
CLIP-KO: Knocking Out Typographic Attacks in CLIP 💪🤖
Finally, a CLIP ViT-L/14@336 without a 'text obsession'! 🤗
❤️ this CLIP? Donate if you can / want. TY!
- 📝 Read the paper (PDF) here.
- 🖼️ Download The Text Encoder for generative AI
- 🤓 Wanna fine-tune yourself? Get the code on my GitHub.
👉 CLICK ME to expand example benchmark code ⚡💻
from datasets import load_dataset
from transformers import CLIPModel, CLIPProcessor
import torch
from PIL import Image
from tqdm import tqdm
import pandas as pd
device = "cuda" if torch.cuda.is_available() else "cpu"
# BLISS / SCAM Typographic Attack Dataset
# https://huggingface.co/datasets/BLISS-e-V/SCAM
ds = load_dataset("BLISS-e-V/SCAM", split="train")
# Benchmark pre-trained model against my fine-tune
model_variants = [
("OpenAI ", "openai/clip-vit-large-patch14-336", "openai/clip-vit-large-patch14-336"),
("KO-CLIP", "zer0int/CLIP-KO-ViT-L-14-336-TypoAttack", "zer0int/CLIP-KO-ViT-L-14-336-TypoAttack"),
]
models = {}
for name, model_path, processor_path in model_variants:
model = CLIPModel.from_pretrained(model_path).to(device).float()
processor = CLIPProcessor.from_pretrained(processor_path)
models[name] = (model, processor)
for variant in ["NoSCAM", "SCAM", "SynthSCAM"]:
print(f"\n=== Evaluating var.: {variant} ===")
idxs = [i for i, v in enumerate(ds['id']) if v.startswith(variant)]
if not idxs:
print(f" No samples for {variant}")
continue
subset = [ds[i] for i in idxs]
for model_name, (model, processor) in models.items():
results = []
for entry in tqdm(subset, desc=f"{model_name}", ncols=30, bar_format="{l_bar}{bar}| {n_fmt}/{total_fmt} |"):
img = entry['image']
object_label = entry['object_label']
attack_word = entry['attack_word']
texts = [f"a photo of a {object_label}", f"a photo of a {attack_word}"]
inputs = processor(
text=texts,
images=img,
return_tensors="pt",
padding=True
)
for k in inputs:
if isinstance(inputs[k], torch.Tensor):
inputs[k] = inputs[k].to(device)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
logits = image_features @ text_features.T
probs = logits.softmax(dim=-1).cpu().numpy().flatten()
pred_idx = probs.argmax()
pred_label = [object_label, attack_word][pred_idx]
is_correct = (pred_label == object_label)
results.append({
"id": entry['id'],
"object_label": object_label,
"attack_word": attack_word,
"pred_label": pred_label,
"is_correct": is_correct,
"type": entry['type'],
"model": model_name
})
n_total = len(results)
n_correct = sum(r['is_correct'] for r in results)
acc = n_correct / n_total if n_total else float('nan')
print(f"| > > > > Zero-shot accuracy for {variant}, {model_name}: {n_correct}/{n_total} = {acc:.4f}")
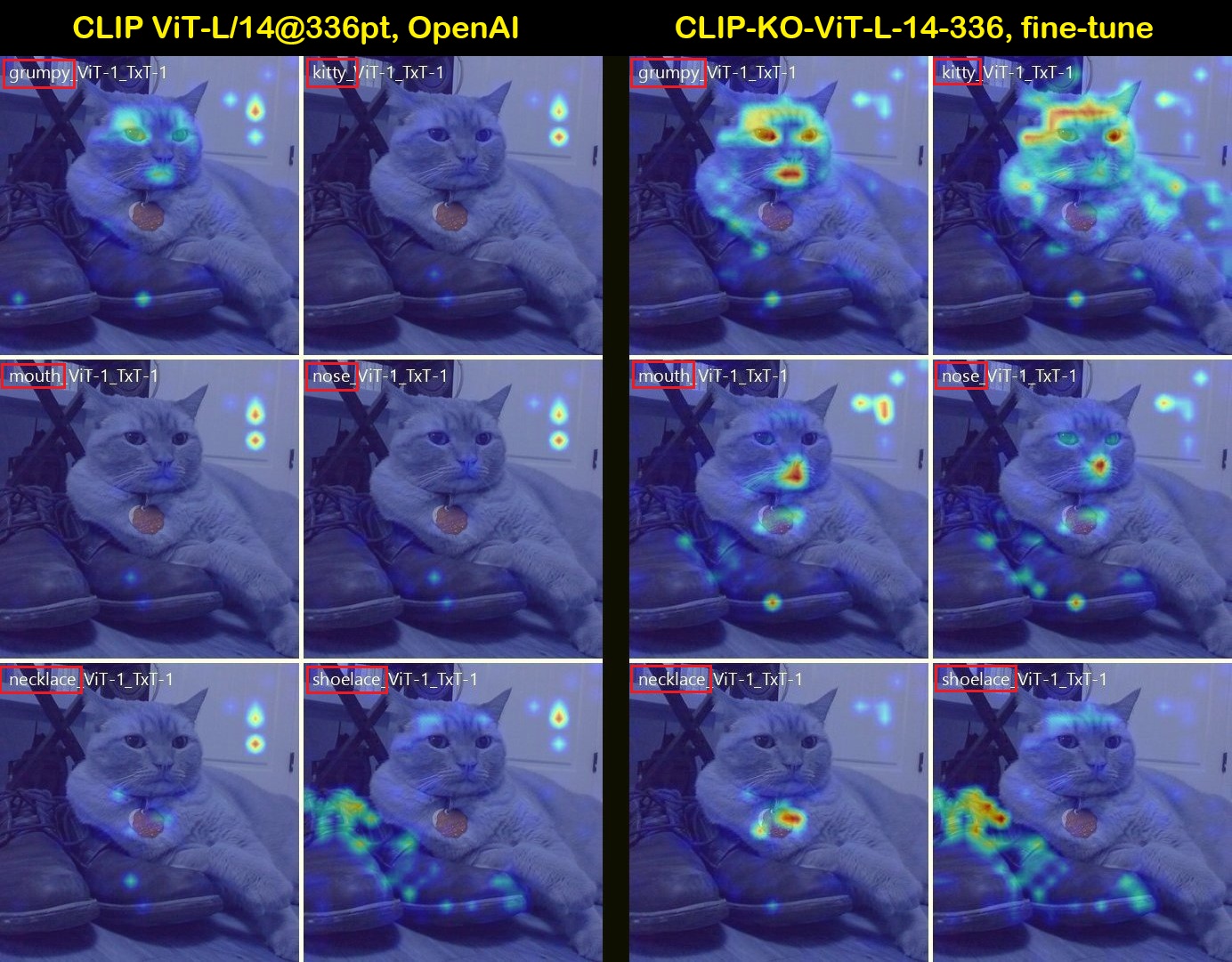
Interpretable Attention Heatmaps:
🔥 Example Images generated with Flux.1-dev:


📊 Benchmark Results 🚀
| Benchmark / Model: | pretrained | finetuned |
|---|---|---|
| Typographic Attack | ||
| RTA-100 | ||
| zero-shot acc | 0.4660 | 0.6480🎖️ |
| BLISS-SCAM | ||
| NoSCAM acc | 0.9914 | 0.9905 |
| SCAM acc | 0.4208 | 0.7134🎖️ |
| SynthSCAM acc | 0.3554 | 0.6893🎖️ |
| LAION/CLIP_Benchmark | ||
| VoC-2007-multilabel | ||
| mAP | 0.7789 | 0.8738🎖️ |
| MSCOCO retrieval | ||
| image retr recall@5 | 0.2260 | 0.3574 |
| text retr recall@5 | 0.3199 | 0.5135🎖️ |
| xm3600 retrieval | ||
| image retr recall@5 | 0.3120 | 0.4554 |
| text retr recall@5 | 0.2487 | 0.4467 |
| ImageNet-1k | ||
| zero-shot acc-1 | 0.3557 | 0.4966 |
| zero-shot acc-5 | 0.5586 | 0.7108🎖️ |
| mAP | 0.3546 | 0.4950 |
| MISC | ||
| ImageNet-1k | ||
| linear probe Top-1 | 73.27% | 74.96% |
| linear probe Top-5 | 93.73% | 94.91% |
| MVT ImageNet/ObjectNet | 0.8512 | 0.9083🎖️ |
| zero-shot acc | ||
| Flickr8k | ||
| Modality Gap: ↓ | 0.8322 | 0.8216 |
| JSD: ↓ | 0.4951 | 0.1537 |
| Wasserstein Distance: ↓ | 0.4103 | 0.3902 |
| Image-Text Cos Sim (mean): ↑ | 0.2803 | 0.3097 |
| Image-Text Cos Sim (std): | 0.0357 | 0.0564 |
| Text-Text Cos Sim (mean): | 0.6906 | 0.6998 |
| Text-Text Cos Sim (std): | 0.1317 | 0.1440 |
- Downloads last month
- 11
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
Model tree for zer0int/CLIP-KO-ViT-L-14-336-TypoAttack
Base model
openai/clip-vit-large-patch14-336