear whether these constructs capture the entirety of what we mean by “task”.
For example, consider the Russell and Norvig ([1994](#bib.bib42)) grid world: A 4×\times×3 grid with one wall, one terminal fire state, and one terminal goal state (pictured with a particular reward function in [Figure 4a](#S5.F4.sf1 "4a ‣ Figure 4 ‣ Learning with SOAP-designed Rewards. ‣ 5 Experiments ‣ On the Expressivity of Markov Reward")). In such an environment, how might we think about tasks? A standard view is that the task is to reach the goal as quickly as possible. This account, however, fails to distinguish between the non-optimal behaviors, such as the costly behavior of the agent moving directly into the fire and the neutral behavior of the agent spending its existence in the start state. Indeed, characterizing a task in terms of choice of π\*superscript𝜋\pi^{\*}italic\_π start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT or goal fails to capture these distinctions. Our view is that a suitably rich account of task should allow for the characterization of this sort of preference, offering the flexibility to scale from specifying only the desirable behavior (or outcomes) to an arbitrary ordering over behaviors (or outcomes).
In light of these considerations, we propose three answers to the TaskQ that can convey general preferences over behavior or outcome: 1) A set of acceptable policies, 2) A partial ordering over policies, or 3) A partial ordering over trajectories. We adopt these three as they can capture many kinds of task while also allowing a great deal of flexibility in the level of detail of the specification.
###
3.2 SOAPs, POs, and TOs
#### (SOAP) Set Of Acceptable Policies.
A classical view of the equivalence of two reward functions is based on the optimal policies they induce. For instance, Ng et al. ([1999](#bib.bib36)) develop potential-based reward shaping by inspecting which shaped reward signals will ensure that the optimal policy is unchanged. Extrapolating, it is natural to say that for any environment E𝐸Eitalic\_E, two reward functions are equivalent if the optimal policies they induce in E𝐸Eitalic\_E are the same. In this way, a task is viewed as a choice of optimal policy. As discussed in the grid world example above, this notion of task fails to allow for the specification of the quality of other behaviors. For this reason, we generalize task-as-optimal-policy to a set of acceptable policies, defined as follows.
######
Definition 3.1.
A set of acceptable policies (SOAP) is a non-empty subset of the deterministic policies, ΠG⊆Πsubscriptnormal-Π𝐺normal-Π\Pi\_{G}\subseteq\Piroman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT ⊆ roman\_Π, with Πnormal-Π\Piroman\_Π the set of all deterministic mappings from 𝒮𝒮\mathcal{S}caligraphic\_S to 𝒜𝒜\mathcal{A}caligraphic\_A for a given E𝐸Eitalic\_E.
With one task type defined, it is important to address what it means for a reward function to properly realize, express, or capture a task in a given environment. We offer the following account.
######
Definition 3.2.
A reward function is said to realize a task 𝒯𝒯\mathscr{T}script\_T in an environment E𝐸Eitalic\_E just when the start-state value (or return) induced by the reward function exactly adheres to the constraints of 𝒯𝒯\mathscr{T}script\_T.
Precise conditions for the realization of each task type are provided alongside each task definition, with a summary presented in column four of [Table 1](#S3.T1 "Table 1 ‣ (SOAP) Set Of Acceptable Policies. ‣ 3.2 SOAPs, POs, and TOs ‣ 3 An Account of Reward’s Expressivity: The TaskQ and ExpressionQ ‣ On the Expressivity of Markov Reward").
For SOAPs, we take the start-state value Vπ(s0)superscript𝑉𝜋subscript𝑠0V^{\pi}(s\_{0})italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) to be the mechanism by which a reward function realizes a SOAP. That is, for a given E𝐸Eitalic\_E and ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT, a reward function R𝑅Ritalic\_R is said to realize the ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT in E𝐸Eitalic\_E when the start-state value function is optimal for all good policies, and strictly higher than the start-state value of all other policies. It is clear that SOAP strictly generalizes a task in terms of a choice of optimal policy, as captured by the SOAP ΠG={π\*}subscriptΠ𝐺superscript𝜋\Pi\_{G}=\{\pi^{\*}\}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT = { italic\_π start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT }.
We note that there are two natural ways for a reward function to realize a SOAP: First, each πg∈ΠGsubscript𝜋𝑔subscriptΠ𝐺\pi\_{g}\in\Pi\_{G}italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT has optimal start-state value and all other policies are sub-optimal. We call this type equal-SOAP, or just SOAP for brevity. Alternatively, we might only require that the acceptable policies are each near-optimal, but are allowed to differ in start-state value so long as they are all better than every bad policy πb∈ΠBsubscript𝜋𝑏subscriptΠ𝐵\pi\_{b}\in\Pi\_{B}italic\_π start\_POSTSUBSCRIPT italic\_b end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_B end\_POSTSUBSCRIPT. That is, in this second kind, there exists an ϵ≥0italic-ϵ0\epsilon\geq 0italic\_ϵ ≥ 0 such that every πg∈ΠGsubscript𝜋𝑔subscriptΠ𝐺\pi\_{g}\in\Pi\_{G}italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT is ϵitalic-ϵ\epsilonitalic\_ϵ-optimal in start-state value, V\*(s0)−Vπg(s0)≤ϵ,superscript𝑉subscript𝑠0superscript𝑉subscript𝜋𝑔subscript𝑠0italic-ϵV^{\*}(s\_{0})-V^{\pi\_{g}}(s\_{0})\leq\epsilon,italic\_V start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) - italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) ≤ italic\_ϵ , while all other policies are worse. We call this second realization condition range-SOAP. We note that the range realization generalizes the equal one: Every equal-SOAP is a range-SOAP (by letting ϵ=0italic-ϵ0\epsilon=0italic\_ϵ = 0). However, there exist range-SOAPs that are expressible by Markov rewards that are not realizable as an equal-SOAP. We illustrate this fact with the following proposition. All proofs are presented in [Appendix B](#A2 "Appendix B Proofs ‣ On the Expressivity of Markov Reward").
######
Proposition 3.1.
There exists a CMP, E𝐸Eitalic\_E, and choice of ΠGsubscriptnormal-Π𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT such that ΠGsubscriptnormal-Π𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT can be realized under the range-SOAP criterion, but cannot be realized under the equal-SOAP criterion.
One such CMP is pictured [Figure 2b](#S4.F2.sf2 "2b ‣ Figure 2 ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward"). Consider the SOAP ΠG={π11,π12,π21}subscriptΠ𝐺subscript𝜋11subscript𝜋12subscript𝜋21\Pi\_{G}=\{\pi\_{11},\pi\_{12},\pi\_{21}\}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT = { italic\_π start\_POSTSUBSCRIPT 11 end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT 12 end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT 21 end\_POSTSUBSCRIPT }: Under the equal-SOAP criterion, if each of these three policies are made optimal, any reward function will also make π22subscript𝜋22\pi\_{22}italic\_π start\_POSTSUBSCRIPT 22 end\_POSTSUBSCRIPT (the only bad policy) optimal as well. In contrast, for the range criterion, we can choose a reward function that assigns lower rewards to a2subscript𝑎2a\_{2}italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT than a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT in both states. In general, we take the equal-SOAP realization as canonical, as it is naturally subsumed by our next task type.
| Name | Notation | Generalizes | Constraints Induced by 𝒯𝒯\mathscr{T}script\_T |
| --- | --- | --- | --- |
| SOAP | ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT | task-as-π\*superscript𝜋\pi^{\*}italic\_π start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT | equal: Vπg(s0)=Vπg′(s0)>Vπb(s0),∀πg,πg′∈ΠG,πb∈ΠBformulae-sequencesuperscript𝑉subscript𝜋𝑔subscript𝑠0superscript𝑉subscript𝜋superscript𝑔′subscript𝑠0superscript𝑉subscript𝜋𝑏subscript𝑠0subscriptfor-allformulae-sequencesubscript𝜋𝑔subscript𝜋superscript𝑔′
subscriptΠ𝐺subscript𝜋𝑏subscriptΠ𝐵V^{\pi\_{g}}(s\_{0})=V^{\pi\_{g^{\prime}}}(s\_{0})>V^{\pi\_{b}}(s\_{0}),\forall\_{\pi\_{g},\pi\_{g^{\prime}}\in\Pi\_{G},\pi\_{b}\in\Pi\_{B}}italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) = italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_g start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) > italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_b end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) , ∀ start\_POSTSUBSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT italic\_g start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT italic\_b end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_B end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT |
| range: Vπg(s0)>Vπb(s0),∀πg∈ΠG,πb∈ΠBsuperscript𝑉subscript𝜋𝑔subscript𝑠0superscript𝑉subscript𝜋𝑏subscript𝑠0subscriptfor-allformulae-sequencesubscript𝜋𝑔subscriptΠ𝐺subscript𝜋𝑏subscriptΠ𝐵V^{\pi\_{g}}(s\_{0})>V^{\pi\_{b}}(s\_{0}),\forall\_{\pi\_{g}\in\Pi\_{G},\pi\_{b}\in\Pi\_{B}}italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) > italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_b end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) , ∀ start\_POSTSUBSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT italic\_b end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_B end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT |
| PO | LΠsubscript𝐿ΠL\_{\Pi}italic\_L start\_POSTSUBSCRIPT roman\_Π end\_POSTSUBSCRIPT | SOAP | (π1⊕π2)∈LΠ⟹Vπ1(s0)⊕Vπ2(s0)direct-sumsubscript𝜋1subscript𝜋2subscript𝐿Πdirect-sumsuperscript𝑉subscript𝜋1subscript𝑠0superscript𝑉subscript𝜋2subscript𝑠0(\pi\_{1}\oplus\pi\_{2})\in L\_{\Pi}\implies V^{\pi\_{1}}(s\_{0})\oplus V^{\pi\_{2}}(s\_{0})( italic\_π start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ⊕ italic\_π start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) ∈ italic\_L start\_POSTSUBSCRIPT roman\_Π end\_POSTSUBSCRIPT ⟹ italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) ⊕ italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) |
| TO | Lτ,Nsubscript𝐿𝜏𝑁L\_{\tau,N}italic\_L start\_POSTSUBSCRIPT italic\_τ , italic\_N end\_POSTSUBSCRIPT | task-as-goal | (τ1⊕τ2)∈Lτ,N⟹G(τ1;s0)⊕G(τ2;s0)direct-sumsubscript𝜏1subscript𝜏2subscript𝐿𝜏𝑁direct-sum𝐺subscript𝜏1subscript𝑠0𝐺subscript𝜏2subscript𝑠0(\tau\_{1}\oplus\tau\_{2})\in L\_{\tau,N}\implies G(\tau\_{1};s\_{0})\oplus G(\tau\_{2};s\_{0})( italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ⊕ italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) ∈ italic\_L start\_POSTSUBSCRIPT italic\_τ , italic\_N end\_POSTSUBSCRIPT ⟹ italic\_G ( italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ; italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) ⊕ italic\_G ( italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ; italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) |
Table 1: A summary of the three proposed task types. We further list the constraints that determine whether a reward function realizes each task type in an MDP, where we take ⊕direct-sum\oplus⊕ to be one of ‘<<<’, ‘>>>’, or ‘===’, and G𝐺Gitalic\_G is the discounted return of the trajectory.
#### (PO) Partial Ordering on Policies.
Next, we suppose that Alice chooses a partial ordering on the deterministic policy space. That is, Alice might identify a some great policies, some good, and some bad policies to strictly avoid, and remain indifferent to the rest. POs strictly generalize equal SOAPs, as any such SOAP is a special choice of PO with only two equivalence classes. We offer the following definition of a PO.
######
Definition 3.3.
A policy order (PO) of the deterministic policies Πnormal-Π\Piroman\_Π is a partial order, denoted LΠsubscript𝐿normal-ΠL\_{\Pi}italic\_L start\_POSTSUBSCRIPT roman\_Π end\_POSTSUBSCRIPT.
As with SOAPs, we take the start-state value Vπ(s0)superscript𝑉𝜋subscript𝑠0V^{\pi}(s\_{0})italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) induced by a reward function R𝑅Ritalic\_R as the mechanism by which policies are ordered. That is, given E𝐸Eitalic\_E and LΠsubscript𝐿ΠL\_{\Pi}italic\_L start\_POSTSUBSCRIPT roman\_Π end\_POSTSUBSCRIPT, we say that a reward function R𝑅Ritalic\_R realizes LΠsubscript𝐿ΠL\_{\Pi}italic\_L start\_POSTSUBSCRIPT roman\_Π end\_POSTSUBSCRIPT in E𝐸Eitalic\_E if and only if the resulting MDP, M=(E,R)𝑀𝐸𝑅M=(E,R)italic\_M = ( italic\_E , italic\_R ), produces a start-state value function that orders ΠΠ\Piroman\_Π according to LΠsubscript𝐿ΠL\_{\Pi}italic\_L start\_POSTSUBSCRIPT roman\_Π end\_POSTSUBSCRIPT.
#### (TO) Partial Ordering on Trajectories.
A natural generalization of goal specification enriches a notion of task to include the details of how a goal is satisfied—that is, for Alice to relay some preference over trajectory space Wilson et al. ([2012](#bib.bib63)), as is done in preference based RL Wirth et al. ([2017](#bib.bib64)). Concretely, we suppose Alice specifies a partial ordering on length N𝑁Nitalic\_N trajectories of (s,a)𝑠𝑎(s,a)( italic\_s , italic\_a ) pairs, defined as follows.
######
Definition 3.4.
A trajectory ordering (TO) of length N∈ℕ𝑁ℕN\in\mathbb{N}italic\_N ∈ blackboard\_N is a partial ordering Lτ,Nsubscript𝐿𝜏𝑁L\_{\tau,N}italic\_L start\_POSTSUBSCRIPT italic\_τ , italic\_N end\_POSTSUBSCRIPT, with each trajectory τ𝜏\tauitalic\_τ consisting of N𝑁Nitalic\_N state–action pairs, {(s0,a0),…,(aN−1,sN−1)}subscript𝑠0subscript𝑎0normal-…subscript𝑎𝑁1subscript𝑠𝑁1\{(s\_{0},a\_{0}),\ldots,(a\_{N-1},s\_{N-1})\}{ ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) , … , ( italic\_a start\_POSTSUBSCRIPT italic\_N - 1 end\_POSTSUBSCRIPT , italic\_s start\_POSTSUBSCRIPT italic\_N - 1 end\_POSTSUBSCRIPT ) }, with s0subscript𝑠0s\_{0}italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT the start state.
As with PO, we say that a reward function realizes a trajectory ordering Lτ,Nsubscript𝐿𝜏𝑁L\_{\tau,N}italic\_L start\_POSTSUBSCRIPT italic\_τ , italic\_N end\_POSTSUBSCRIPT if the ordering determined by each trajectory’s cumulative discounted N𝑁Nitalic\_N-step return from s0subscript𝑠0s\_{0}italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT, denoted G(τ;s0)𝐺𝜏subscript𝑠0G(\tau;s\_{0})italic\_G ( italic\_τ ; italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ), matches that of the given Lτ,Nsubscript𝐿𝜏𝑁L\_{\tau,N}italic\_L start\_POSTSUBSCRIPT italic\_τ , italic\_N end\_POSTSUBSCRIPT. We note that trajectory orderings can generalize goal-based tasks at the expense of a larger specification. For instance, a TO can convey the task, “Safely reach the goal in less than thirty steps, or just get to the subgoal in less than twenty steps.”
#### Recap.
We propose to assess the expressivity of reward by first answering the TaskQ in terms of SOAPs, POs, or TOs, as summarized by [Table 1](#S3.T1 "Table 1 ‣ (SOAP) Set Of Acceptable Policies. ‣ 3.2 SOAPs, POs, and TOs ‣ 3 An Account of Reward’s Expressivity: The TaskQ and ExpressionQ ‣ On the Expressivity of Markov Reward"). We say that a task 𝒯𝒯\mathscr{T}script\_T is realized in an environment E𝐸Eitalic\_E under reward function R𝑅Ritalic\_R if the start-state value function (or return) produced by R𝑅Ritalic\_R imposes the constraints specified by 𝒯𝒯\mathscr{T}script\_T, and are interested in whether reward can always realize a given task in any choice of E𝐸Eitalic\_E. We make a number of assumptions along the way, including: (1) Reward functions are Markov and deterministic, (2) Policies of interest are deterministic, (3) The environment is a finite CMP, (4) γ𝛾\gammaitalic\_γ is part of the environment, (5) We ignore reward’s role in shaping the learning process, (6) Start-state value or return is the appropriate mechanism to determine if a reward function realizes a given task. Relaxation of these assumptions is a critical direction for future work.
4 Analysis: The Expressivity of Markov Reward
----------------------------------------------
With our definitions and objectives in place, we now present our main results.
###
4.1 Express SOAPs, POs, and TOs
We first ask whether reward can always realize a given SOAP, PO, or TO, for an arbitrary E𝐸Eitalic\_E. Our first result states that the answer is “no”—there are tasks that cannot be realized by any reward function.
######
Theorem 4.1.
For each of SOAP, PO, and TO, there exist (E,𝒯)𝐸𝒯(E,\mathscr{T})( italic\_E , script\_T ) pairs for which no Markow reward function realizes 𝒯𝒯\mathscr{T}script\_T in E𝐸Eitalic\_E.
Thus, reward is incapable of capturing certain tasks. What tasks are they, precisely? Intuitively, inexpressible tasks involve policies or trajectories that must be correlated in value in an MDP. That is, if two policies are nearly identical in behavior, it is unlikely that reward can capture the PO that places them at opposite ends of the ordering. A simple example is the “always move the same direction” task in a grid world, with state defined as an (x,y)𝑥𝑦(x,y)( italic\_x , italic\_y ) pair. The SOAP ΠG={π←,π↑,π→,π↓}subscriptΠ𝐺subscript𝜋←subscript𝜋↑subscript𝜋→subscript𝜋↓\Pi\_{G}=\{\pi\_{\leftarrow},\pi\_{\uparrow},\pi\_{\rightarrow},\pi\_{\downarrow}\}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT = { italic\_π start\_POSTSUBSCRIPT ← end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT ↑ end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT → end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT ↓ end\_POSTSUBSCRIPT } conveys this task, but no Markov reward function can make these policies strictly higher in value than all others.

(a) Steady State Case

(b) Entailment Case
Figure 2: Two CMPs in which there is a SOAP that is not expressible under any Markov reward function. On the left, ΠG={π21}subscriptΠ𝐺subscript𝜋21\Pi\_{G}=\{\pi\_{21}\}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT = { italic\_π start\_POSTSUBSCRIPT 21 end\_POSTSUBSCRIPT } is not realizable, as π21subscript𝜋21\pi\_{21}italic\_π start\_POSTSUBSCRIPT 21 end\_POSTSUBSCRIPT can not be made better than π22subscript𝜋22\pi\_{22}italic\_π start\_POSTSUBSCRIPT 22 end\_POSTSUBSCRIPT because s1subscript𝑠1s\_{1}italic\_s start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is never reached. On the right, the XOR-like-SOAP, ΠG={π12,π21}subscriptΠ𝐺subscript𝜋12subscript𝜋21\Pi\_{G}=\{\pi\_{12},\pi\_{21}\}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT = { italic\_π start\_POSTSUBSCRIPT 12 end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT 21 end\_POSTSUBSCRIPT } is not realizable: To make these two policies optimal, it is entailed that π22subscript𝜋22\pi\_{22}italic\_π start\_POSTSUBSCRIPT 22 end\_POSTSUBSCRIPT and π11subscript𝜋11\pi\_{11}italic\_π start\_POSTSUBSCRIPT 11 end\_POSTSUBSCRIPT must be optimal, too.
#### Example: Inexpressible SOAPs.
Observe the two CMPs pictured in [Figure 2](#S4.F2 "Figure 2 ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward"), depicting two kinds of inexpressible SOAPs. On the left, we consider the SOAP ΠG={π21}subscriptΠ𝐺subscript𝜋21\Pi\_{G}=\{\pi\_{21}\}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT = { italic\_π start\_POSTSUBSCRIPT 21 end\_POSTSUBSCRIPT }, containing only the policy that executes a2subscript𝑎2a\_{2}italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT in the left state (s0subscript𝑠0s\_{0}italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT), and a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT in the right (s1subscript𝑠1s\_{1}italic\_s start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT). This SOAP is inexpressible through reward, but only because reward cannot distinguish the start-state value of π21subscript𝜋21\pi\_{21}italic\_π start\_POSTSUBSCRIPT 21 end\_POSTSUBSCRIPT and π22subscript𝜋22\pi\_{22}italic\_π start\_POSTSUBSCRIPT 22 end\_POSTSUBSCRIPT since the policies differ only in an unreachable state. This is reminiscent of Axiom 5 from Pitis ([2019](#bib.bib40)), which explicitly excludes preferences of this sort. On the right, we find a more interesting case: The chosen SOAP is similar to the XOR function, ΠG={π12,π21}subscriptΠ𝐺subscript𝜋12subscript𝜋21\Pi\_{G}=\{\pi\_{12},\pi\_{21}\}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT = { italic\_π start\_POSTSUBSCRIPT 12 end\_POSTSUBSCRIPT , italic\_π start\_POSTSUBSCRIPT 21 end\_POSTSUBSCRIPT }. Here, the task requires that the agent choose each action in exactly one state. However, there cannot exist a reward function that makes only these policies optimal, as by consequence, both policies π11subscript𝜋11\pi\_{11}italic\_π start\_POSTSUBSCRIPT 11 end\_POSTSUBSCRIPT and π22subscript𝜋22\pi\_{22}italic\_π start\_POSTSUBSCRIPT 22 end\_POSTSUBSCRIPT must be optimal as well.
Next, we show that [Theorem 4.1](#S4.Thmtheorem1 "Theorem 4.1. ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") is not limited to a particular choice of transition function or γ𝛾\gammaitalic\_γ.
######
Proposition 4.2.
There exist choices of E¬T=(𝒮,𝒜,γ,s0)subscript𝐸𝑇𝒮𝒜𝛾subscript𝑠0E\_{\neg T}=(\mathcal{S},\mathcal{A},\gamma,s\_{0})italic\_E start\_POSTSUBSCRIPT ¬ italic\_T end\_POSTSUBSCRIPT = ( caligraphic\_S , caligraphic\_A , italic\_γ , italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) or E¬γ=(𝒮,𝒜,T,s0)subscript𝐸𝛾𝒮𝒜𝑇subscript𝑠0E\_{\neg\gamma}=(\mathcal{S},\mathcal{A},T,s\_{0})italic\_E start\_POSTSUBSCRIPT ¬ italic\_γ end\_POSTSUBSCRIPT = ( caligraphic\_S , caligraphic\_A , italic\_T , italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ), together with a task 𝒯𝒯\mathscr{T}script\_T, such that there is no (T,R)𝑇𝑅(T,R)( italic\_T , italic\_R ) pair that realizes 𝒯𝒯\mathscr{T}script\_T in E¬Tsubscript𝐸𝑇E\_{\neg T}italic\_E start\_POSTSUBSCRIPT ¬ italic\_T end\_POSTSUBSCRIPT or (R,γ)𝑅𝛾(R,\gamma)( italic\_R , italic\_γ ) in E¬γsubscript𝐸𝛾E\_{\neg\gamma}italic\_E start\_POSTSUBSCRIPT ¬ italic\_γ end\_POSTSUBSCRIPT.
This result suggests that the scope of [Theorem 4.1](#S4.Thmtheorem1 "Theorem 4.1. ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") is actually quite broad—even if the transition function or γ𝛾\gammaitalic\_γ are taken as part of the reward specification, there are tasks that cannot be expressed. We suspect there are ways to give a precise characterization of all inexpressible tasks from an axiomatic perspective, which we hope to study in future work.
###
4.2 Constructive Algorithms: Task to Reward
We now analyze how to determine whether an appropriate reward function can be constructed for any (E,𝒯)𝐸𝒯(E,\mathscr{T})( italic\_E , script\_T ) pair. We pose a general form of the reward-design problem Mataric ([1994](#bib.bib34)); Sorg et al. ([2010](#bib.bib51)); Dewey ([2014](#bib.bib9)) as follows.
######
Definition 4.1.
The RewardDesign problem is: Given E=(𝒮,𝒜,T,γ,s0)𝐸𝒮𝒜𝑇𝛾subscript𝑠0E=(\mathcal{S},\mathcal{A},T,\gamma,s\_{0})italic\_E = ( caligraphic\_S , caligraphic\_A , italic\_T , italic\_γ , italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ), and a 𝒯𝒯\mathscr{T}script\_T, output a reward function R𝑎𝑙𝑖𝑐𝑒subscript𝑅𝑎𝑙𝑖𝑐𝑒R\_{\text{alice}}italic\_R start\_POSTSUBSCRIPT alice end\_POSTSUBSCRIPT that ensures 𝒯𝒯\mathscr{T}script\_T is realized in M=(E,R𝑎𝑙𝑖𝑐𝑒)𝑀𝐸subscript𝑅𝑎𝑙𝑖𝑐𝑒M=(E,R\_{\text{alice}})italic\_M = ( italic\_E , italic\_R start\_POSTSUBSCRIPT alice end\_POSTSUBSCRIPT ).
Indeed, for all three task types, there is an efficient algorithm for solving the reward-design problem.
######
Theorem 4.3.
The RewardDesign problem can be solved in polynomial time, for any finite E𝐸Eitalic\_E, and any 𝒯𝒯\mathscr{T}script\_T, so long as reward functions with infinitely many outputs are considered.
Therefore, for any choice of finite CMP, E𝐸Eitalic\_E, and a SOAP, PO, or TO, we can find a reward function that perfectly realizes the task in the given environment, if such a reward function exists. Each of the three algorithms are based on forming a linear program that matches the constraints of the given task type, which is why reward functions with infinitely many outputs are required. Pseudo-code for SOAP-based reward design is presented in [Algorithm 1](#alg1 "Algorithm 1 ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward"). Intuitively, the algorithms compute the discounted expected-state visitation distribution for a collection of policies; in the case of SOAP, for instance, these policies include ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT and what we call the “fringe”, the set of policies that differ from a πg∈ΠGsubscript𝜋𝑔subscriptΠ𝐺\pi\_{g}\in\Pi\_{G}italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT by exactly one action. Then, we use these distributions to describe linear inequality constraints ensuring that the start-state value of the good policies are better than those of the fringe.
Algorithm 1 SOAP Reward Design
Input: E=(𝒮,𝒜,T,γ,s0)𝐸𝒮𝒜𝑇𝛾subscript𝑠0E=(\mathcal{S},\mathcal{A},T,\gamma,s\_{0})italic\_E = ( caligraphic\_S , caligraphic\_A , italic\_T , italic\_γ , italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ), ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT.
Output: R𝑅Ritalic\_R, or ⟂perpendicular-to\perp⟂.
1:Πfringe=compute\_fringe(ΠG)subscriptΠfringecompute\_fringesubscriptΠ𝐺\Pi\_{\text{fringe}}=\texttt{compute\\_fringe}(\Pi\_{G})roman\_Π start\_POSTSUBSCRIPT fringe end\_POSTSUBSCRIPT = compute\_fringe ( roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT )
2:for πg,i∈ΠGsubscript𝜋𝑔𝑖subscriptΠ𝐺\pi\_{g,i}\in\Pi\_{G}italic\_π start\_POSTSUBSCRIPT italic\_g , italic\_i end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT do ▷▷\triangleright▷ Compute state-visitation distributions.
3: ρg,i=compute\_exp\_visit(πg,i,E)subscript𝜌𝑔𝑖compute\_exp\_visitsubscript𝜋𝑔𝑖𝐸\rho\_{g,i}=\texttt{compute\\_exp\\_visit}(\pi\_{g,i},E)italic\_ρ start\_POSTSUBSCRIPT italic\_g , italic\_i end\_POSTSUBSCRIPT = compute\_exp\_visit ( italic\_π start\_POSTSUBSCRIPT italic\_g , italic\_i end\_POSTSUBSCRIPT , italic\_E )
4:for πf,i∈Π𝚏𝚛𝚒𝚗𝚐𝚎subscript𝜋𝑓𝑖subscriptΠ𝚏𝚛𝚒𝚗𝚐𝚎\pi\_{f,i}\in\Pi\_{\texttt{fringe}}italic\_π start\_POSTSUBSCRIPT italic\_f , italic\_i end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT fringe end\_POSTSUBSCRIPT do
5: ρf,i=compute\_exp\_visit(πf,i,E)subscript𝜌𝑓𝑖compute\_exp\_visitsubscript𝜋𝑓𝑖𝐸\rho\_{f,i}=\texttt{compute\\_exp\\_visit}(\pi\_{f,i},E)italic\_ρ start\_POSTSUBSCRIPT italic\_f , italic\_i end\_POSTSUBSCRIPT = compute\_exp\_visit ( italic\_π start\_POSTSUBSCRIPT italic\_f , italic\_i end\_POSTSUBSCRIPT , italic\_E )
6:Ceq={}subscript𝐶eqC\_{\text{eq}}=\{\}italic\_C start\_POSTSUBSCRIPT eq end\_POSTSUBSCRIPT = { } ▷▷\triangleright▷ Make Equality Constraints.
7:for πg,i∈ΠGsubscript𝜋𝑔𝑖subscriptΠ𝐺\pi\_{g,i}\in\Pi\_{G}italic\_π start\_POSTSUBSCRIPT italic\_g , italic\_i end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT do
8: Ceq.𝚊𝚍𝚍(ρg,0(s0)⋅X=ρg,i(s0)⋅X)formulae-sequencesubscript𝐶eq𝚊𝚍𝚍⋅subscript𝜌𝑔0subscript𝑠0𝑋⋅subscript𝜌𝑔𝑖subscript𝑠0𝑋C\_{\text{eq}}.\texttt{add}(\rho\_{g,0}(s\_{0})\cdot X=\rho\_{g,i}(s\_{0})\cdot X)italic\_C start\_POSTSUBSCRIPT eq end\_POSTSUBSCRIPT . add ( italic\_ρ start\_POSTSUBSCRIPT italic\_g , 0 end\_POSTSUBSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) ⋅ italic\_X = italic\_ρ start\_POSTSUBSCRIPT italic\_g , italic\_i end\_POSTSUBSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) ⋅ italic\_X )
9:Cineq={}subscript𝐶ineqC\_{\text{ineq}}=\{\}italic\_C start\_POSTSUBSCRIPT ineq end\_POSTSUBSCRIPT = { } ▷▷\triangleright▷ Make Inequality Constraints.
10:for πf,j∈Πfringesubscript𝜋𝑓𝑗subscriptΠfringe\pi\_{f,j}\in\Pi\_{\text{fringe}}italic\_π start\_POSTSUBSCRIPT italic\_f , italic\_j end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT fringe end\_POSTSUBSCRIPT do
11: Cineq.𝚊𝚍𝚍(ρf,j(s0)⋅X+ϵ≤ρg,0(s0)⋅X)formulae-sequencesubscript𝐶ineq𝚊𝚍𝚍⋅subscript𝜌𝑓𝑗subscript𝑠0𝑋italic-ϵ⋅subscript𝜌𝑔0subscript𝑠0𝑋C\_{\text{ineq}}.\texttt{add}(\rho\_{f,j}(s\_{0})\cdot X+\epsilon\leq\rho\_{g,0}(s\_{0})\cdot X)italic\_C start\_POSTSUBSCRIPT ineq end\_POSTSUBSCRIPT . add ( italic\_ρ start\_POSTSUBSCRIPT italic\_f , italic\_j end\_POSTSUBSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) ⋅ italic\_X + italic\_ϵ ≤ italic\_ρ start\_POSTSUBSCRIPT italic\_g , 0 end\_POSTSUBSCRIPT ( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) ⋅ italic\_X )
12:Rout,ϵout=linear\_programming(obj.=maxϵ,constraints=Cineq,Ceq)subscript𝑅outsubscriptitalic-ϵout
linear\_programmingformulae-sequenceobj.italic-ϵconstraintssubscript𝐶ineqsubscript𝐶eqR\_{\text{out}},\epsilon\_{\text{out}}=\texttt{linear\\_programming}(\text{obj.}=\max\epsilon,\text{constraints}=C\_{\text{ineq}},C\_{\text{eq}})italic\_R start\_POSTSUBSCRIPT out end\_POSTSUBSCRIPT , italic\_ϵ start\_POSTSUBSCRIPT out end\_POSTSUBSCRIPT = linear\_programming ( obj. = roman\_max italic\_ϵ , constraints = italic\_C start\_POSTSUBSCRIPT ineq end\_POSTSUBSCRIPT , italic\_C start\_POSTSUBSCRIPT eq end\_POSTSUBSCRIPT ) ▷▷\triangleright▷ Solve LP.
13:if ϵout>0subscriptitalic-ϵout0\epsilon\_{\text{out}}>0italic\_ϵ start\_POSTSUBSCRIPT out end\_POSTSUBSCRIPT > 0 then ▷▷\triangleright▷ Check if successful.
return Routsubscript𝑅outR\_{\text{out}}italic\_R start\_POSTSUBSCRIPT out end\_POSTSUBSCRIPT
14:else return ⟂perpendicular-to\perp⟂
As highlighted by [Theorem 4.1](#S4.Thmtheorem1 "Theorem 4.1. ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") there are SOAPs, POs, and TOs that are not realizable. Thus, it is important to determine how the algorithms mentioned in [Theorem 4.3](#S4.Thmtheorem3 "Theorem 4.3. ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") will handle such cases. Our next corollary illustrates that the desirable outcome is achieved: For any E𝐸Eitalic\_E and 𝒯𝒯\mathscr{T}script\_T, the algorithms will output a reward function that realizes 𝒯𝒯\mathscr{T}script\_T in E𝐸Eitalic\_E, or output ‘⟂perpendicular-to\perp⟂’ when no such function exists.
######
Corollary 4.4.
For any task 𝒯𝒯\mathscr{T}script\_T and environment E𝐸Eitalic\_E, deciding whether 𝒯𝒯\mathscr{T}script\_T is expressible in E𝐸Eitalic\_E is solvable in polynomial time.
Together, [Theorem 4.1](#S4.Thmtheorem1 "Theorem 4.1. ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") and [Theorem 4.3](#S4.Thmtheorem3 "Theorem 4.3. ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") constitute our main results: There are environment–task pairs in which Markov reward cannot express the chosen task for each of SOAPs, POs, and TOs. However, there are efficient algorithms for deciding whether a task is expressible, and for constructing the realizing reward function when it exists. We will study the use of one of these algorithms in [Section 5](#S5 "5 Experiments ‣ On the Expressivity of Markov Reward"), but first attend to other aspects of reward’s expressivity.
###
4.3 Other Aspects of Reward’s Expressivity
We next briefly summarize other considerations about the expressivity of reward. As noted, [Theorem 4.3](#S4.Thmtheorem3 "Theorem 4.3. ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") requires the use of a reward function that can produce infinitely many outputs. Our next result proves this requirement is strict for efficient reward design.
######
Theorem 4.5.
A variant of the RewardDesign problem with finite reward outputs is NP-hard.
We provide further details about the precise problem studied in [Appendix B](#A2 "Appendix B Proofs ‣ On the Expressivity of Markov Reward"). Beyond reward functions with finitely-many outputs, we are also interested in extensions of our results to multiple environments. We next present a positive result indicating our algorithms can extend to the case where Alice would like to design a reward function for a single task across multiple environments.
######
Proposition 4.6.
For any SOAP, PO, or TO, given a finite set of CMPs, ℰ={E1,…,En}ℰsubscript𝐸1normal-…subscript𝐸𝑛\mathcal{E}=\{E\_{1},\ldots,E\_{n}\}caligraphic\_E = { italic\_E start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT }, with shared state–action space, there exists a polynomial time algorithm that outputs one reward function that realizes the task (when possible) in all CMPs in ℰℰ\mathcal{E}caligraphic\_E.
A natural follow up question to the above result asks whether task realization is closed under a set of CMPs. Our next result answers this question in the negative.
######
Theorem 4.7.
Task realization is not closed under sets of CMPs with shared state-action space. That is, there exist choices of 𝒯𝒯\mathscr{T}script\_T and ℰ={E1,…,En}ℰsubscript𝐸1normal-…subscript𝐸𝑛\mathcal{E}=\{E\_{1},\ldots,E\_{n}\}caligraphic\_E = { italic\_E start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_E start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } such that 𝒯𝒯\mathscr{T}script\_T is realizable in each Ei∈ℰsubscript𝐸𝑖ℰE\_{i}\in\mathcal{E}italic\_E start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ∈ caligraphic\_E independently, but there is not a single reward function that realizes 𝒯𝒯\mathscr{T}script\_T in all Ei∈ℰsubscript𝐸𝑖ℰE\_{i}\in\mathcal{E}italic\_E start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ∈ caligraphic\_E simultaneously.
Intuitively, this shows that Alice must know precisely which environment Bob will inhabit if she is to design an appropriate reward function. Otherwise, her uncertainty over E𝐸Eitalic\_E may prevent her from designing a realizing reward function. We foresee iterative extensions of our algorithms in which Alice and Bob can react to one another, drawing inspiration from repeated IRL by Amin et al. ([2017](#bib.bib4)).
5 Experiments
--------------
We next conduct experiments to shed further light on the findings of our analysis. Our focus is on SOAPs, though we anticipate the insights extend to POs and TOs as well with little complication. In the first experiment, we study the fraction of SOAPs that are expressible in small CMPs as we vary aspects of the environment or task ([Figure 3](#S5.F3 "Figure 3 ‣ 5 Experiments ‣ On the Expressivity of Markov Reward")). In the second, we use one algorithm from [Theorem 4.3](#S4.Thmtheorem3 "Theorem 4.3. ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") to design a reward function, and contrast learning curves under a SOAP-designed reward function compared to standard rewards. Full details about the experiments are found in [Appendix C](#A3 "Appendix C Experimental Details ‣ On the Expressivity of Markov Reward").

(a) Vary Num. Actions

(b) Vary Num. States

(c) Vary γ𝛾\gammaitalic\_γ

(d) Vary SOAP Size

(e) Vary Entropy of T𝑇Titalic\_T

(f) Vary the Spread of ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT
Figure 3: The approximate fraction of SOAPs that are expressible by reward in CMPs with a handful of states and actions, with 95% confidence intervals. In each plot, we vary a different parameter of the environment or task to illustrate how this change impacts the expressivity of reward, showing both equal (color) and range (grey) realization of SOAP.
#### SOAP Expressivity.
First, we estimate the fraction of SOAPs that are expressible in small environments. For each data point, we sample 200 random SOAPs and run [Algorithm 1](#alg1 "Algorithm 1 ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") described by [Theorem 4.3](#S4.Thmtheorem3 "Theorem 4.3. ‣ 4.2 Constructive Algorithms: Task to Reward ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") to determine whether each SOAP is realizable in the given CMP. We ask this question for both the equal (color) variant of SOAP realization and the range (grey) variant. We inspect SOAP expressivity as we vary six different characteristics of E𝐸Eitalic\_E or ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT: The number of actions, the number of states, the discount γ𝛾\gammaitalic\_γ, the number of good policies in each SOAP, the Shannon entropy of T𝑇Titalic\_T at each (s,a)𝑠𝑎(s,a)( italic\_s , italic\_a ) pair, and the “spread” of each SOAP. The spread approximates average edit distance among policies in ΠGsubscriptΠ𝐺\Pi\_{G}roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT determined by randomly permuting actions of a reference policy by a coin weighted according to the value on the x-axis. We use the same set of CMPs for each environment up to any deviations explicitly made by the varied parameter (such as γ𝛾\gammaitalic\_γ or entropy). Unless otherwise stated, each CMP has four states and three actions, with a fixed but randomly chosen transition function.
Results are presented in [Figure 3](#S5.F3 "Figure 3 ‣ 5 Experiments ‣ On the Expressivity of Markov Reward"). We find that our theory is borne out in a number of ways. First, as [Theorem 4.1](#S4.Thmtheorem1 "Theorem 4.1. ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward") suggests, we find SOAP expressivity is strictly less than one in nearly all cases. This is evidence that inexpressible tasks are not only found in manufactured corner cases, but rather that expressivity is a spectrum. We further observe—as predicted by [Proposition 3.1](#S3.Thmtheorem1 "Proposition 3.1. ‣ (SOAP) Set Of Acceptable Policies. ‣ 3.2 SOAPs, POs, and TOs ‣ 3 An Account of Reward’s Expressivity: The TaskQ and ExpressionQ ‣ On the Expressivity of Markov Reward")—clear separation between the expressivity of range-SOAP (grey) vs. equal-SOAP (color); there are many cases where we can find a reward function that makes the good policies near optimal and better than the bad, but cannot make those good policies all exactly optimal. Additionally, several trends emerge as we vary the parameter of environment or task, though we note that such trends are likely specific to the choice of CMP and may not hold in general. Perhaps the most striking trend is in [Figure 3f](#S5.F3.sf6 "3f ‣ Figure 3 ‣ 5 Experiments ‣ On the Expressivity of Markov Reward"), which shows a decrease in expressivity as the SOAPs become more spread out. This is quite sensible: A more spread out SOAP is likely to lead to more entailments of the kind discussed in [Figure 2b](#S4.F2.sf2 "2b ‣ Figure 2 ‣ 4.1 Express SOAPs, POs, and TOs ‣ 4 Analysis: The Expressivity of Markov Reward ‣ On the Expressivity of Markov Reward").
#### Learning with SOAP-designed Rewards.
Next, we contrast the learning performance of Q-learning under a SOAP-designed reward function (visualized in [Figure 4a](#S5.F4.sf1 "4a ‣ Figure 4 ‣ Learning with SOAP-designed Rewards. ‣ 5 Experiments ‣ On the Expressivity of Markov Reward")) with that of the regular goal-based reward in the Russell and Norvig ([1994](#bib.bib42)) grid world. In this domain, there is 0.35 slip probability such that, on a ‘slip’ event, the agent randomly applies one of the two orthogonal action effects.
The regular goal-based reward function provides +11+1+ 1 when the agent enters the terminal flag cell, and −11-1- 1 when the agent enters the terminal fire cell. The bottom left state is the start-state, and the black cell is an impassable wall.
Results are presented in [Figure 4](#S5.F4 "Figure 4 ‣ Learning with SOAP-designed Rewards. ‣ 5 Experiments ‣ On the Expressivity of Markov Reward"). On the right, we present a particular kind of learning curve contrasting the performance of Q-learning with the SOAP reward (blue) and regular reward (green). The y-axis measures, at the end of each episode, the average (inverse) minimum edit distance between Q-learning’s greedy policy and any policy in the SOAP. Thus, when the series reaches 1.0, Q-learning’s greedy policy is identical to one of the two SOAP policies. We first find that Q-learning is able to quickly learn a πg∈ΠGsubscript𝜋𝑔subscriptΠ𝐺\pi\_{g}\in\Pi\_{G}italic\_π start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT ∈ roman\_Π start\_POSTSUBSCRIPT italic\_G end\_POSTSUBSCRIPT under the designed reward function. We further observe that the typical reward does not induce a perfect match in policy—at convergence, the green curve hovers slightly below the blue, indicating that the default reward function is incentivizing different policies to be optimal. This is entirely sensible, as the two SOAP policies are extremely cautious around the fire; they choose the orthogonal (and thus, safe) action in fire-adjacent states, relying on slip probability to progress. Lastly, as expected given the amount of knowledge contained in the SOAP, the SOAP reward function allows Q-learning to rapidly identify a good policy compared to the typical reward.

(a) Grid World SOAP Reward

(b) Grid World Learning
Figure 4: A SOAP-designed reward function (left) and the resulting learning curves (right) for Q-learning compared to the traditional reward function for the Russell and Norvig ([1994](#bib.bib42)) grid world. Each series presents average performance over 50 runs of the experiment with 95% confidence intervals.
6 Conclusion
-------------
We have here investigated the expressivity of Markov reward, framed around three new accounts of task. Our main results show that there exist choices of task and environment in which Markov reward cannot express the chosen task, but there are efficient algorithms that decide whether a task is expressible and construct a reward function that captures the task when such a function exists. We conclude with an empirical examination of our analysis, corroborating the findings of our theory. We take these to be first steps toward understanding the full scope of the reward hypothesis.
There are many routes forward. A key direction moves beyond the task types we study here, and relaxes our core assumptions—the environment might not be a finite CMP, Alice may not know the environment precisely, reward may be a function of history, or Alice may not know how Bob represents state. Along similar lines, a critical direction incorporates how reward impacts Bob’s learning dynamics rather than start-state value. Further, we note the potential relevance to the recent reward-is-enough hypothesis proposed by Silver et al. ([2021](#bib.bib44)); we foresee pathways to extend our analysis to examine this newer hypothesis, too. For instance, in future work, it is important to assess whether reward is capable of inducing the right kinds of attributes of cognition, not just behavior.
Acknowledgments and Disclosure of Funding
-----------------------------------------
The authors would like to thank André Barreto, Diana Borsa, Michael Bowling, Wilka Carvalho, Brian Christian, Jess Hamrick, Steven Hansen, Zac Kenton, Ramana Kumar, Katrina McKinney, Rémi Munos, Matt Overlan, Hado van Hasselt, and Ben Van Roy for helpful discussions. We would also like to thank the anonymous reviewers for their thoughtful feedback, and Brendan O’Donoghue for catching a typo in the appendix. Michael Littman was supported in part by funding from DARPA L2M, ONR MURI, NSF FMitF, and NSF RI.
|
95483e22-2042-4a1c-a39e-5ac08e80292b
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Help me understand the rationale of the NIH to not recommend Fluvoxamine for COVID treatment.
So the TOGETHER trial signal boosted by Scott of slate star codex found Fluvoxamine to be effective at reducing 30% of COVID hospitalisation and fatality.
The NIH looked at the study and found it unconvicing, I am a bit confused as to the rationale.
I'll list it out as I understand it:
* the primary outcomes [retention in the emergency department for >6 hours or admission to a tertiary hospital] was chosen without rationale
* There was no significant difference in mortality between study arms in the intention-to-treat (ITT) population [however, it's 2% in treatment arm and 3% in placebo arm as expected of the 30% reduction expectation]
* significant difference was only found in patients who have persisted in taking >80% of fluvoxamine doses, however there were also improved outcome for patients who have persisted in taking >80% of placebo dose, suggesting that another mechanism [e.g. conscientiousness] to be resposible for [most? all?] the improvement in outcome.
Is my understanding correct and does NIH's critiques of the study hold merrit?
|
5528d267-090f-42dd-9849-eba41639c492
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Less Wrong Montreal - Easy Lifehacks
Discussion article for the meetup : Less Wrong Montreal - Easy Lifehacks
WHEN: 28 April 2014 07:00:00PM (-0400)
WHERE: 3459 Mctavish, Montréal, QC
There are lots of little things you can do to gain massive improvements in your life, and some of these tricks aren't widely known. Let's pool together any life hacks we've accumulated over the years, for the benefit of everyone. Hopefully, everyone will leave with something new to try!
The meetup is in a different room than the last few times; I'll update the event once I know exactly where it is. If anyone can't find it, PM me and I'll give you my phone number.
Discussion article for the meetup : Less Wrong Montreal - Easy Lifehacks
|
8b134480-c167-4b59-8614-43ef9857c9d7
|
trentmkelly/LessWrong-43k
|
LessWrong
|
2011 Buhl Lecture, Scott Aaronson on Quantum Complexity
I was planning to post this in the main area, but my thoughts are significantly less well-formed than I thought they were. Anyway, I hope that interested parties find it nonetheless.
In the Carnegie Mellon 2011 Buhl Lecture, Scott Aaronson gives a remarkably clear and concise review of P, NP, other fundamentals in complexity theory, and their quantum extensions. In particular, beginning around the 46 minute mark, a sequence of examples is given in which the intuition from computability theory would have accurately predicted physical results (and in some cases this actually happened, so it wasn't just hindsight bias).
In previous posts we have learned about Einstein's arrogance and Einstein's speed. This pattern of results flowing from computational complexity to physical predictions seems odd to me in that context. Here we are using physical computers to derive abstractions about the limits of computation, and from there we are successfully able to intuit limits of physical computation (e.g. brains computing abstractions of the fundamental limits of brains computing abstractions...) At what point do we hit the stage where individual scientists can rationally know that results from computational complexity theory are more fundamental than traditional physics? It seems like a paradox wholly different than Einstein rationally knowing (from examining bits of theory-space evidence rather than traditional-experiment-space evidence) that relativity would hold true. In what sort of evidence space can physical brain computation yielding complexity limits count as bits of evidence factoring into expected physical outcomes (such as the exponential smallness of the spectral gap of NP-hard-Hamiltonians from the quantum adiabatic theorem)?
Maybe some contributors more well-versed in complexity theory can steer this in a useful direction.
|
0d4d79de-0c86-4d0e-b4c7-12adc2af531f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Timaeus is hiring!
TLDR: We’re hiring two research assistants to work on advancing developmental interpretability and other applications of singular learning theory to alignment.
About Us
Timaeus’s mission is to empower humanity by making breakthrough scientific progress on alignment. Our research focuses on applications of singular learning theory to foundational problems within alignment, such as interpretability (via “developmental interpretability”), out-of-distribution generalization (via “structural generalization”), and inductive biases (via “geometry of program synthesis”). Our team spans Melbourne, the Bay Area, London, and Amsterdam, collaborating remotely to tackle some of the most pressing challenges in AI safety.
For more information on our research and the position, see our Manifund application, this update from a few months ago, our previous hiring call and this advice for applicants.
Position Details
* Title: Research Assistant
* Location: Remote
* Duration: 6-month contract with potential for extension.
* Compensation: Starting at $35 USD per hour as a contractor (no benefits).
* Start Date: Starting as soon as possible.
Key Responsibilities
* Conduct experiments using PyTorch/JAX on language models ranging from small toy systems to billion-parameter models.
* Collaborate closely with a team of 2-4 researchers.
* Document and present research findings.
* Contribute to research papers, reports, and presentations.
* Maintain detailed research logs.
* Assist with the development and maintenance of codebases and repositories.
Projects
As a research assistant, you would likely work on one of the following two projects/research directions (this is subject to change):
* Devinterp of language models: (1) Continue scaling up techniques like local learning coefficient (LLC) estimation to larger models to study the development of LLMs in the 1-10B range. (2) Work on validating the next generations of SLT-derived techniques such as restricted LLC estimatio
|
03c15bb1-3e53-44ff-88e1-fb954a0668c5
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Retrieval Augmented Genesis
a prototype and some thoughts on semantics
Before reading this article I strongly encourage you to Checkout the RAGenesis App!
Full code available at https://github.com/JoaoRibeiroMedeiros/RAGenesisOSS.
Screenshot of Verse Uni Verse page
Project Goals
* Send a message of unity and mutual understanding between different cultures through a “generative book” compiling the wisdom of many different traditions.
* Develop a framework for transparency of embedded knowledge bases and evaluation of main messaging in a RAG application.
* Define Semantic Similarity Networks as special case of Semantic Networks and derive Main Chunk methodology based on elementary Graph theory.
* Create a showcase of my technical capacity as an AI engineer, data scientist, product designer, software developer and writer.
* Make something cool.
Introduction
Having led the development of several software products based on RAG engines for the last year, I have been consistently investigating the scope of semantic similarity for a plethora of different use cases.
Turns out this exercise got me wondering about some of the more fundamental aspects of what AI-driven semantic similarity can accomplish, in the years to come.
I figured that through semantic similarity algorithms the current AI engines have opened up a pathway to explore texts and documentation in a radically innovative way, which has implications for education, research and everything that stems from those two foundational areas of human activity.
In this article, I present ragenesis.com platform and explore the thought process behind its development, which I have accomplished as a solo full-stack AI engineering, software development and data science project. Beyond that, I also used this exercise as a platform to collect thoughts around the importance of RAG tools, and how there is still a lot of opportunity when it comes to the value that this kind of application can produce.
Finally, I showcase some results for the sema
|
626c48cd-32a1-44c9-a577-19fe8d82ad97
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Do Corporations Have a Right to Privacy?
The link to Bruce Schneier's original post.
> This week, the U.S. Supreme Court will hear arguments about whether or not corporations have the same rights to "personal privacy" that individuals do.
The Electronic Privacy Information Center (EPIC) has filed a amicus curiae brief in the case.
The brief makes legal and philosophical arguments for privacy as an important human right, and that it is not a corporate right, and does not need to be. It also contains a number of scholarly references on the topic.
I find the legal arguments against a corporate right to privacy convincing. Corporations in our current legal context are intentionally organized to provide certain types of public accountability.
However, I am not convinced by the philosophical arguments for restricting the right to privacy to individuals.
To summarize the utility of an individual right to privacy, as discussed in the brief:
A right to privacy is necessary for individuals to enjoy the feelings of autonomy, control and security, which are important for healthy cognitive development. It protects the seclusion needed for experimentation, developing identity, establishing intimate relationships, and for making meaningful choices free of ex-ante manipulation and coercion. It provides the opportunity to structure life in unconventional ways, freeing a person from the stultifying effects of scrutiny and approbation or disapprobation. It helps to avoid embarrassment, preserving dignity and respect, avoiding harm to social development and growth. It helps to prevent the appropriation of a person's name or likeness. It sets the balance of power between a person, and the world around them.
To summarize the philosophical argument against a corporate right to privacy:
Corporate entities are incapable of experiencing hurt feelings.
I think these arguments provide an unwarranted special status to human emotion. Emotions are body states related to expected utility. They bias decision making toward
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.