
You need to agree to share your contact information to access this model
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
Access Request for pingala-v1-en-verbatim
This model is distributed under the Shunya Labs RAIL-M License with use-based restrictions.
By requesting access, you agree to:
- Use the model only for permitted purposes as defined in the license
- Not redistribute or create derivative works
- Comply with all use-based restrictions
- Use the model responsibly and ethically
Please provide the following information:
Log in or Sign Up to review the conditions and access this model content.
Pingala V1 English Verbatim
A high-performance English speech recognition model optimized for verbatim transcription by Shunyalabs, converted to CT2 format for efficient inference with FasterWhisper.
Try the demo at https://www.shunyalabs.ai
License
This model is distributed under the Shunya Labs RAIL-M License, which includes specific use-based restrictions and commercial licensing requirements.
License Summary
- Free Use: Up to 10,000 hours of audio transcription per calendar month
- Distribution: Model cannot be redistributed to third parties
- Derivatives: Creation of derivative works is not permitted
- Attribution: Required when outputs are made public or shared
Key Restrictions
The license prohibits use for discrimination, military applications, disinformation, privacy violations, unauthorized medical advice, and other harmful purposes. Please refer to the complete LICENSE file for detailed terms and conditions.
For inquiries, contact: [email protected]
Model Overview
Pingala V1 English Verbatim is a state-of-the-art automatic speech recognition (ASR) model that delivers exceptional accuracy across diverse English audio domains. The model has been optimized for production use with CTranslate2 and FasterWhisper, providing both high accuracy and fast inference speeds.
This model is specifically designed for verbatim transcription, ensuring accurate word-for-word capture of spoken English content across various domains including meetings, earnings calls, broadcast media, and educational content.
Performance Benchmarks
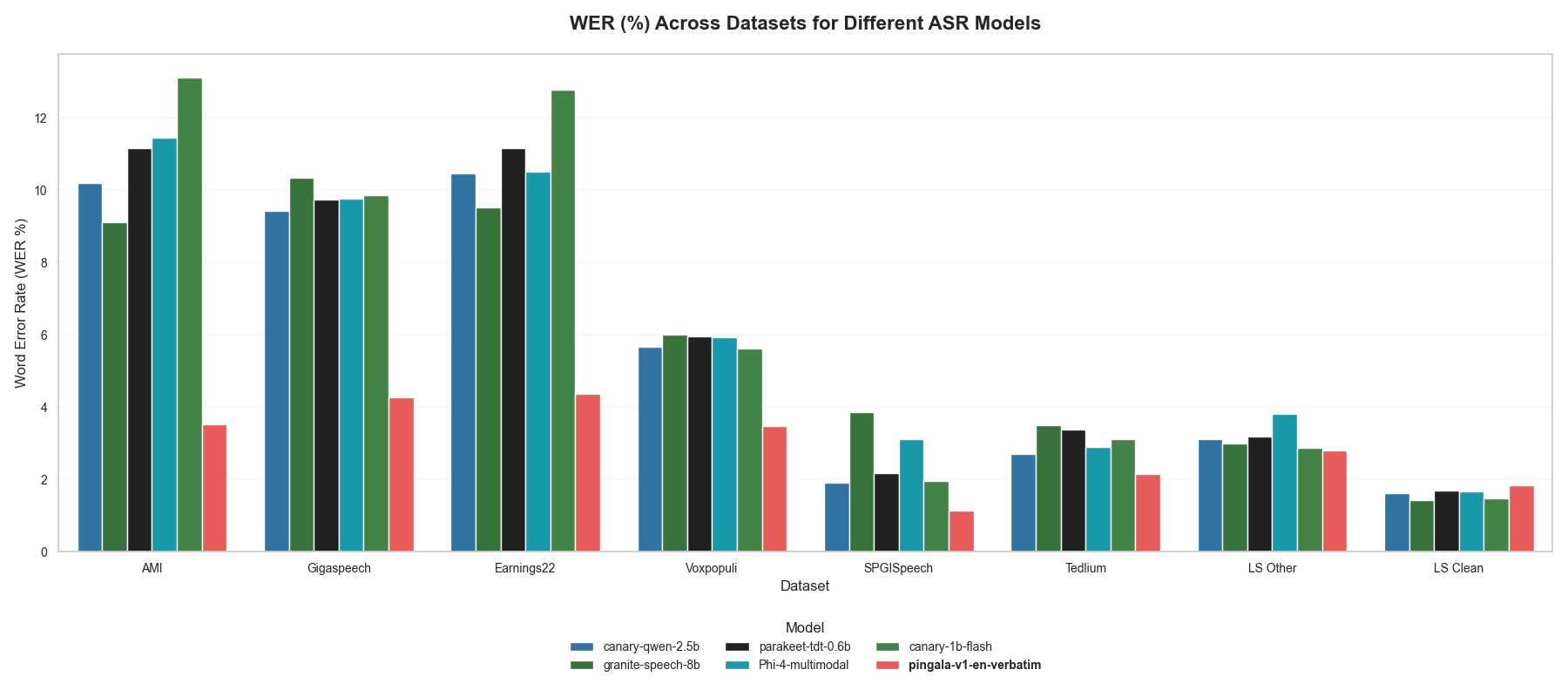
OpenASR Leaderboard Results
The model has been extensively evaluated on the OpenASR leaderboard across multiple English datasets, demonstrating superior performance compared to larger open-source models:
| Dataset | WER (%) | RTFx |
|---|---|---|
| AMI Test | 3.52 | 18.38 |
| Earnings22 Test | 4.36 | 25.67 |
| GigaSpeech Test | 4.26 | 24.62 |
| LibriSpeech Test Clean | 1.84 | 29.20 |
| LibriSpeech Test Other | 2.81 | 25.01 |
| SPGISpeech Test | 1.13 | 11.67 |
| TedLium Test | 2.14 | 11.03 |
| VoxPopuli Test | 3.47 | 31.81 |
Composite Results
- Overall WER: 2.94%
- Average RTFx: 14.61
RTFx (Real-Time Factor) indicates inference speed relative to audio duration. Higher values mean faster processing.
Comparative Performance
Pingala V1 significantly outperforms larger open-source models on 8 common speech benchmarks:
| Model | AMI | Earnings22 | GigaSpeech | LS Clean | LS Other | SPGISpeech | TedLium | Voxpopuli | Avg WER |
|---|---|---|---|---|---|---|---|---|---|
| nvidia/canary-qwen-2.5b | 10.19 | 10.45 | 9.43 | 1.61 | 3.10 | 1.90 | 2.71 | 5.66 | 5.63 |
| ibm/granite-granite-speech-3.3-8b | 9.12 | 9.53 | 10.33 | 1.42 | 2.99 | 3.86 | 3.50 | 6.00 | 5.74 |
| nvidia/parakeet-tdt-0.6b-v2 | 11.16 | 11.15 | 9.74 | 1.69 | 3.19 | 2.17 | 3.38 | 5.95 | 6.05 |
| microsoft/Phi-4-multimodal-instruct | 11.45 | 10.50 | 9.77 | 1.67 | 3.82 | 3.11 | 2.89 | 5.93 | 6.14 |
| nvidia/canary-1b-flash | 13.11 | 12.77 | 9.85 | 1.48 | 2.87 | 1.95 | 3.12 | 5.63 | 6.35 |
| shunyalabs/pingala-v1-en-verbatim | 3.52 | 4.36 | 4.26 | 1.84 | 2.81 | 1.13 | 2.14 | 3.47 | 2.94 |
Authentication with Hugging Face Hub
This model require authentication with Hugging Face Hub. Here's how to set up and use your Hugging Face token.
Getting Your Hugging Face Token
- Create a Hugging Face Account: Go to huggingface.co and sign up
- Generate a Token:
- Go to Settings > Access Tokens
- Click "New token"
- Choose "Read" permissions
- Copy your token (starts with
hf_...)
Setting Up Authentication
Method 1: Environment Variable (Recommended)
# Set your token as an environment variable
export HUGGINGFACE_HUB_TOKEN="hf_your_token_here"
# Or add to your ~/.bashrc or ~/.zshrc for persistence
echo 'export HUGGINGFACE_HUB_TOKEN="hf_your_token_here"' >> ~/.bashrc
source ~/.bashrc
Method 2: Hugging Face CLI Login
# Install Hugging Face CLI if not already installed
pip install huggingface_hub
# Login using CLI
huggingface-cli login
# Enter your token when prompted
Method 3: Programmatic Authentication
from huggingface_hub import login
# Login programmatically
login(token="hf_your_token_here")
Installation
Basic Installation
pip install pingala-shunya
Usage
Quick Start
from pingala_shunya import PingalaTranscriber
# Initialize with default Shunya Labs model and ct2 backend
transcriber = PingalaTranscriber()
## Initialize with default Shunya Labs model and ct2 backend and CPU
# transcriber = PingalaTranscriber(device="cpu", compute_type="int8")
# Simple transcription
segments = transcriber.transcribe_file_simple("audio.wav")
for segment in segments:
print(f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}")
Backend Selection
from pingala_shunya import PingalaTranscriber
# Explicitly choose backends with Shunya Labs model
transcriber_ct2 = PingalaTranscriber(model_name="shunyalabs/pingala-v1-en-verbatim", backend="ct2")
# Auto-detection (recommended)
transcriber_auto = PingalaTranscriber() # Uses default Shunya Labs model with ct2
Model Details
- Architecture: ctranslate2-based model optimized for verbatim English transcription
- Format: CTranslate2 compatible for efficient inference
- Framework: FasterWhisper optimized
- Language: English (en)
- Sampling Rate: 16 kHz
- Model Size: Production-optimized for deployment
- Optimization: Real-time inference capable with GPU acceleration
Key Features
- Exceptional Accuracy: Achieves 2.94% WER across diverse English test sets
- Real-Time Performance: Average RTFx of 14.61 enables real-time applications
- Verbatim Transcription: Optimized for accurate, word-for-word transcription
- Production Ready: CTranslate2 optimization ensures efficient deployment
- Multi-Domain Excellence: Superior performance across conversational, broadcast, and read English speech
- Voice Activity Detection: Built-in VAD for better handling of silence
Performance Optimization Tips
- GPU Acceleration: Use
device="cuda"for significantly faster inference - Precision: Set
compute_type="float16"for optimal speed on modern GPUs - Threading: Adjust
cpu_threadsandnum_workersbased on your hardware configuration - VAD Filtering: Enable
vad_filter=Truefor improved performance on long audio files - Language Specification: Set
language="en"for English audio to improve accuracy and speed - Beam Size: Use
beam_size=5for best accuracy, reduce for faster inference - Batch Processing: Process multiple files with a single model instance for efficiency
Use Cases
The model excels in various English speech recognition scenarios:
- Meeting Transcription: High accuracy on conversational English speech (AMI: 3.52% WER)
- Financial Communications: Specialized performance on earnings calls and financial content (Earnings22: 4.36% WER)
- Broadcast Media: Excellent results on news, podcasts, and media content
- Educational Content: Optimized for lectures, presentations, and educational material transcription
- Customer Support: Accurate transcription of support calls and customer interactions
- Legal Documentation: Professional-grade accuracy for legal proceedings and depositions
- Medical Transcription: High-quality transcription for medical consultations and documentation
Support and Contact
For technical support, licensing inquiries, or commercial partnerships:
- Website: https://www.shunyalabs.ai
- Documentation: https://www.shunyalabs.ai/pingala
- Pypi: https://pypi.org/project/pingala-shunya
- Commercial Licensing: [email protected]
Acknowledgments
Built with FasterWhisper and CTranslate2 for optimal inference performance. Special thanks to the open-source community for providing the foundational tools that make this model possible.
Version History
- v1.0: Initial release with state-of-the-art performance across multiple English domains
- Optimized for verbatim transcription with 2.94% composite WER
- CTranslate2 format for efficient inference
- Production-ready deployment capabilities
This model is provided under the Shunya Labs RAIL-M License. Please ensure compliance with all license terms before use.
- Downloads last month
- 1
Evaluation results
- Overall WER on Compositeself-reported2.940
- Average RTFx on Compositeself-reported14.610
- WER on AMIself-reported3.520
- WER on Earnings22self-reported4.360
- WER on GigaSpeechself-reported4.260
- WER on LibriSpeech Test Cleanself-reported1.840
- WER on LibriSpeech Test Otherself-reported2.810
- WER on SPGISpeechself-reported1.130
- WER on TedLiumself-reported2.140
- WER on VoxPopuliself-reported3.470