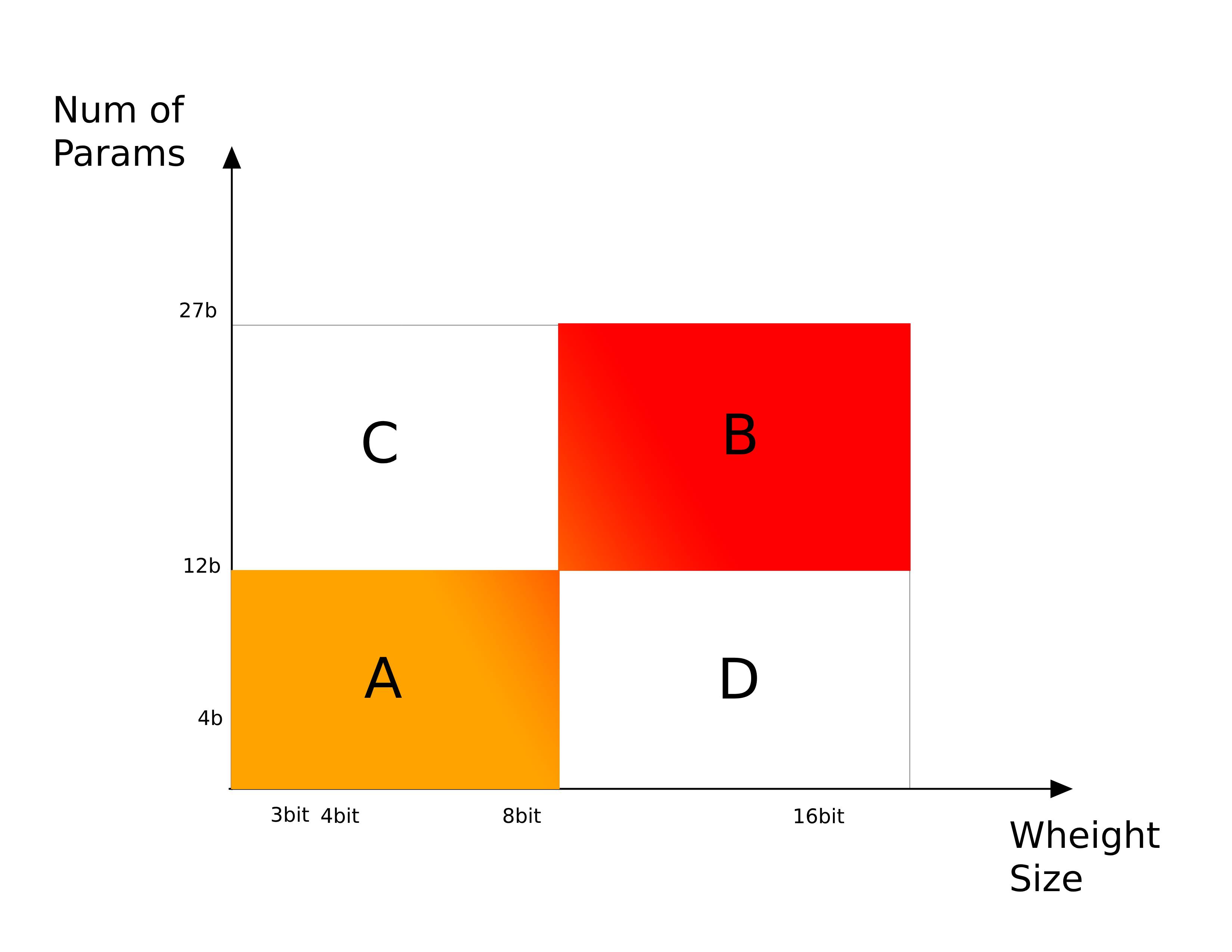
Model Parameters number vs Quantization level tradeoff

Hi guys
For llm models as both parameters number and quantization level affect the size of a model so for the practical outcome what are tradeoffs for sacrificing either one of thees aspects
E.g. what would be the difference using gemma-3-4b-it-4bit vs gemma-3-1b-it-bf16
Thank you

Hi @jvoid ,
Welcome to Google Gemma family of open source models, thanks for reaching out to us - Yes, that's correct, the numbers of parameters and quantization level affects the model's output accuracy. Coming to your question the tradeoff needs to consider based on the task that you are going to accomplish using the model and computational resources you have to accomplish that task.
For example if you have large enough resources to load and compute the model of high number of parameter models(like 12b, 27b') and actual parameters precision (like 32bit, bf16`) then the model will provide the results in more accurate manner as we have the model with full precision weights/parameters. If you have limited resources then it's recommended to use the quantization mechanism to reduce the memory/computation usage with the significant accuracy of model. Even the quantized models performs the most of the tasks with significant accuracy.
To know more about Gemma models please visit the following page and to know about quantization please visit the following Colab.
If you required any further assistance please feel free to reach out to me.
Thanks.
Hi
@BalakrishnaCh
. Thank you for your reply
Let me clarify my question al little
As we both mentioned the it is pretty direct dependence of both the attributes (params and quantum) to a model quality
higher values => better quality
lower values => worse quality
And the very same works for the resources consumption
My point is actually what is the tradeoff for sacrificing either ONE of the parameters in the sake of decreasing resource consumption still trying to achieve the best quality
So that referring approximately the same model size in general (memory, storage space) what would be the best performant
Option | Params Number | Quant
1 | higher | lower
2 | lower | higher
And which way these two strategies affect any of model metrics
Thank you
Yes, it's depends on choice of our selection:
Option 1: Higher Parameters | Lower Quantization
- Gemma 7B quantized to Q8_0 (8-bit) or FP16 (16-bit)
- Resource Footprint:
Gemma 7B (FP16) is approximately 14 GB
Gemma 7B (Q8_0) is approximately 7 GB
This option typically offers the highest quality among the two. Higher parameter count directly correlates with better reasoning, factual recall, nuance, and overall capability. Lower quantization (like 8-bit or 16-bit) introduces minimal to no degradation compared to the original full-precision model. Even with lower quantization (e.g., 8-bit), a higher parameter count still means a larger base model. To keep the overall resource footprint similar to a highly quantized smaller model, you'd be looking at relatively "mild" quantization (e.g., 8-bit, or perhaps 6-bit). This might still exceed the memory of very constrained devices.
Option 2: Lower Parameters | Higher Quantization
- Gemma 2B quantized to Q4_K_M (4-bit) or even Q3 (3-bit)
- Resource Footprint:
Gemma 2B (Q4_K_M) is approximately 2 GB - 2.5 GB
This option excels at resource efficiency. By heavily quantizing a smaller model, you can achieve very small file sizes and memory footprints, making it suitable for edge devices, mobile, or extremely cost-sensitive deployments. The primary downside is a potential drop in quality. While modern quantization techniques like Q4_K_M are remarkably good, going down to 4-bit will inevitably lead to some loss of precision.
Based on the requirements and resource availability we have to choose between the options.
Thanks.
Hi @BalakrishnaCh . Thanks for staying with me
My bad expressing my point agin.
Talking about Quant quality (lower / higher) I was to characterize the weights size it self instead of weights compression level. I.e Hight - FB16bit, low - 1bit.
So your comparison is a pretty straight forward. The more resources the better the quality. The less resources the poorer the performance. Which refers to the cutting edge sections A and B on the chart attached.
Still my base question point is around to find some golden ratio between resources / model quality. So that what would be the best compromise among either C and D sectors and how different do these exactly affect the model behavior. E.g. what would be in comparison the characteristics for 4b fb16 vs 27b 3bit.
In another words how to compare the tradeoff in reduction of each single dimension individually while keeping the same time the second dimension constant
Really hope I succeeded to state it clear this time)
Thank you