
Draft Models
Collection
Tiny "draft" models for speculative decoding.
•
24 items
•
Updated
•
1
A 0.6B parameter draft (speculative decoding) model for use with Kimi-K2-Instruct.
See Kimi-K2-Instruct-DRAFT-0.6B-v2.0-GGUF for the models in gguf format for use with llama.cpp.
The current config.json is set for context length up to 32k tokens. Add the "rope_scaling" section to config.json to enable YaRN, eg:
"max_position_embeddings": 65536,
...
"rope_scaling": {
"factor": 2.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
},
"max_position_embeddings": 131072,
...
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
},
NOTE: Because llama.cpp uses "static-YaRN" the scaling factor remains constant regardless of input length! Only add the rope_scaling configuration when processing long contexts is required...
python ./transplant_vocab.py \
./Qwen2.5-Coder-0.5B-Instruct \
./Kimi-K2-Instruct-BF16 \
./Kimi-K2-Instruct-DRAFT-0.6B-UNTRAINED \
--trust-remote-code \
--override "[BOS]" "<|endoftext|>" \
--override "[EOS]" "<|im_end|>" \
--override "<|im_end|>" "<|im_end|>" \
--override "<|im_user|>" "<|im_start|>user" \
--override "<|im_assistant|>" "<|im_start|>assistant" \
--override "<|start_header_id|>" "<|im_start|>" \
--override "<|end_header_id|>" "<|im_end|>" \
--override "[EOT]" "<|endoftext|>" \
--override "<|im_system|>" "<|im_start|>system" \
--override "<|tool_calls_section_begin|>" "<tool_call>" \
--override "<|tool_calls_section_end|>" "</tool_call>" \
--override "<|tool_call_begin|>" "<tool_call>" \
--override "<|tool_call_argument_begin|>" "<tool_call>" \
--override "<|tool_call_end|>" "</tool_call>" \
--override "<|im_middle|>" "\\n" \
--override "[UNK]" "<|endoftext|>" \
--override "[PAD]" "<|endoftext|>"
NOTE: Due to the non-standard tokenizer, this needs the --trust-remote-code option.
There were still some odd looking things in the config files (compared to usual transplant-vocab outputs), so I then:
tokenizer_config.json from Kimi-K2-Instruct over the top of the transplant-vocab-generated one.config.json from Qwen2.5-Coder-0.5B-Instruct over the top of the transplant-vocab-generated one.config.json to use: "bos_token_id": 163584, "eos_token_id": 163585 and "tie_word_embeddings": false.formatted just between [EOS] tags.
# ==============================
# MODEL AND OUTPUT CONFIGURATION
# ==============================
model_dir = 'models/Kimi-K2-Instruct-DRAFT-0.6B-UNTRAINED'
output_dir = 'finetuned'
# ===========================
# TRAINING TYPE CONFIGURATION
# ===========================
full_fine_tune = true
# =======================
# OPTIMIZER CONFIGURATION
# =======================
lr = 2e-5
# ======================
# TRAINING CONFIGURATION
# ======================
sequence_len = 32768
gradient_accumulation_steps = 5 # 5×6 = batch size 30, 5×6×32768 = ~1M tokens per step
# =====================
# DATASET CONFIGURATION
# =====================
[[datasets]]
dataset_path = 'datasets/common-crawl-sample/*.json'
drop_tails = true
[[datasets]]
dataset_path = 'datasets/the-stack-smol-xl/*.jsonl'
drop_tails = true
NOTE: Due to the non-standard tokenizer, this needs the --trust-remote-code option passing on the deepspeed call to train.py.
I used six RTX A6000 GPUs over three nodes and hence the 30 batch size (6 x 5 gradient accumulation steps = 30).
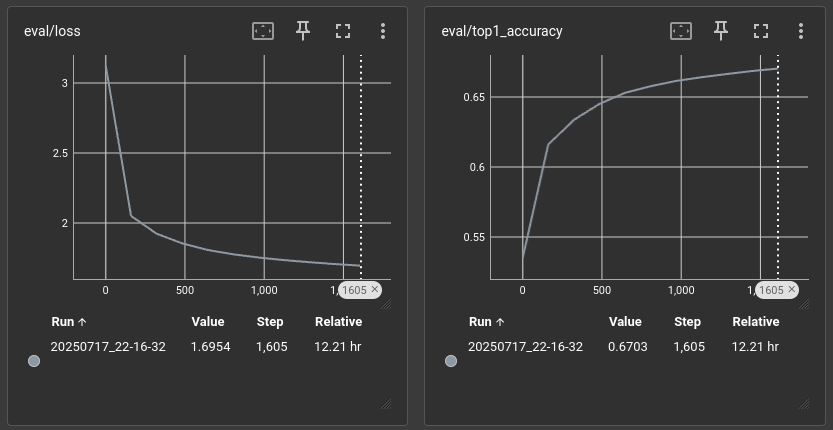
TikToken / SentencePiece tokenizer mismatch in llama.cpp
I had to temporarily hack this change into convert_hf_to_gguf.py:
@ModelBase.register("Qwen2Model", "Qwen2ForCausalLM", "Qwen2AudioForConditionalGeneration")
class Qwen2Model(TextModel):
model_arch = gguf.MODEL_ARCH.QWEN2
#def set_vocab(self):
# try:
# self._set_vocab_sentencepiece()
# except FileNotFoundError:
# self._set_vocab_gpt2()
def set_vocab(self):
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(self.dir_model, trust_remote_code=True)
tokpre = self.get_vocab_base_pre(tokenizer)
# Build merges list using the approach similar to HunYuanMoE
merges = []
vocab = {}
mergeable_ranks = tokenizer.model._mergeable_ranks
for token, rank in mergeable_ranks.items():
vocab[QwenModel.token_bytes_to_string(token)] = rank
if len(token) == 1:
continue
merged = QwenModel.bpe(mergeable_ranks, token, max_rank=rank)
if len(merged) == 2:
merges.append(' '.join(map(QwenModel.token_bytes_to_string, merged)))
# Build token list
vocab_size = self.hparams["vocab_size"]
special_tokens = tokenizer.special_tokens
reverse_vocab = {id_ : encoded_tok for encoded_tok, id_ in {**vocab, **special_tokens}.items()}
tokens: list[str] = []
toktypes: list[int] = []
for i in range(vocab_size):
if i not in reverse_vocab:
tokens.append(f"[PAD{i}]")
toktypes.append(gguf.TokenType.UNUSED)
else:
token = reverse_vocab[i]
tokens.append(token)
if i in special_tokens.values():
toktypes.append(gguf.TokenType.CONTROL)
else:
toktypes.append(gguf.TokenType.NORMAL)
self.gguf_writer.add_tokenizer_model("gpt2")
self.gguf_writer.add_tokenizer_pre(tokpre)
self.gguf_writer.add_token_list(tokens)
self.gguf_writer.add_token_types(toktypes)
self.gguf_writer.add_token_merges(merges)
special_vocab = gguf.SpecialVocab(self.dir_model, load_merges=False)
special_vocab.add_to_gguf(self.gguf_writer)
This then let me run:
~/llama.cpp/convert_hf_to_gguf.py --outtype auto --outfile Kimi-K2-Instruct-DRAFT-0.6B-BF16.gguf Kimi-K2-Instruct-DRAFT-0.6B
and then it quantized OK:
~/llama.cpp/build/bin/llama-quantize Kimi-K2-Instruct-DRAFT-0.6B-BF16.gguf Kimi-K2-Instruct-DRAFT-0.6B-Q4_0.gguf Q4_0 44
Base model
Qwen/Qwen2.5-0.5B