
FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL
Hang Zhao2, Juncheng Li1†, Siliang Tang1, Yueting Zhuang1
1Zhejiang University, 2Ant Group
*Equal Contribution, †Corresponding Authors

🚀 Overview
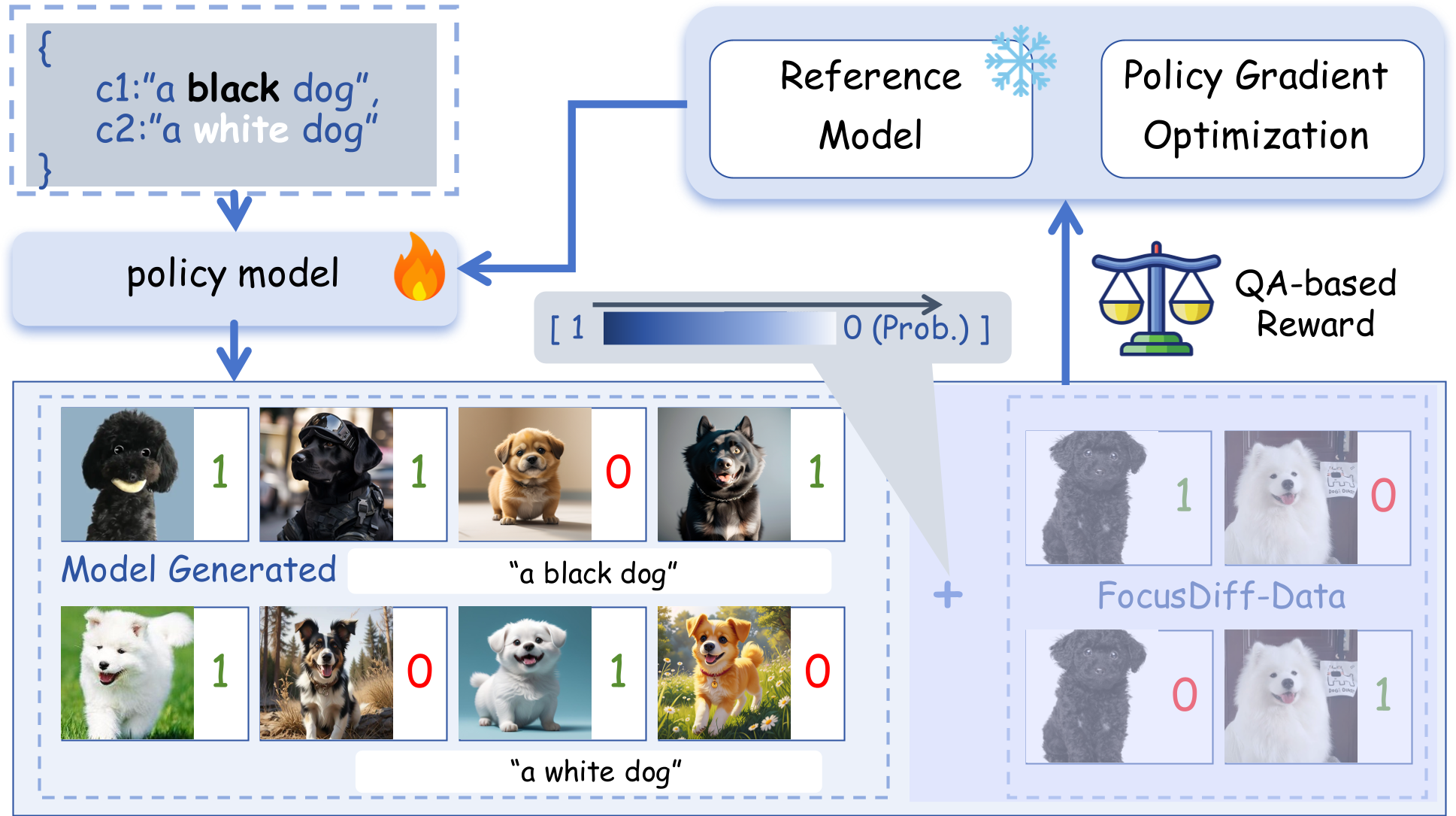
FocusDiff is a new method for improving fine-grained text-image alignment in autoregressive text-to-image models. By introducing the FocusDiff-Data dataset and a novel Pair-GRPO reinforcement learning framework, we help models learn subtle semantic differences between similar text-image pairs. Based on paired data in FocusDiff-Data, we further introduce the PairComp Benchmark, which focuses on subtle semantic differences.
Key Contributions:
PairComp Benchmark: A new benchmark focusing on fine-grained differences in text prompts.

FocusDiff Approach: A method using paired data and reinforcement learning to enhance fine-grained text-image alignment.
SOTA Results: Our model is evaluated with the top performance on multiple benchmarks including GenEval, T2I-CompBench, DPG-Bench, and our newly proposed PairComp benchmark.
✨️ Quickstart
1. Prepare Environment
We recommend using Python 3.10 and setting up a virtual environment:
# clone our repo
git clone https://github.com/wendell0218/FocusDiff.git
cd FocusDiff
# prepare python environment
conda create -n focus-diff python=3.10
conda activate focus-diff
pip install -r requirements.txt
2. Prepare Pretrained Model
FocusDiff utilizes Janus-Pro-7B as the pretrained model for subsequent supervised fine-tuning. You can download the corresponding model using the following command:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/Janus-Pro-7B
cd Janus-Pro-7B
git lfs pull
3. Start Generating!
import os
import torch
import PIL.Image
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1.0,
parallel_size: int = 4,
cfg_weight: float = 5.0,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
img_top_k: int = 1,
img_top_p: float = 1.0,
):
images = []
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
if img_top_k:
v, _ = torch.topk(logits, min(img_top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = float("-inf")
probs = torch.softmax(logits / temperature, dim=-1)
if img_top_p:
probs_sort, probs_idx = torch.sort(probs,
dim=-1,
descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > img_top_p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
else:
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
for i in range(parallel_size):
images.append(PIL.Image.fromarray(visual_img[i]))
return images
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--model_path", type=str, default="deepseek-ai/Janus-Pro-7B")
parser.add_argument("--ckpt_path", type=str, default=None)
parser.add_argument("--caption", type=str, default="a brown giraffe and a white stop sign")
parser.add_argument("--gen_path", type=str, default='results/samples')
parser.add_argument("--cfg", type=float, default=5.0)
parser.add_argument("--parallel_size", type=int, default=4)
args = parser.parse_args()
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(args.model_path)
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(args.model_path, trust_remote_code=True)
if args.ckpt_path is not None:
state_dict = torch.load(f"{args.ckpt_path}", map_location="cpu")
vl_gpt.load_state_dict(state_dict)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
prompt = f'<|User|>: {args.caption}\n\n<|Assistant|>:<begin_of_image>'
images = generate(
vl_gpt,
vl_chat_processor,
prompt,
parallel_size = args.parallel_size,
cfg_weight = args.cfg,
)
if not os.path.exists(args.gen_path):
os.makedirs(args.gen_path, exist_ok=True)
for i in range(args.parallel_size):
img_name = str(i).zfill(4)+".png"
save_path = os.path.join(args.gen_path, img_name)
images[i].save(save_path)
🤝 Acknowledgment
Our project is developed based on the following repositories:
- Janus-Series: Unified Multimodal Understanding and Generation Models
- Open-R1: Fully open reproduction of DeepSeek-R1
📜 Citation
If you find this work useful for your research, please cite our paper and star our git repo:
@article{pan2025focusdiff,
title={FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL},
author={Pan, Kaihang and Bu, Wendong and Wu, Yuruo and Wu, Yang and Shen, Kai and Li, Yunfei and Zhao, Hang and Li, Juncheng and Tang, Siliang and Zhuang, Yueting},
journal={arXiv preprint arXiv:2506.05501},
year={2025}
}
- Downloads last month
- 3