
Draft Models
Collection
Tiny "draft" models for speculative decoding.
•
24 items
•
Updated
•
1
A 0.6B parameter draft (speculative decoding) model for use with DeepSeek-V3-0324 and DeepSeek-V3.
See DeepSeek-V3-DRAFT-0.6B-v2.0-GGUF for the models in gguf format for use with llama.cpp.
The current config.json is set for context length up to 32k tokens. Add the "rope_scaling" section to config.json to enable YaRN, eg:
"max_position_embeddings": 65536,
...
"rope_scaling": {
"factor": 2.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
},
"max_position_embeddings": 131072,
...
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
},
NOTE: Because llama.cpp uses "static-YaRN" the scaling factor remains constant regardless of input length! Only add the rope_scaling configuration when processing long contexts is required...
python ./transplant_vocab.py \
./Qwen2.5-Coder-0.5B-Instruct \
./DeepSeek-V3-0324-BF16 \
./DeepSeek-V3-DRAFT-0.6B-UNTRAINED \
--override "<|▁pad▁|>" "<|endoftext|>" \
--override "<|fim▁hole|>" "<|fim_middle|>" \
--override "<|fim▁begin|>" "<|fim_prefix|>" \
--override "<|fim▁end|>" "<|fim_suffix|>" \
--override "<|User|>" "<|im_start|>user\\n" \
--override "<|Assistant|>" "<|im_start|>assistant\\n" \
--override "<|EOT|>" "<|endoftext|>" \
--override "<|tool▁calls▁begin|>" "<tool_call>" \
--override "<|tool▁call▁begin|>" "<tool_call>" \
--override "<|tool▁outputs▁begin|>" "<tool_call>" \
--override "<|tool▁output▁begin|>" "<tool_call>" \
--override "<|tool▁calls▁end|>" "</tool_call>" \
--override "<|tool▁call▁end|>" "</tool_call>" \
--override "<|tool▁outputs▁end|>" "</tool_call>" \
--override "<|tool▁output▁end|>" "</tool_call>" \
--override "<|tool▁sep|>" "</tool_call>"
formatted just between <|end▁of▁sentence|> tags.
# ==============================
# MODEL AND OUTPUT CONFIGURATION
# ==============================
model_dir = 'models/DeepSeek-V3-DRAFT-0.6B-UNTRAINED'
output_dir = 'finetuned'
# ===========================
# TRAINING TYPE CONFIGURATION
# ===========================
full_fine_tune = true
# =======================
# OPTIMIZER CONFIGURATION
# =======================
lr = 2e-5
# ======================
# TRAINING CONFIGURATION
# ======================
sequence_len = 32768
gradient_accumulation_steps = 5 # 5×6 = batch size 30, 5×6×32768 = ~1M tokens per step
# =====================
# DATASET CONFIGURATION
# =====================
[[datasets]]
dataset_path = 'datasets/common-crawl-sample/*.json'
drop_tails = true
[[datasets]]
dataset_path = 'datasets/the-stack-smol-xl/*.jsonl'
drop_tails = true
I used six RTX A6000 GPUs over three nodes and hence the 30 batch size (6 x 5 gradient accumulation steps = 30).
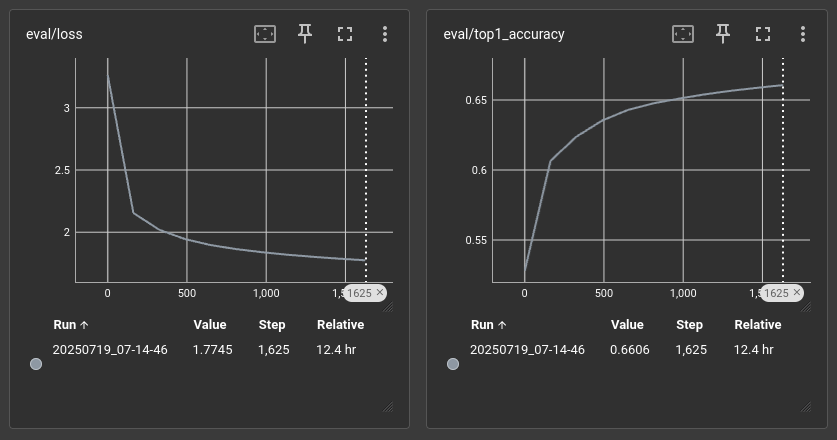
Base model
Qwen/Qwen2.5-0.5B