
Tri Series
Collection
Introducing our new series of models: Tri-7B, Tri-21B, and Tri-70B-preview-SFT
•
10 items
•
Updated
•
8
The information you provide will be collected, stored, processed and shared in accordance with the Trillion Labs Privacy Policy.
TRILLION LABS AI MODEL LICENSE AGREEMENT Tri- Model Series Version Effective Date: February 1, 2025
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the Trillion Labs AI Model series set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying the Tri- Model series distributed by Trillion Labs.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity's behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
"Model" means the artificial intelligence model series provided by Licensor ("Tri-" series), including software, algorithms, machine learning models, and related components provided by Licensor, including all updates, enhancements, improvements, bug fixes, patches, or other modifications.
"Trillion Labs" or "we" means Trillion Labs, the owner, developer, and provider of the Model, holding all rights, title, and interest in the Model.
By clicking "I Accept" below or by using or distributing any portion or element of the Model, you agree to be bound by this Agreement.
1. License Grant and Redistribution.
a. Grant of Rights. You are granted a limited, non-exclusive, non-transferable, worldwide, revocable license under Trillion Labs' intellectual property or other rights to use, reproduce, distribute, and make modifications to the Model for research purposes.
b. Redistribution and Use.
i. If you distribute or make available the Model (or any derivative works thereof), or a product or service that contains any of them, you shall (A) provide a copy of this Agreement with any such Model; and (B) prominently display "Built with Tri-" on a related website, user interface, blogpost, about page, or product documentation. If you use the Model to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include "Tri-" followed by the original Model version at the beginning of any such AI model name.
ii. You must retain in all copies of the Model that you distribute the following attribution notice within a "Notice" text file distributed as a part of such copies: "Tri- Model Series is licensed under the Trillion Labs AI Model License Agreement, Copyright © Trillion Labs. All Rights Reserved."
iii. Your use of the Model must comply with applicable laws and regulations (including trade compliance laws and regulations).
2. Additional Commercial Terms. If the monthly active users of the products or services made available by or for Licensee, or Licensee's affiliates, is greater than 1 million monthly active users OR Annual Recurring Revenue is greater than $10 million USD, you must request a commercial license from Trillion Labs, and you are not authorized to exercise any commercial rights under this Agreement unless or until Trillion Labs otherwise expressly grants you such rights.
3. Disclaimer of Warranty. THE MODEL, DERIVATIVES, AND OUTPUT ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND, AND TRILLION LABS DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE.
4. Limitation of Liability. IN NO EVENT WILL TRILLION LABS BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Model, neither Trillion Labs nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Model or as set forth in this Section 5(a).
b. All rights, title, and interest in the Model, including modifications, Derivatives, and documentation, remain exclusively with Trillion Labs.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Model and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Trillion Labs may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Model. Sections 3, 4 and 5 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.
Log in or Sign Up to review the conditions and access this model content.

We introduce Tri-21B, our flagship large language model that redefines the efficiency frontier in LLM training. By achieving state-of-the-art performance with only 2.3T training tokens, we demonstrate that exceptional capabilities don't require excessive computational resources.
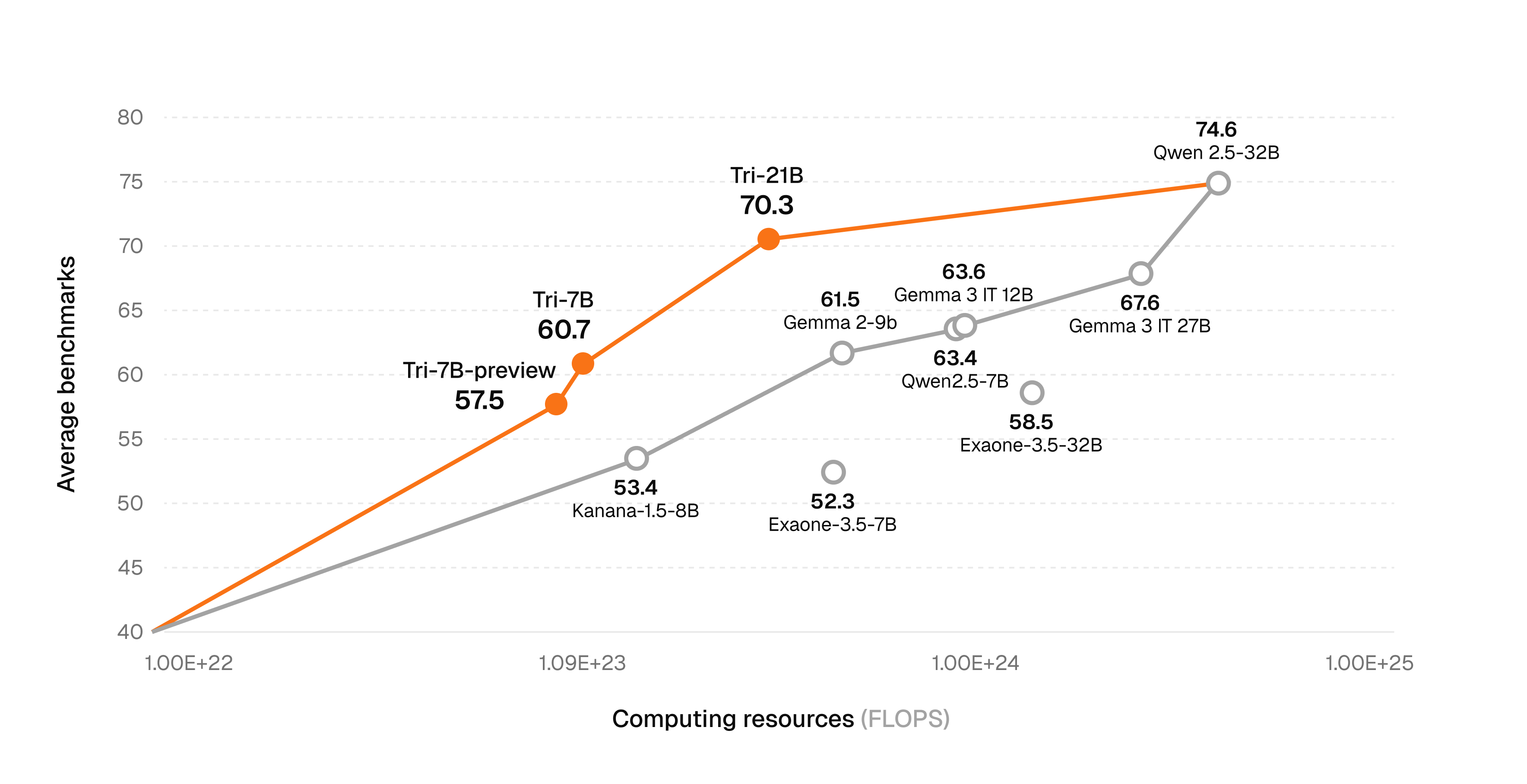
Our Tri-21B represents a paradigm shift in efficient model development. When comparing performance to training FLOPs, our model dramatically pushes the Pareto frontier—achieving performance comparable to or exceeding models like Qwen2.5-32B (74.6% at 3.46E+24 FLOPs) and Gemma 3 IT 27B (67.6% at 2.27E+24 FLOPs) while using approximately 8-12x fewer computational resources.
Our approach to training efficiency sets new benchmarks in the field. The following comparison demonstrates how Tri-21B achieves superior performance per FLOP compared to other state-of-the-art models of similar scale:
| Model | FLOPs | Avg. Accuracy¹ | Efficiency Ratio² |
|---|---|---|---|
| Tri-21B | 2.95E+23 | 70.3% | 1.00x (baseline) |
| Gemma2-9b | 4.42E+23 | 61.5% | 0.48x |
| Qwen2.5-7B | 8.22E+23 | 63.4% | 0.29x |
| Exaone-3.5-32B | 1.25E+24 | 58.5% | 0.19x |
| Gemma 3 IT 27B | 2.27E+24 | 67.6% | 0.11x |
| Qwen2.5-32B | 3.46E+24 | 74.6% | 0.10x |
| Qwen3-32B | 5.77E+24 | 73.5% | 0.06x |
¹ Average of MMLU / KMMLU / Global MMLU (ja)
² Performance per FLOP relative to Tri-21B
This efficiency breakthrough enables organizations to deploy state-of-the-art language models without the traditional computational barriers, democratizing access to advanced AI capabilities.
Here is a code snippet with apply_chat_template that demonstrates how to load the tokenizer and model and generate text.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "trillionlabs/Tri-21B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Explain the concept of quantum computing in simple terms."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
Tri-21B is also available with vLLM and SGLang!
# vLLM
vllm serve trillionlabs/Tri-21B --dtype bfloat16 --max-model-len 8192
# vLLM with custom options
vllm serve trillionlabs/Tri-21B \
--dtype bfloat16 \
--max-model-len 8192 \
--gpu-memory-utilization 0.95 \
--port 8000
# SGLang
python3 -m sglang.launch_server --model-path trillionlabs/Tri-21B --dtype bfloat16
# SGLang with custom options
python3 -m sglang.launch_server \
--model-path trillionlabs/Tri-21B \
--dtype bfloat16 \
--context-length 8192 \
--port 30000 \
--host 0.0.0.0
We evaluated Tri-21B across a comprehensive suite of benchmarks assessing general reasoning, knowledge recall, coding abilities, mathematical reasoning, and instruction-following capabilities. We compare our model against state-of-the-art models of similar scale: Gemmma-3-IT-27B and Qwen3-32B to demonstrate its competitive performance.
| Benchmark | Language | Evaluation Setting | Metric |
|---|---|---|---|
| General Reasoning and Factuality | |||
| • HellaSwag | English | 0-shot | accuracy |
| • ARC:C | English | 0-shot | accuracy |
| • HAERAE | Korean | 3-shot | accuracy |
| • CLIcK | Korean | 0-shot | accuracy |
| • KoBEST | Korean | 5-shot | accuracy |
| Knowledge and Reasoning | |||
| • KMMLU | Korean | 5-shot (0-shot, CoT) | accuracy (exact-match) |
| • MMLU | English | 5-shot (0-shot, CoT) | accuracy (exact-match) |
| • MMLU-Pro | English | 0-shot, CoT | exact-match |
| • Global-MMLU-Lite-ja | Japaneses | 5-shot | accuracy |
| Coding | |||
| • HumanEval | English | 0-shot | pass@1 |
| • MBPPPlus | English | 0-shot | pass@1 |
| Mathematical Reasoning | |||
| • GSM8k | English | 0-shot, CoT | exact-match |
| • MATH | English | 0-shot, CoT | exact-match |
| • GPQA | English | 4-shot | accuracy |
| • GPQA Diamond | English | 0-shot, CoT | accuracy |
| • HRM8k | Korean | 0-shot, CoT | exact-match |
| Instruction Following and Chat | |||
| • IFEval | English | 0-shot | strict-average |
| • koIFEval | Korean | 0-shot | strict-average |
| • MT-Bench | English | LLM-as-a-judge (gpt-4o) | LLM score |
| • KO-MT-Bench | Korean | LLM-as-a-judge (gpt-4o) | LLM score |
| • systemIFEval | English | 0-shot | strict-average |
Models compared:
| Benchmark | Tri-21B | Qwen3-32B | Gemma3-IT-27B |
|---|---|---|---|
| HAERAE | 86.16 | 71.67 | 78.09 |
| KoBEST | 85.92 | 83.39 | 87.66 |
| CLIcK | 72.32 | 66.89 | 67.54 |
| KMMLU | 61.89 (69.90) | 61.73 (67.55) | 55.03 (60.61) |
| MMLU | 77.62 (85.02) | 81.86 (84.46) | 77.42 (84.09) |
| MMLU-Pro | 64.74 | 70.53 | 64.26 |
| Global-MMLU-Lite-ja | 70.25 | 77.00 | 72.00 |
| Benchmark | Tri-21B | Qwen3-32B | Gemma3-IT-27B |
|---|---|---|---|
| HumanEval | 75.61 | 74.39 | 87.80 |
| MBPPPlus | 73.02 | 74.40 | 84.92 |
| Benchmark | Tri-21B | Qwen3-32B | Gemma3-IT-27B |
|---|---|---|---|
| GSM8k | 87.95 | 86.66 | 90.52 |
| MATH | 77.60 | 81.40 | 85.00 |
| GPQA | 39.73 | 41.07 | 37.95 |
| GPQA-Diamond | 44.95 | 54.04 | 44.44 |
| HRM8k | 56.70 | 66.24 | 63.90 |
| Benchmark | Tri-21B | Qwen3-32B | Gemma3-IT-27B |
|---|---|---|---|
| IFEval | 80.75 | 86.08 | 80.78 |
| koIFEval | 66.51 | 62.93 | 69.24 |
| MT-Bench | 8.21 | 8.52 | 8.53 |
| KO-MT-Bench | 7.79 | 8.47 | 8.46 |
| systemIFEval | 77.40 | 77.92 | 77.94 |
The following table shows the performance of Tri-21B base model (before instruction tuning) on key benchmarks:
| Benchmark | Tri-21B Base |
|---|---|
| MMLU | 76.99 |
| KMMLU | 62.37 |
| KoBEST | 85.07 |
| BBH | 77.19 |
| GSM8K | 70.36 |
| MBPPPlus | 75.40 |
This model repository is licensed under the Trillion License.
For inquiries, please contact: [email protected]