
Ling
Collection
9 items
•
Updated
•
11

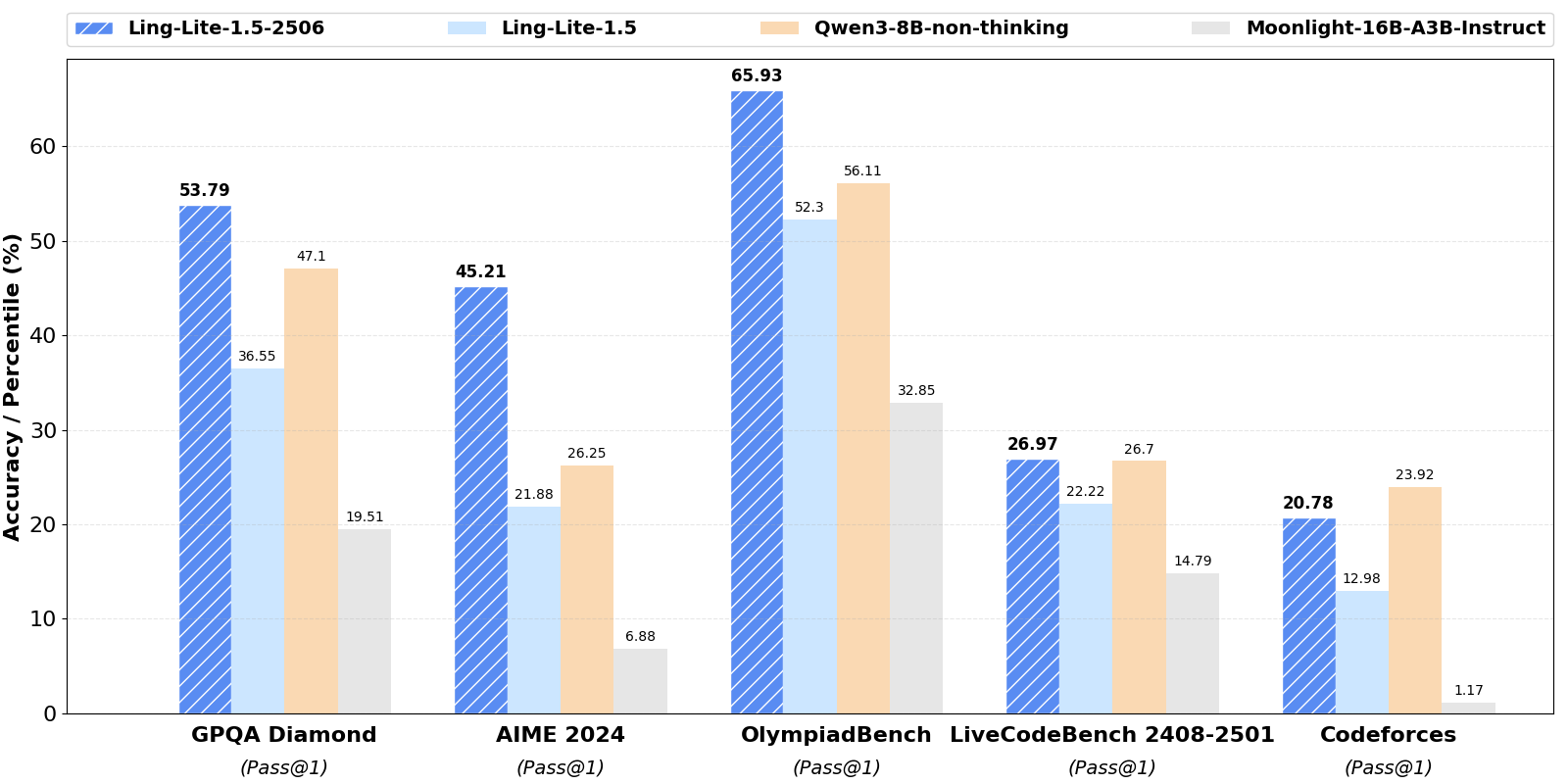
We are excited to introduce Ling-lite-1.5-2506, the updated version of our highly capable Ling-lite-1.5 model.
Ling-lite-1.5-2506 boasts 16.8 billion parameters with 2.75 billion activated parameters, building upon its predecessor with significant advancements across the board, featuring the following key improvements:
You can download the following table to see the various parameters for your use case. If you are located in mainland China, we also provide the model on ModelScope.cn to speed up the download process.
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| Ling-lite-1.5-2506 | 16.8B | 2.75B | 128K | 🤗 HuggingFace |
| Ling-lite-1.5 | 16.8B | 2.75B | 128K | 🤗 HuggingFace |
Here is a code snippet to show you how to use the chat model with transformers:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "inclusionAI/Ling-lite-1.5-2506"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language models."
messages = [
{"role": "system", "content": "You are Ling, an assistant created by inclusionAI"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Please refer to Github
This code repository is licensed under the MIT License.
If you find our work helpful, feel free to give us a cite.
@article{ling,
title = {Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs},
author = {Ling Team},
journal = {arXiv preprint arXiv:2503.05139},
year = {2025}
}