
chrisyrniu/mxt
Robotics
•
Updated
video
video |
|---|
![]()
Yaru Niu1,*
Yunzhe Zhang1,*
Mingyang Yu1
Changyi Lin1
Chenhao Li1
Yikai Wang1
Yuxiang Yang2
Wenhao Yu2
Tingnan Zhang2
Zhenzhen Li3
Jonathan Francis1,3
Bingqing Chen3
Jie Tan2
Ding Zhao1
1Carnegie Mellon University
2Google DeepMind
3Bosch Center for AI
*Equal contributions
Robotics: Science and Systems (RSS) 2025
Website |
Paper |
Code
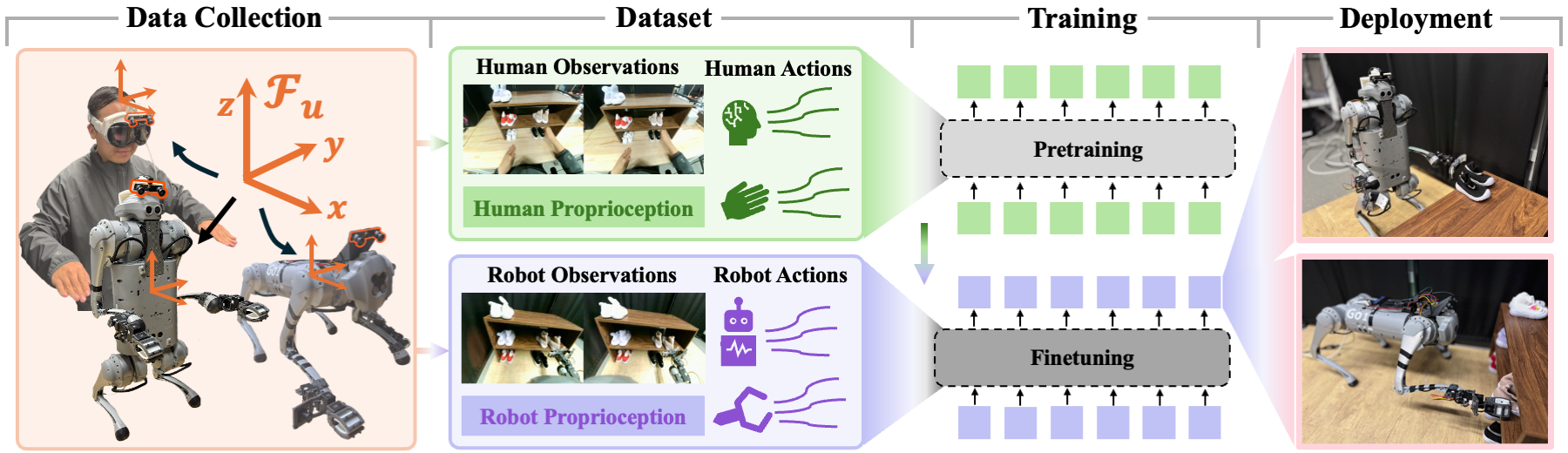
This dataset includes both human and LocoMan robot data for six manipulation tasks featured in our work: unimanual toy collection, bimanual toy collection, unimanual shoe organization, bimanual shoe organization, unimanual scooping, and bimanual pouring.
The human and robot data share a unified format and are stored in HDF5 files with the same structure as follows. The accompanying MP4 video files are provided for reference only.
root
├── observations
│ ├── images
│ │ ├─ main # images from main camera: [h * w * c] * traj_length
│ │ └─ wrist # images from wrist cameras (at most two, right first): [h * w * c] * traj_length
│ └── proprioceptions
│ ├─ body # 6d pose of the rigid body where the main camera is mounted: [6] * traj_length
│ ├─ eef # 6d pose of the end effectors (at most two, right first): [12] * traj_length
│ ├─ relative # relative 6d pose of the end effector to the rigid body where the main camera is mounted (at most two, right first): [12] * traj_length
│ ├─ gripper # gripper angle (at most two, right first): [2] * traj_length
│ └─ other # other prorioceptive state, e.g., robot joint positions, robot joint velocities, human hand joint poses, ...
├── actions
│ ├── body # 6d pose of the rigid body where the main camera is mounted: [6] * traj_length
│ ├── delta_body # delta 6d pose of the rigid body where the main camera is mounted: [6] * traj_length
│ ├── eef # 6d pose of the end effectors (at most two, right first): [12] * traj_length
│ ├── delta_eef # delta 6d pose of the end effectors (at most two, right first): [12] * traj_length
│ ├── gripper # gripper angle (at most two, right first): [2] * traj_length
│ └── delta_gripper # delta gripper angle (at most two, right first): [2] * traj_length
└── masks # embodiment-specific masks to mask out observations and actions for training and inference (the mask for observations and actions of the same modality could be different)
├── img_main # mask for the main camera image input: [1]
├── img_wrist # mask for the wrist camera image input: [2]
├── proprio_body # mask for the body 6d pose input: [6]
├── proprio_eef # mask for the eef 6d pose input: [12]
├── proprio_gripper # mask for the gripper angle input: [2]
├── proprio_other # mask for other proprioception input (n components): [n]
├── act_body # mask for the body 6d pose output: [6]
├── act_eef # mask for the eef 6d pose output: [12]
└── act_gripper # mask for the gripper angle output: [2]
If you find this work helpful, please consider citing the paper:
@inproceedings{niu2025human2locoman,
title={Human2LocoMan: Learning Versatile Quadrupedal Manipulation with Human Pretraining},
author={Niu, Yaru and Zhang, Yunzhe and Yu, Mingyang and Lin, Changyi and Li, Chenhao and Wang, Yikai and Yang, Yuxiang and Yu, Wenhao and Zhang, Tingnan and Li, Zhenzhen and Francis, Jonathan and Chen, Bingqing and Tan, Jie and Zhao, Ding},
booktitle={Robotics: Science and Systems (RSS)},
year={2025}
}