
TextSyncMimi-v1
TextSyncMimi provides a text‑synchronous speech representation designed to plug into LLM‑based speech generation. Instead of operating at a fixed frame rate (time‑synchronous), it represents speech per text token and reconstructs high‑fidelity audio through a Mimi‑compatible neural audio decoder.
TL;DR: We turn time‑synchronous Mimi latents into text‑synchronous token latents ([tᵢ, sᵢ]), then expand them back to Mimi latents and decode to waveform. This makes token‑level control and alignment with LLM text outputs straightforward.
Model overview
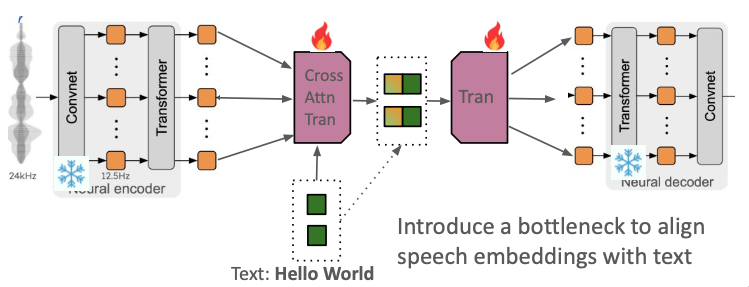
- TextSyncMimi components:
- Cross‑attention encoder — aligns Mimi’s time‑synchronous sequence (length T) to the text sequence (length N), producing one continuous speech latent per text token.
- Causal decoder — expands token‑level latents back to a Mimi‑rate latent sequence suitable for a Mimi decoder. The decoder is streaming.
- Mimi backbone
Training / Evaluation
- Lossess: (i) L2 distance between predicted and ground‑truth continuous Mimi latents, and (ii) BCE for the stop token during expansion.
- Training Data: LibriSpeech (960 hours) + LibriTTS (585 hours) -- around 1.5K hours in total
- Results: ASR WER on audio reconstructed from different methods (NB: non-zero WER of ground-truth audio came from ASR errors):
Method Train data WER ↓ Ground‑truth – 2.12 Mimi – 2.29 TASTE Emilia + LibriTTS 4.40 TextSyncMimi v1 LibriTTS‑R + LibriSpeech 3.06
Usage
Loading the Model
from transformers import AutoModel
model = AutoModel.from_pretrained("potsawee/TextSyncMimi-v1", trust_remote_code=True)
See the code of Speech Editing with TextSync Mimi for a use-case (e.g., encoding, decoding, swapping) of the model
Acknowledgements
- Built on top of Kyutai's Mimi audio codec
- Downloads last month
- 10
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support