
Partition Generative Models - Masked Modeling Without Masks
By Justin Deschenaux, Lan Tran, Caglar Gulcehre
![]()
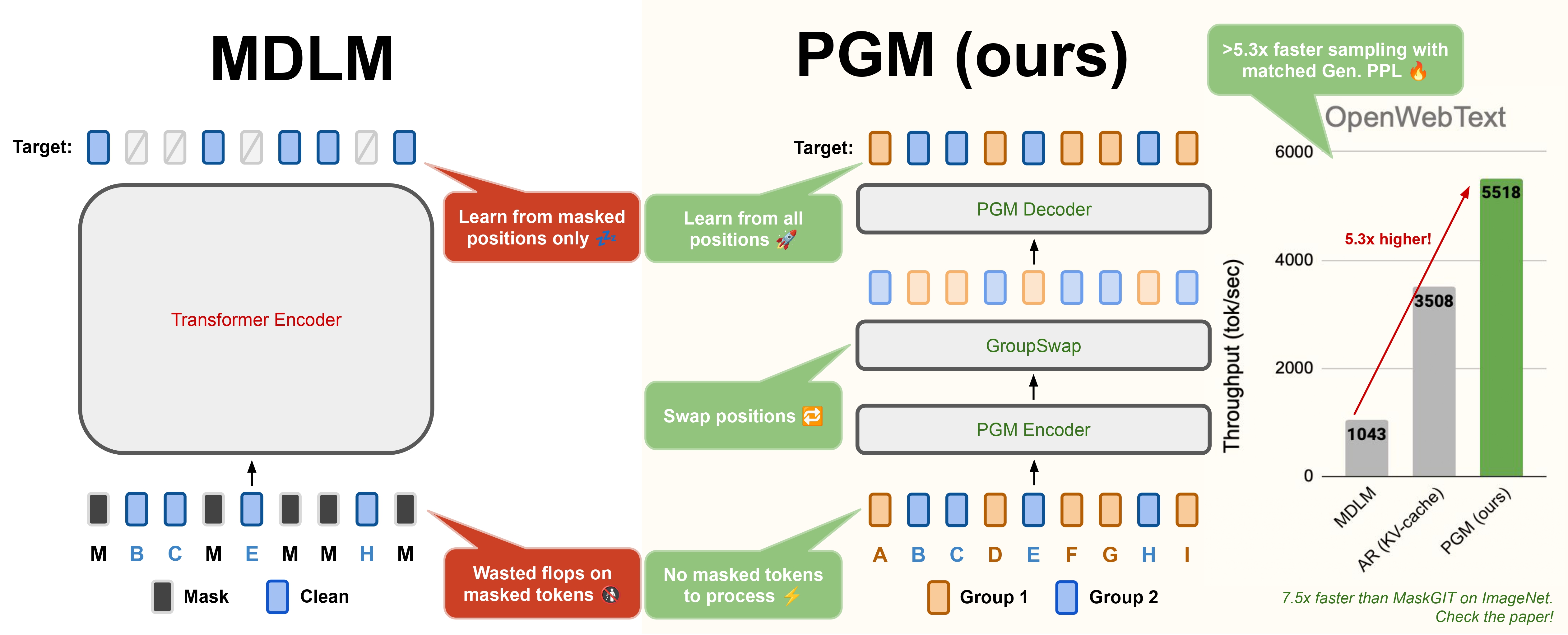
TL;DR: Partition Generative Models (PGMs) speed up parallel generation by partitioning tokens and using sparse attention instead of masking.
Try Our Models
Try our models directly on Google Colab!
Getting started locally
To get started, install the dependencies in requirements.txt. The requirements do not contain the numpy and torch dependencies, since these need to be set in combination. For us, we work in docker containers, built from nvcr.io/nvidia/pytorch:25.02-py3, which uses torch==2.7.0 and numpy==1.26.4.
Reproducing the Results
Our experiments for text and images are based on two main codebases. For text experiments, we build upon the Duo codebase. For image experiments, we adapt the Halton MaskGIT codebase. As a result, we maintain separate branches for text and image experiments:
- Text experiments (besides distillation) are on the
text_pretrainbranch. - Image experiments are on the
image_pretrainbranch.
Additionally, we distilled models using SDTT. The relevant code can be found on the text_distill_sdtt branch, which is a slight adaptation of the SDTT codebase. You can find further instructions in the respective branches.
Checkpoints
We release checkpoints trained on OpenWebText (1M steps, distilled and undistilled) and ImageNet (500k steps) on 🤗 Huggingface. The checkpoints on HuggingFace are directly compatible with the code without conversion.
Citation
@misc{deschenaux2025partitiongenerativemodelingmasked,
title={Partition Generative Modeling: Masked Modeling Without Masks},
author={Justin Deschenaux and Lan Tran and Caglar Gulcehre},
year={2025},
eprint={2505.18883},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.18883},
}